
基於BeautifulSoup的Python3實戰:四周實現爬蟲系統筆記
章節1 第零周:開始之前
勤快寫,多動手,不浮躁,堅持堅持堅持。-----慢慢來,做完美
科學上網 好的IDE 工具 理解 模仿 實戰
畫流程圖,新增異常處理
幾種爬蟲比較
- urllib+正則:無第三方依賴
- requests+BeautifulSoup:library
- scrapy:框架
從上往下抽象程度增加,方便程度增加。“路怎麼走,自己選。”
bs4官網基礎知識
tag中包含多個字串 ,可以使用 .strings 來迴圈獲取
.stripped_strings 可以去除多餘空白內容
1、prettify() 方法將Beautiful Soup的文件樹格式化後以Unicode編碼輸出,每個XML/HTML標籤都獨佔一行
2、想得到tag中包含的文字內容,那麼可以用 get_text() 方法,這個方法獲取到tag中包含的所有文版內容包括子孫tag中的內容,並將結果作為Unicode字串返回
3、使用Beautiful Soup解析後,文件都被轉換成了Unicode
4、通過Beautiful Soup輸出文件時,不管輸入文件是什麼編碼方式,輸出編碼均為UTF-8編碼
對計算時間要求很高或者計算機的時間比程式設計師的時間更值錢,那麼就應該直接使用 lxml .
章節2 第一週:學會爬取網頁資訊
網頁的構成 結構,樣式,文件樹,各種層級標籤(唯一定位即可)
本地網頁:
1、BeautifulSoup解析網頁,類似css選擇器,能在文件樹裡標識唯一位置
2、找到正確元素,審查元素 定位
3、處理標籤文字,釋放元素 篩選
from bs4 import BeautifulSoup path = './1_2_homework_required/index.html' #這裡使用了相對路徑,只要你本地有這個檔案就能開啟 with open(path, 'r') as wb_data: # 使用with open開啟本地檔案,自帶檢測,不需要關閉 Soup = BeautifulSoup(wb_data, 'lxml') # 解析網頁內容,lxmlb比較快 titles = Soup.select('div.caption > h4 > a') # 複製每個元素的css selector 路徑即可 stars = Soup.select('div.col-md-9 > div > div > div > div.ratings > p:nth-of-type(2)') # 為了從父節點開始取,此處保留:nth-of-type(2),觀察網頁,多取幾個星星的selector,就發現規律了
for title, image, star in zip(titles, images, stars): # 使用for迴圈,把每個元素裝到字典中,方便查詢
data = {
'title': title.get_text(), # 使用get_text()方法取出文字
'image': image.get('src'), # 使用get方法取出帶有src的圖片連結
'star': len(star.find_all("span", class_='glyphicon glyphicon-star'))
# 觀察發現,每一個星星會有一次<span class="glyphicon glyphicon-star"></span>,所以我們統計有多少次
# 使用find_all 統計有幾處是★的樣式,第一個引數定位標籤名,第二個引數定位css 樣式,具體可以參考BeautifulSoup
# 由於find_all()返回的結果是列表,我們再使用len()方法去計算列表中的元素個數,也就是星星的數量
}
print(data)
----------------------------
print(1,2,3,sep='\n--------\n')
'''
1
--------
2
--------
3
'''title可以去頭部標籤裡面取,更快
address = soup.select('div.pho_info > p')[0].get('title') # 和 get('href')通過屬性取值
cates = Soup.select('div.article-info > p.meta-info') #解析多子標籤,返回列表
'cate': list(cates.stripped_strings)
#Object.stripped_strings【父集下面所有子標籤的文字資訊(聚合資訊)】 高階版本get_text()外網解:requests+Beautifulsoup
1、伺服器與本地交換機制 http協議,Request請求八種get,post 。Response迴應,返回狀態碼
2、選擇,大範圍,利用屬性縮小範圍。# a[target='_blank']' 屬性選擇縮小範圍
3、cookies偽造登入資訊,headers
4、獲取多頁,定義函式,找每一頁連結規律,列表解析式,反扒加入時間延時模組,大型網站換IP,模擬難搞的用手機頁面偽造,簡單。
#str(i)表示變數
urls = ['http://www.mm131.com/xinggan/3520_{}.html'.format(str(i)) for i in range(1,23,1)]
for single_url in urls:
get_attractions(single_url) #遍歷列表並執行,保護反扒增加延時
-------------------------------------------
#另外一種,傳遞引數
def get_page_link(page_number):
for each_number in range(1,page_number): # 每頁24個連結,這裡輸入的是頁碼
full_url = 'http://bj.xiaozhu.com/search-duanzufang-p{}-0/'.format(each_number)
wb_data = requests.get(full_url)5、登入爬取,使用cookies。扒手機頁面
6、動態(非同步)載入,去network找連結規律,xhr下滑幾頁。
字典和列表,都是可變,一般用data=None保證資料安全。
from bs4 import BeautifulSoup
import requests
import time
