
深度自解碼器(Deep Auto-encoder)
本部落格是針對李巨集毅教授在youtube上釋出的課程視訊的學習筆記。
Auto-encoder
Encoder and Decoder
Each one of them can’t be trained respectively(no goal or no input), but they can be linked and trained together.
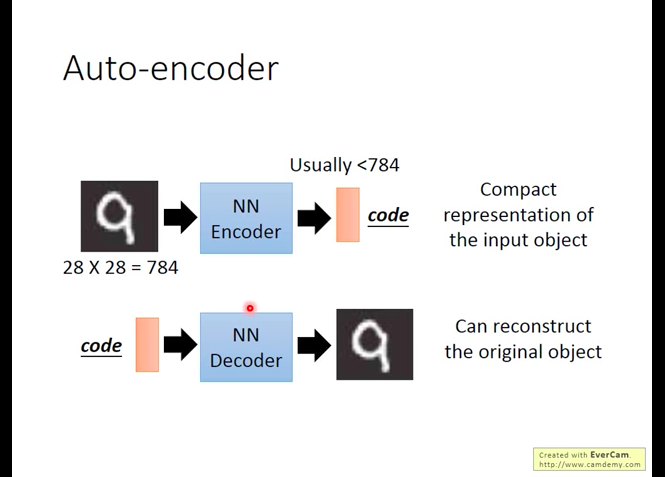
Starting from PCA
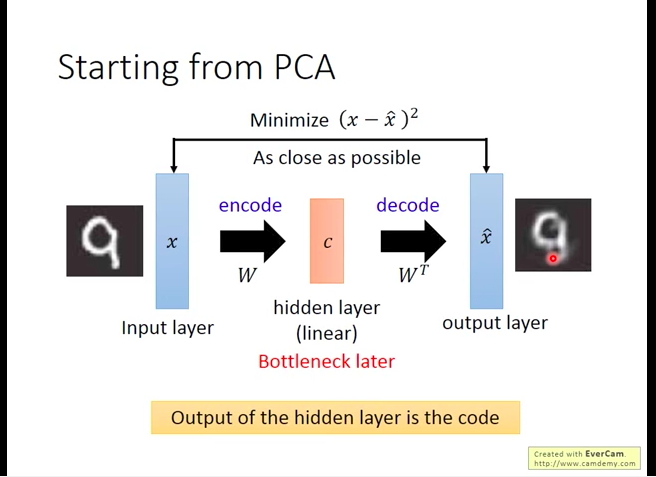
PCA only has one hidden layer, so we can deepen it to Deep Auto-encoder.

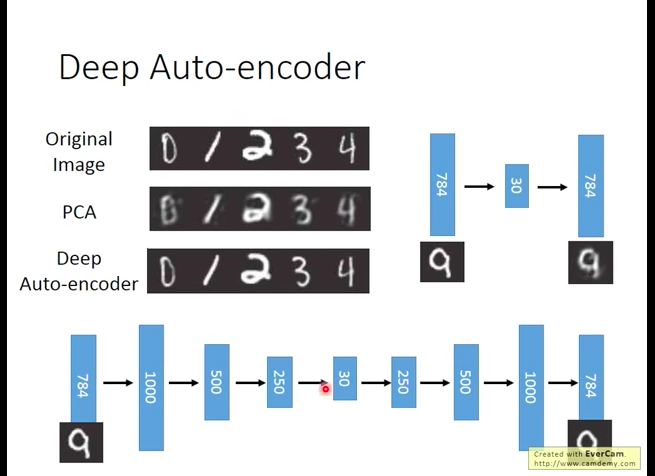
Above is Hinton(2006)’s design of deep auto-encoder, it achieves good result.
