
TensorFlow框架做實時人臉識別小專案(一)
人臉識別是深度學習最有價值也是最成熟的的應用之一。在研究環境下,人臉識別已經趕上甚至超過了人工識別的精度。一般來說,一個完整的人臉識別專案會包括兩大部分:人臉檢測與人臉識別。下面就我近期自己練習寫的一個“粗糙”的人臉識別小專案講起,也算是做一個學習記錄。
首先 ,整個專案的框架包括四個主要的部分:(1)利用opencv從影象感測器處(比如電腦攝像頭)實時的讀入視訊幀;(2)使用mtcnn網路做人臉檢測和對齊;(3)利用facenet網路計算人臉特徵,也就是embedding;(4)knn演算法進行具體的人臉識別。如下圖所示:

其中的mtcnn的人臉檢測是很關鍵的一步,它檢測定位的人臉準確與否直接影響到後面的特徵計算與識別;facenet實際是一個對人臉進行特徵編碼的網路,具體的實現後面會討論;knn的分類演算法在用於真正的識別前要經過訓練,訓練的樣本的質量好壞與數量也會對識別的 結果產生很大的影響。今天在這隻討論mtcnn網路的人臉檢測對齊部分。
mtcnn網路全稱為multi-task convolutinal neural network,意為多工卷積神經網路。mtcnn由三個神經網路組成,分別是P-Net, R-Net, O-Net。在使用這些網路之前,首先要將原始圖片縮放到不同尺寸,形成一個影象金字塔,接著會對每個尺寸的圖片通過神經網路計算一遍。其目的在於兼顧圖片中的不同大小的人臉,在統一的尺度下檢測人臉。
第一個網路P-Net的結構如下圖所示:
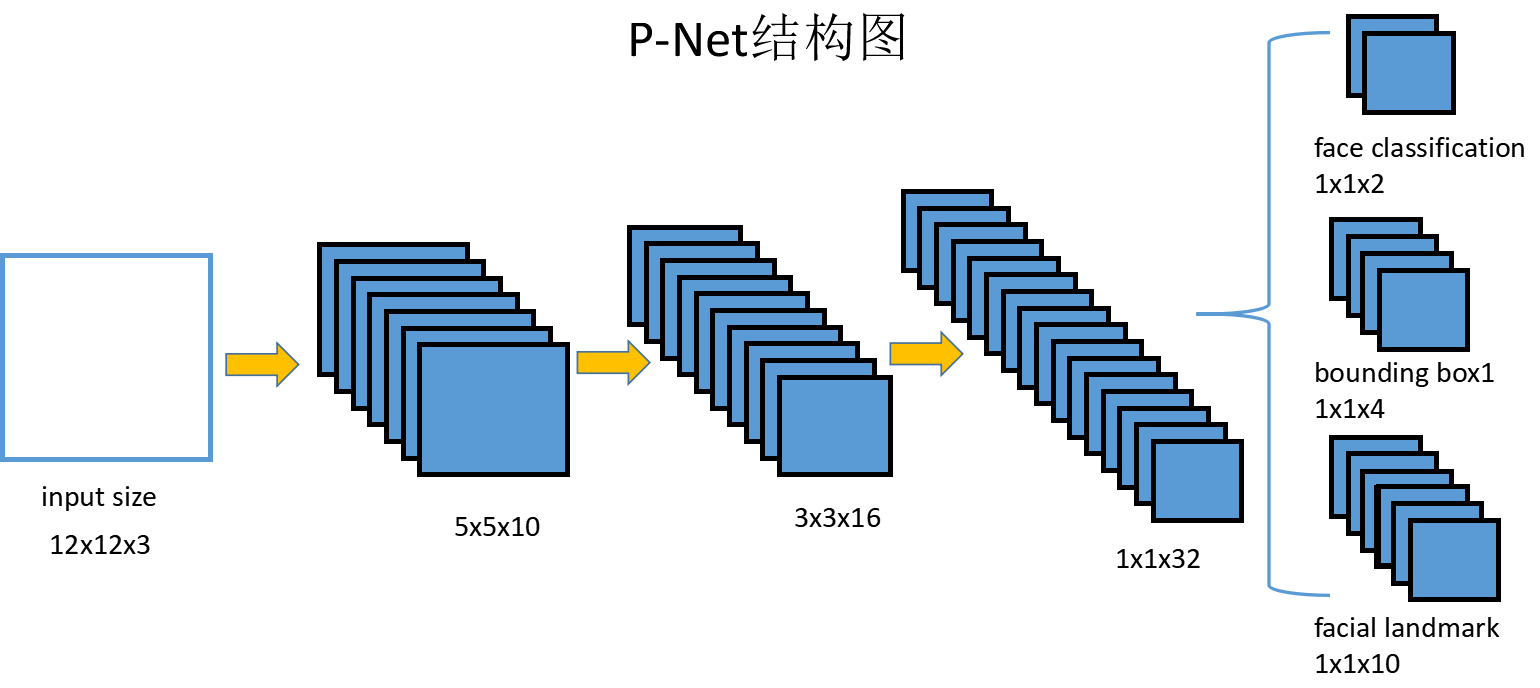
P-Net的輸入是一個12x12的3通道RGB影象,它的作用是要判斷這個網路中是否有人臉,並且給出人臉框和關鍵點位置。第一個部分face classification輸出的是判斷是人臉的概率和不是人臉的概率,兩個值加起來嚴格等於1;第二個部分輸出的是框的精確位置,4個值分別是框的左上角二維座標和框的高度與寬度;第三個部分輸出的是人臉5個關鍵點:左眼,右眼,鼻子,左嘴角,右嘴角的位置的二維座標。