url = 'https://knewone.com/discover?page='
def get_page(url,data=None):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
imgs = soup.select('a.cover-inner > img')
links = soup.select('section.content > h4 > a')
if data==None:
for img,title,link in zip(imgs,titles,links):
data = {
'img':img.get('src'),
'link':link.get('href')
}
print(data) #資料被汙染,從新使用置為None
def get_more_pages(start,end):
for one in range(start,end):
get_page(url+str(one))
time.sleep(2) #暫停保護
get_more_pages(1,2)實戰:58同城二手平板
設計工作流,分析頁面,分析詳情……
第一步:得到urls連結
巧用:id = url.split('/')[-1].strip('x.shtml')
構造字典可以這樣:
'cate' : '個人' if who_sells == 0 else '商家' #列表解析式
404檢測:if wb_data.status_code == 404:
核心程式碼
-----------config.py--------------------
import pymongo
client = pymongo.MongoClient('localhost', 27017)
tongcheng = client['ceshi']
url_list = tongcheng['url_list4']
item_info = tongcheng['item_info4']
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/52.0.2743.116 Safari/537.36 Edge/15.15063'}
-------------引數傳遞---------------------------
def get_links_from(channel, pages, who_sells='o'):
# http://bj.ganji.com/ershoubijibendiannao/o3/
list_view = '{}{}{}/'.format(channel, str(who_sells), str(pages))
-----------多程序------------------------
def get_all_links_from(channel): #新增引數
for i in range(1,100):
get_links_from(channel,i)
if __name__ == '__main__':
pool = Pool()
# pool = Pool(processes=6)
pool.map(get_all_links_from,channel_list.split()) #map裡面函式沒括號
------------資料庫計數---------------------
import time
from pages_parsing import url_list #匯入資料庫
while True:
print(url_list.find().count())
time.sleep(5)
--------------斷點續傳,集合去重-------------
db_urls = [item['url'] for item in url_list.find()]
index_urls = [item['url'] for item in item_info.find()]
x = set(db_urls)
y = set(index_urls)
rest_of_urls = x-y
章節3 第二週:學會爬取大規模資料
Mongdb類似Excel,可見即可得工具,Mongo Explore外掛
命名小心關鍵字啊!!!
爬取大規模大資料流程:
思路最重要
1、觀察頁面特徵(不同使用者商家男女),編寫通用程式
2、設計工作流程 爬蟲一得到列表頁url,得到商品連結,爬蟲二得到詳情頁,得到每個商品詳情。各司其職。
3、一頁一頁向下面解析,不一定全符合規律,小心
代理及404判斷
wb_data = requests.get(list_view,headers=headers,proxies=proxies),偽造瀏覽器,代理ip
----------------------------------
if wb_data.status_code == 404:
pass
else:
soup = BeautifulSoup(wb_data.text, 'lxml')單程序,單程序單執行緒:單人單桌(僅一桌僅一人) 單程序多執行緒:多人單桌(一桌多人)
多程序單執行緒:單人多桌(每桌一人) 多程序多執行緒:吃喜酒(電腦得多核)
try函式:出錯繼續執行
def try_to_make(a_mess):
try:
print(1/a_mess)
except (ZeroDivisionError,TypeError): #錯誤程式碼放這
print('ok~')
try_to_make(10)太扯了,一爬就被封ip了,哎
趕集
'pub_date':soup.select('.pr-5')[0].text.strip().split(' ')[0],
# 複雜地區解析
'area':list(map(lambda x:x.text,soup.select('ul.det-infor > li:nth-of-type(3) > a'))),
---------------map函式-------------後面列表迭代
'cates':list(soup.select('ul.det-infor > li:nth-of-type(1) > span')[0].stripped_strings)
---------------字串--------------爬蟲加速:多核,lxml的xpath快10倍,非同步
用下一頁標籤判斷是否為最後頁
章節4 第三週:資料統計與分析
怎麼讓資料說話?