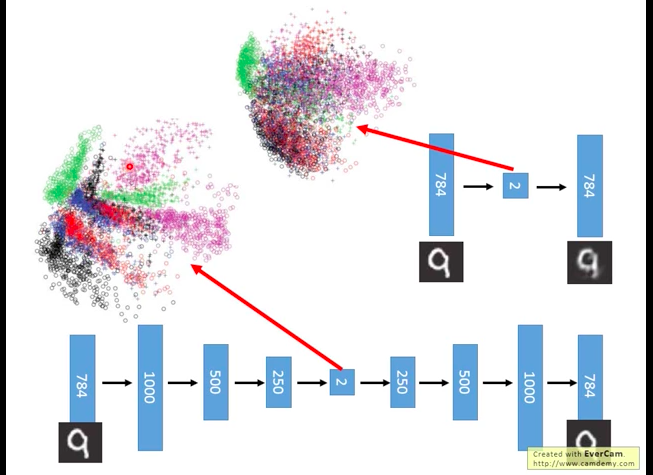
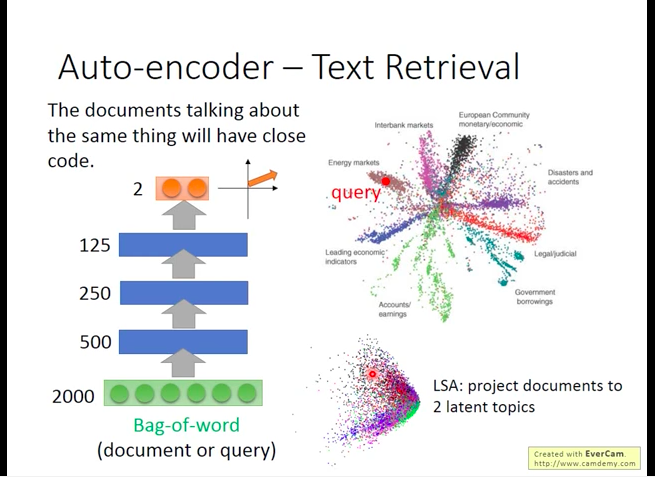
Application: Text Retrieval
To compress an article into a CODE.
Vector Space Model and Bag-of-Word Model
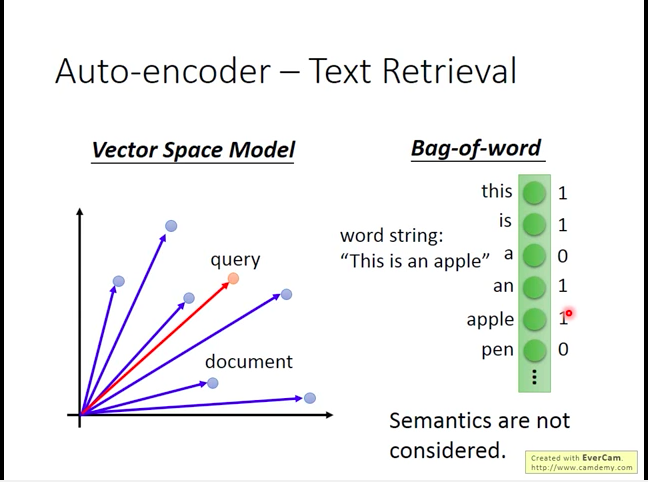
In Bag-of-Word the shortcoming is that semantic factor is not considered in model.
Application: Similar Image Search

Focusing on pixel-wise similarity may not induce good result~(MJ similar to Magnet….)

Use Deep auto-encoder to preprocess picture.

Focusing on CODE similarity induce better result.
Pre-training DNN
Use Auto-encoder to do pre-training.
Learn a auto-encoder first (lower right, apply L1 regularization to avoid auto-encoder’s ‘remembering’ input), then learn another auto-encoder(middle right), ….., at last, 500-10 layer’s weight can be learned using backpropagation.