第二個網路R-Net的網路結構與P-Net差別不大,如下圖:
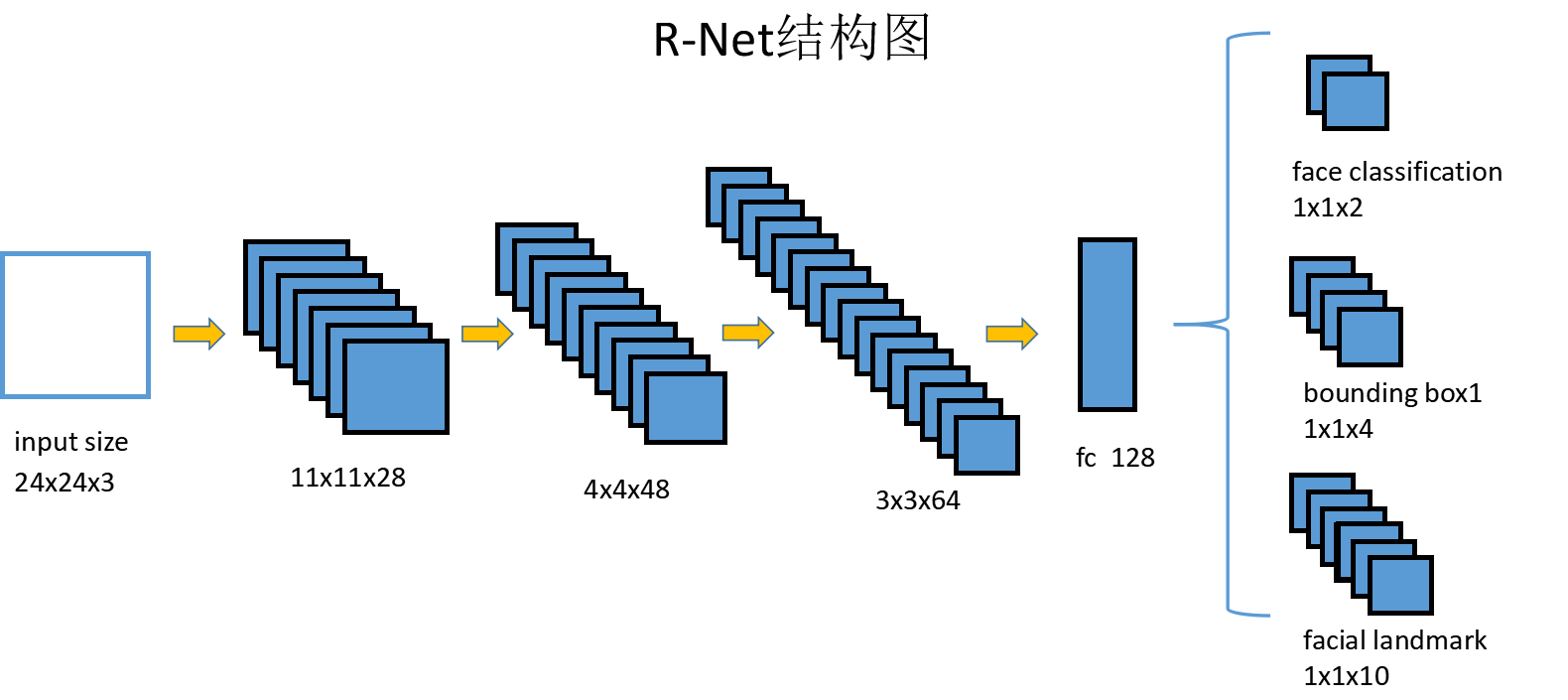
除了輸入大小與中間層大小不同,R-Net的結構與P-Net非常相似,只是在最後的輸出層前多加入了一個全連線層。R-Net的輸出完全與P-Net一樣,同樣由人臉判別,框迴歸,關鍵點位置預測三部分組成。
第三個網路O-Net結構如下:
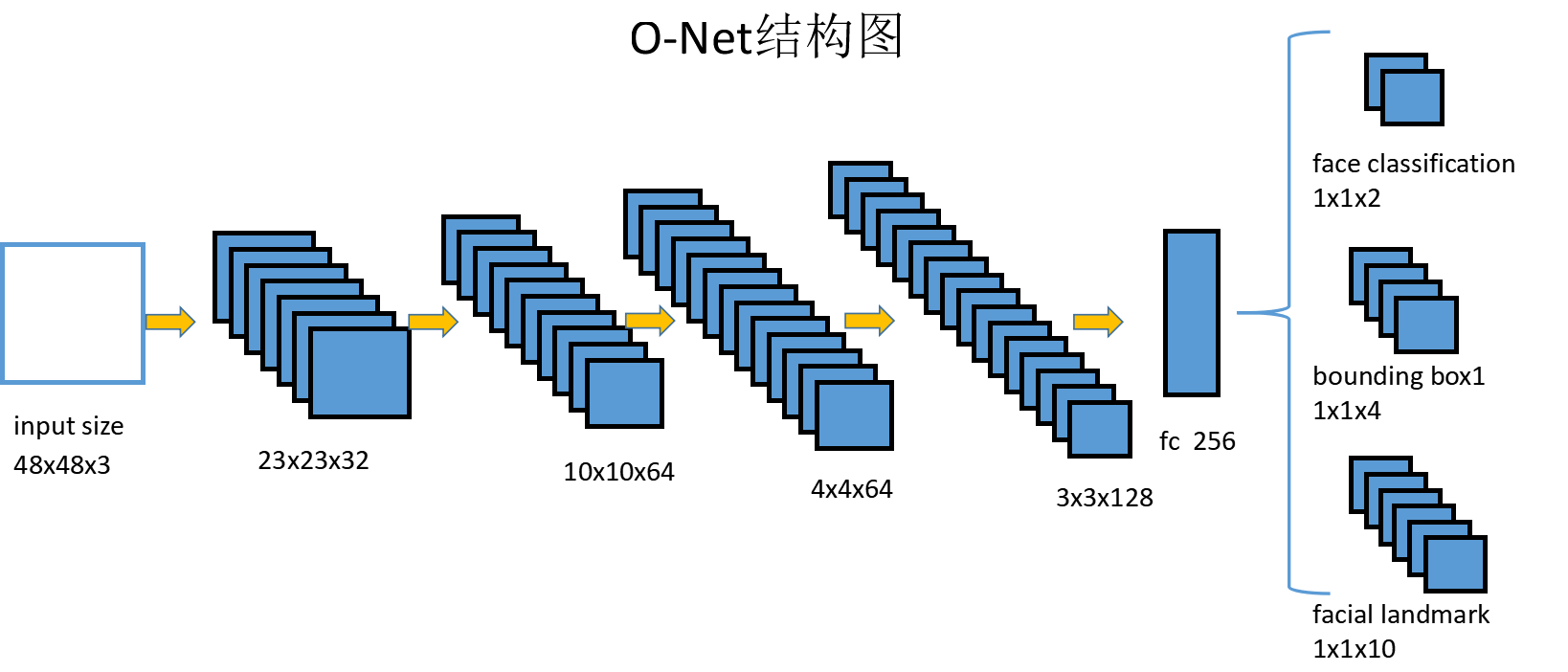
O-Net相比R-Net在結構上又多出一箇中間層,但是輸出結果還是一樣的。
從P-Net到R-Net,再到O-Net,網路輸入的圖片越來越大,中間層的通道數越來越多,識別人臉的準確度也越來越高。實際上mtcnn的工作原理就是P-Net先做一遍過濾,將過濾後的結果交給R-Net進行過濾,最後再將過濾的結果交給O-Net進行判別。它是層層遞進的一個篩查機制。
mtcnn中每個網路都有三部分輸出,因此訓練時損失的定義也由三部分組成。針對人臉判別face classification,使用交叉熵損失,針對框和迴歸點的判定,直接使用L2損失。最後這三部分損失各自乘以自身的權重再加起來,形成最後的總損失。P-Net和R-Net網路關心框位置的準確性,O-Net關心關鍵點判定,它們三部分的各自權重是不一樣的。
mtcnn網路需要大量的人臉資料進行訓練,才能得到合適的網路引數,達到較好的檢測效果。在github上有已經訓練好的mtcnn模型可以直接使用,點這裡可以直達。其中的src/align/detect_face.py與det1.npy,det2.npy,det3.npy就是mtcnn網路的結構與訓練模型,可以直接使用。
測試mtcnn的部分程式碼:
def test():
video = cv2.VideoCapture(0)
print('Creating networks and loading parameters')
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=1.0)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = detect_face.create_mtcnn(sess, None)
minsize = 20
threshold = [0.6, 0.7, 0.7]
factor = 0.709
while True:
ret, frame = video.read()
bounding_boxes, _ = detect_face.detect_face(frame, minsize, pnet, rnet, onet, threshold, factor)
nrof_faces = bounding_boxes.shape[0]
print('找到人臉數目為:{}'.format(nrof_faces))
for face_position in bounding_boxes:
face_position = face_position.astype(int)
cv2.rectangle(frame, (face_position[0], face_position[1]),(face_position[2], face_position[3]), (0, 255, 0), 2)
cv2.imshow('show', frame)
if cv2.waitKey(5) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()經過測試,mtcnn的實時性和準確性都非常好。