1、提出正確問題,正確解釋現象(不要結論去驗證假設),正確驗證假設,倖存者偏差,對比(別人,以前)
2、資料論證,細分,因果關聯(腦圖,excel)
3、解讀資料,資料會說話,資料會說謊,樣本偏差
整理清洗資料(刪除不要的,整理美觀變成我們需要的,重新寫入資料庫或生成器)
更新資料庫
資料視覺化
工具 esc+m 切換模式 tab補全 shift+enter執行程式碼
MongoDB匯入資料json,安裝charts庫 開始匯入json格式的檔案:注意是在CMD目錄下, 而不是在客戶端shell執行mongoimport命令 shift+回車,執行程式碼
# 匯入資料須知
1. 首先執行 mongo shell在資料庫中建立一個 collection —— db.createCollection('your_name')
2. 接下來直接在終端/命令列(cmd)中使用命令匯入 json 格式的資料 —— mongoimport -d database_name
-c collection_name path/file_name.json
eg: cmd後直接執行
—— mongoimport -d ceshi -c beijing C:\Users\Administrator\Desktop\fourpython原始碼\week3\week3_homework\data_sample/sample.json
備份要去bin目錄下面
資料邊篩選邊顯示(Highcharts),分析
1、條形圖 發帖量
#資料處理
for i in item_info.find():
if i['area']:
area = [i for i in i['area'] if i not in punctuation] #非字串的列表解析
else:
area = ['不明']
item_info.update({'_id':i['_id']},{'$set':{'area':area}}) #更新
-----------------------------------
#列表變集合去重
arealist=[]
for i in item_info.find(): #全部遍歷
# print(i['area'])
arealist.append(i['area'][0])
#列表轉集合,遍歷完成之後
area_index = list(set(arealist)) #去集合重然後再轉為列表
print(area_index)
------------------------------------
#統計次數,結合取出的
area_times=[]
for item in area_index:
area_times.append(arealist.count(item)) #list.count(a) 統計a出現的次數
print(area_times)
妙用生成器,比for快多了
def data_gen(types):
length = 0
if length <= len(area_index):
for area,times in zip(area_index,post_times):
data = {
'name':area,
'data':[times],
'type':types
}
yield data
length += 1
---------------------------------
series = [data for data in data_gen('column')]
2、折線圖 n日內發帖曲線
find函式精確查詢資料,強大,不會改變原始資料,具體分片後所有端會顯示
-----------日期篩選,地區篩選--------------
for i in item_info.find({'pub_date':{'$in':['2016.01.12','2016.01.14']}},{'area':{'$slice':1},'_id':0,'price':0,'title':0}).limit(300):
print(i)1、資料處理
{'pub_date': '2016.01.02'}
{'pub_date': '2016-01-12'}