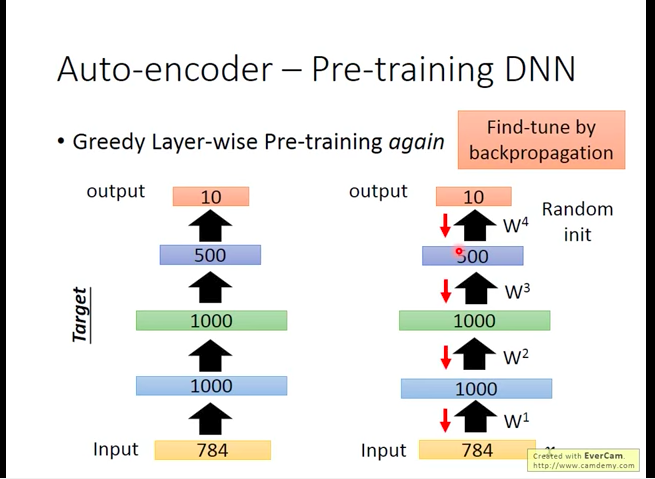
pre-training is necessary before in training DNN, but now with development of training technology, we can get good training result without pre-training. But When we have many unlabeled data, we could still use these data to pre-training to make final training better.
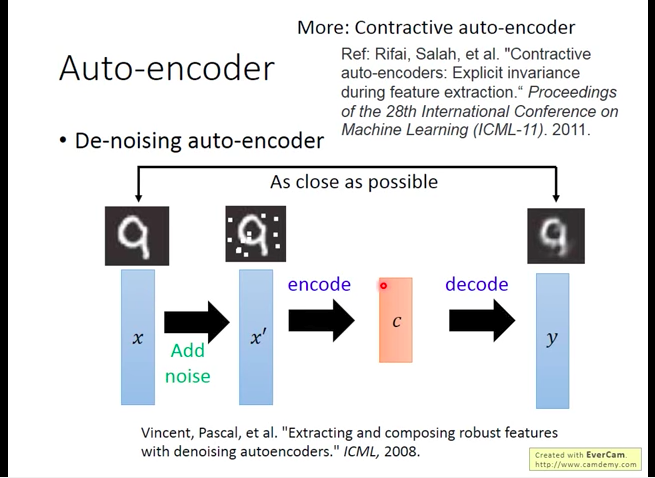
De-noising auto-encoder (contractive auto-encoder)
Restricted Boltzmann Machine (RBM) -different from DNN, just look similar

Deep Belief Network (DBN) -different from DNN, just look similar