-----------換成.-------------
for i in item_info.find():
frags = i['pub_date'].split('-') #有-就分割成列表
if len(frags) == 1: #本來就是.的
date = frags[0]
else:
date = '{}.{}.{}'.format(frags[0],frags[1],frags[2])
item_info.update_one({'_id':i['_id']},{'$set':{'pub_date':date}})2、讓程式明白時間段,獲取單日日期
a = date(2015,5,10)
print(a) #2015-05-10
-----------------
d = timedelta(days=1) #加減
print(d) #1 day, 0:00:00def get_all_dates(date1,date2): #開始及結束時間
the_date = date(int(date1.split('.')[0]),int(date1.split('.')[1]),int(date1.split('.')[2]))
end_date = date(int(date2.split('.')[0]),int(date2.split('.')[1]),int(date2.split('.')[2]))
days = timedelta(days=1) #程式計算時間的
while the_date <= end_date:
yield (the_date.strftime('%Y.%m.%d')) #時間格式化
the_date = the_date + days
---------------------------------------
for i in get_all_dates('2015.12.24','2016.01.05'):
print(i)
---------------------------------------
2015.12.24
2015.12.25
2015.12.26
2015.12.27
2015.12.28日期生成器構造
def get_data_within(date1,date2,areas): #地區是傳入列表引數
for area in areas: #獲取所有地區迴圈
area_day_posts = []
for date in get_all_dates(date1,date2):
a = list(item_info.find({'pub_date':date,'area':area}))
each_day_post = len(a) #每天發帖量
area_day_posts.append(each_day_post) #裝入列表
data = {
'name': area,
'data': area_day_posts,
'type': 'line'
}
yield data
-------------繪圖--------------------
options = {
'chart' : {'zoomType':'xy'},
'title' : {'text': '發帖量統計'},
'subtitle': {'text': '視覺化統計圖表'},
'xAxis' : {'categories': [i for i in get_all_dates('2015.12.24','2016.01.05')]},
'yAxis' : {'title': {'text': '數量'}}
}
series = [i for i in get_data_within('2015.12.24','2016.01.05',['朝陽','海淀','通州'])]
charts.plot(series, options=options,show='inline')
3、餅圖
聚合管道高效查詢,管道模型層次篩選,最後輸出資料(類似mysql的聚合函式)

已知 求解 所需資料結構
#強大的水管過濾,資料篩選
pipeline = [
{'$match':{'$and':[{'pub_date':'2015.12.24'},{'time':3}]}}, #匹配日期且(and)時間為3天
{'$group':{'_id':'$price','counts':{'$sum':1}}}, #按照price分組,效率高
{'$sort' :{'counts':-1}}, #以頻次分組,倒序排
{'$limit':10} #限制
]
# {'pub_date':'2015.12.24'}
--------------------------------------
for i in item_info.aggregate(pipeline): #呼叫
print(i)
-------------生成器--------------------
def data_gen(date,time):
pipeline = [
{'$match':{'$and':[{'pub_date':date},{'time':time}]}},
{'$group':{'_id':{'$slice':['$cates',2,1]},'counts':{'$sum':1}}},
{'$sort':{'counts':-1}}
]
for i in item_info.aggregate(pipeline):
yield [i['_id'][0],i['counts']]
--------------構造繪圖結果---------------
series = [{
'type': 'pie',
'name': 'pie charts',
'data':[i for i in data_gen('2016.01.10',1)]
}]
charts庫實際是對呼叫Highcharts API 進行封裝,通過python生成Highcharts指令碼
show = 'inline',如果沒有這個選項,會開啟新標籤頁面
可以在serie中指定color顏色,type顯示的形式(column:柱狀圖,bar:橫向柱狀圖,line:曲線,area:範圍,spline:曲線,scatter:點狀,pie:餅狀圖)
章節5 第四周:搭建 Django 資料視覺化網站
以前忽略了,這個需要重點學習
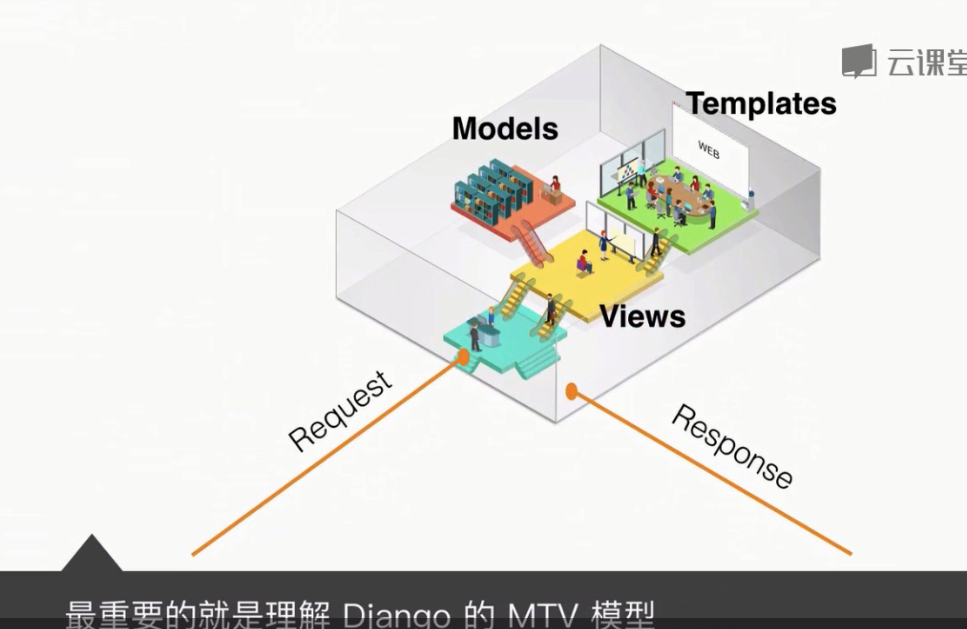
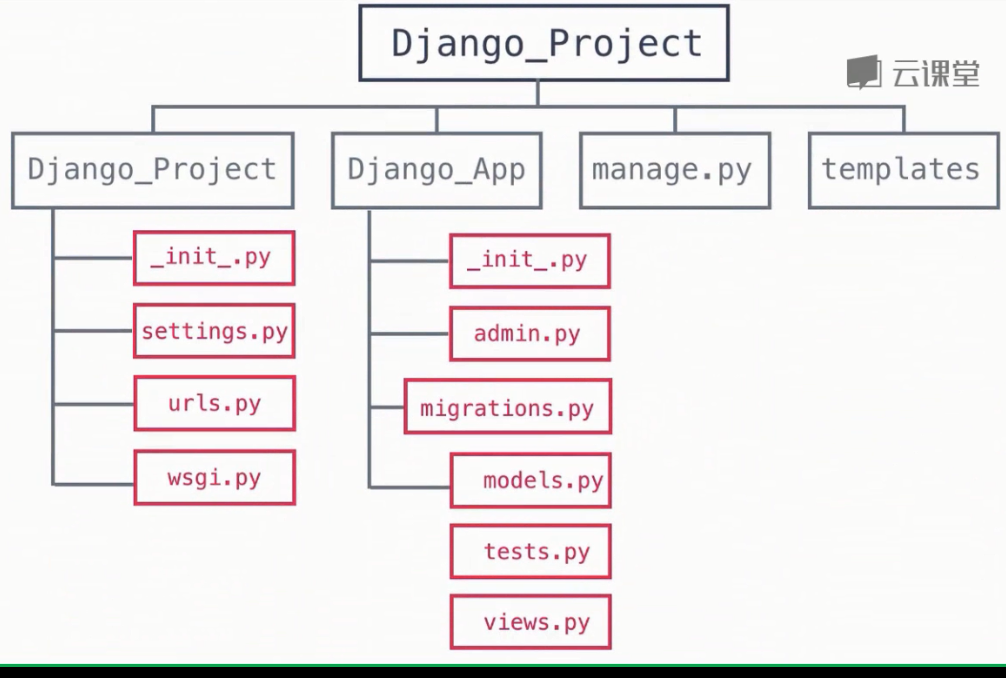
建立流程:
- 建立虛擬環境(pycharm)
- 建立專案
- 總設定裡面新增應用(app) python manage.py startapp django_web
- 新增模板,templates裡面建新檔案
- 在view裡面呼叫檢視函式
- urls裡面分配網址(正則模糊匹配),先引入庫
- 執行服務,python manage.py runserver,修改後重新啟動
- 訪問正確網址
- static檔案位置放對,根目錄,引用樣式,獲取靜態檔案,修改總設定 {% %}類似format函式
-
STATICFILES_DIRS=(os.path.join(BASE_DIR,'static'),) #絕對路徑加相對資料夾
模板語言:
- 理解上下文 render函式,模板填空content,content(字典結構)就是資料庫取出來替換,原文改造 {{ }}

- model,資料結構
- 分頁工具(資料分頁載入) ojects[:4] 每頁4條資料 Paginator
-
Semantic UI Gird佈局 ,jQuery生成圖表
- 模板繼承(繼承圖表),也是字典傳遞資料,view層寫以前圖表程式碼
-
pymongo來操作MongoDB資料庫,但是直接把對於資料庫的操作程式碼都寫在指令碼中,這會讓應用的程式碼耦合性太強,而且不利於程式碼的優化管理,一般應用都是使用MVC框架來設計的,為了更好地維持MVC結構,需要把資料庫操作部分作為model抽離出來,這就需要藉助MongoEngine
MongoEngine是一個物件文件對映器(ODM),相當於一個基於SQL的物件關係對映器(ORM),MongoEngine提供的抽象是基於類的,建立的所有模型都是類,說白了更簡單
靜態替換:{% %}, 資料庫取動態替換{{ }}


完結打卡!!!