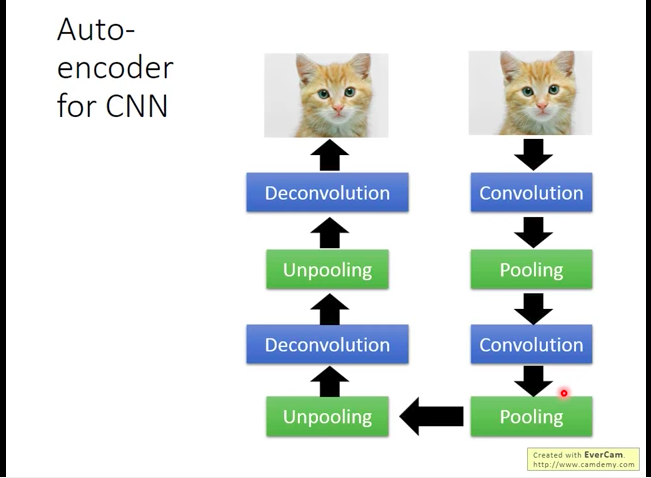
Auto-encoder for CNN
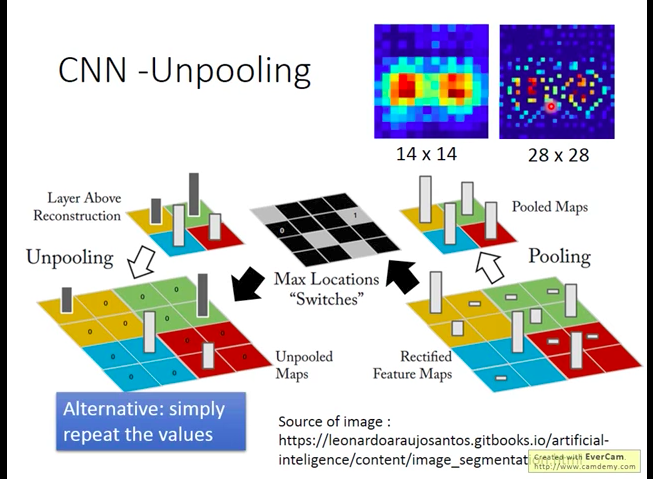
Unpooling
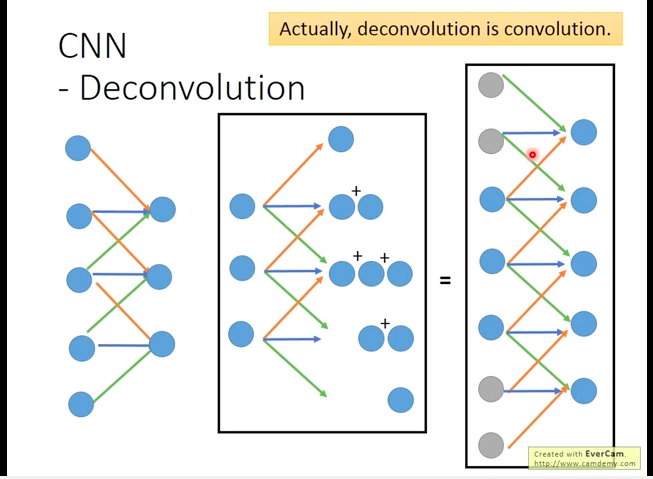
Deconvolution
Padding+Convolution=Deconvolution
Suquence-to-Sequence Auto-encoder
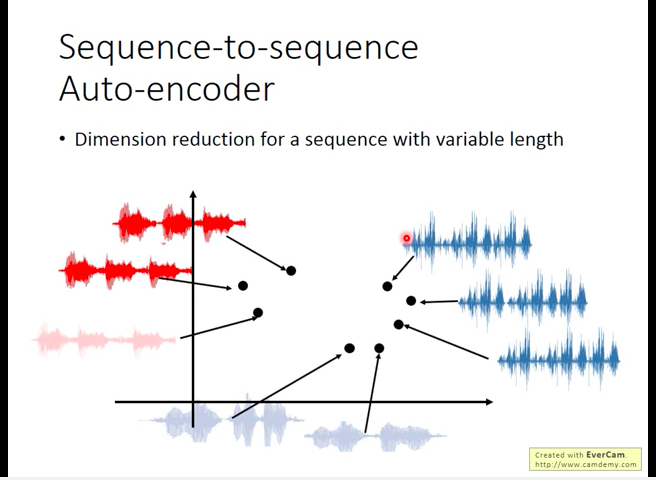
Some data is not ‘good’ to be represented in vector(like voice, article[lose semantic meaning]), it’s better to represent them in sequence.
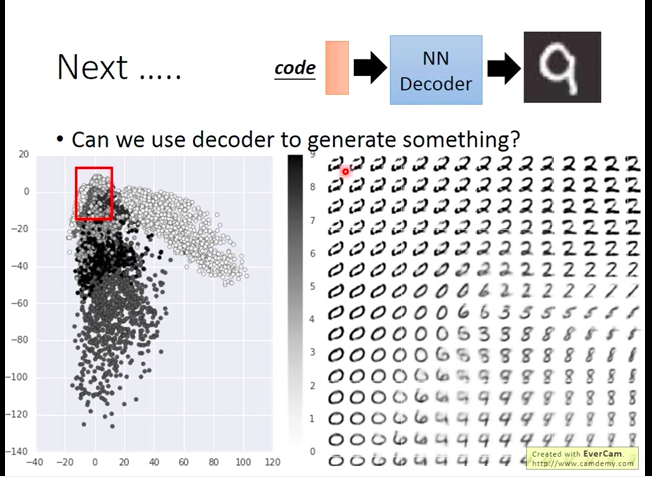
After impact L2 regularization to training process, we can get below:
