
Autoencorder理解(5):VAE(Variational Auto-Encoder,變分自編碼器)
reference: http://blog.csdn.net/jackytintin/article/details/53641885
近年,隨著有監督學習的低枝果實被採摘的所剩無幾,無監督學習成為了研究熱點。VAE(Variational Auto-Encoder,變分自編碼器)[1,2] 和 GAN(Generative Adversarial Networks) 等模型,受到越來越多的關注。
筆者最近也在學習 VAE 的知識(從深度學習角度)。首先,作為工程師,我想要正確的實現 VAE 演算法,以及瞭解 VAE 能夠幫助我們解決什麼實際問題;作為人工智慧從業者,我同時希望在一定程度上了解背後的原理。
作為學習筆記,本文按照由簡到繁的順序,首先介紹 VAE 的具體演算法實現;然後,再從直觀上解釋 VAE 的原理;最後,對 VAE 的數學原理進行回顧。我們會在適當的地方,對變分、自編碼、無監督、生成模型等概念進行介紹。
我們會看到,同許多機器演算法一樣,VAE 背後的數學比較複雜,然而,工程實現上卻非常簡單。
1. 演算法實現
這裡介紹 VAE 的一個比較簡單的實現,儘量與文章[1] Section 3 的實驗設定保持一致。完整程式碼可以參見 repo。
1.1 輸入:
資料集
做為例子,可以設想
X 為 MNIST 資料集。因此,我們有六萬張 0~9 的手寫體 的灰度圖(訓練集), 大小為28 。進一步,將每個畫素歸一化到×28[0,1] ,則X⊂[0,1]784 。

圖1. MNIST demo (圖片來源)
1.2 輸出:
一個輸入為
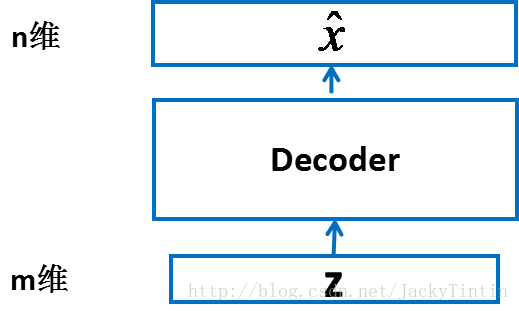
圖 2. decoder
- 在輸入輸出維度滿足要求的前提下,decoder 以為任何結構——MLP、CNN,RNN 或其他。
- 由於我們已經將輸入資料規一化到 [0, 1] 區間,因此,我們令 decoder 的輸出也在這個範圍內。這可以通過在 decoder 的最後一層加上 sigmoid 啟用實現 :
f (x)=11+e−x- 作為例子,我們取 m = 100,decoder 的為最普遍的全連線網路(MLP)。基於 Keras Functional API 的定義如下:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.3 訓練
圖 3. VAE 結構框架
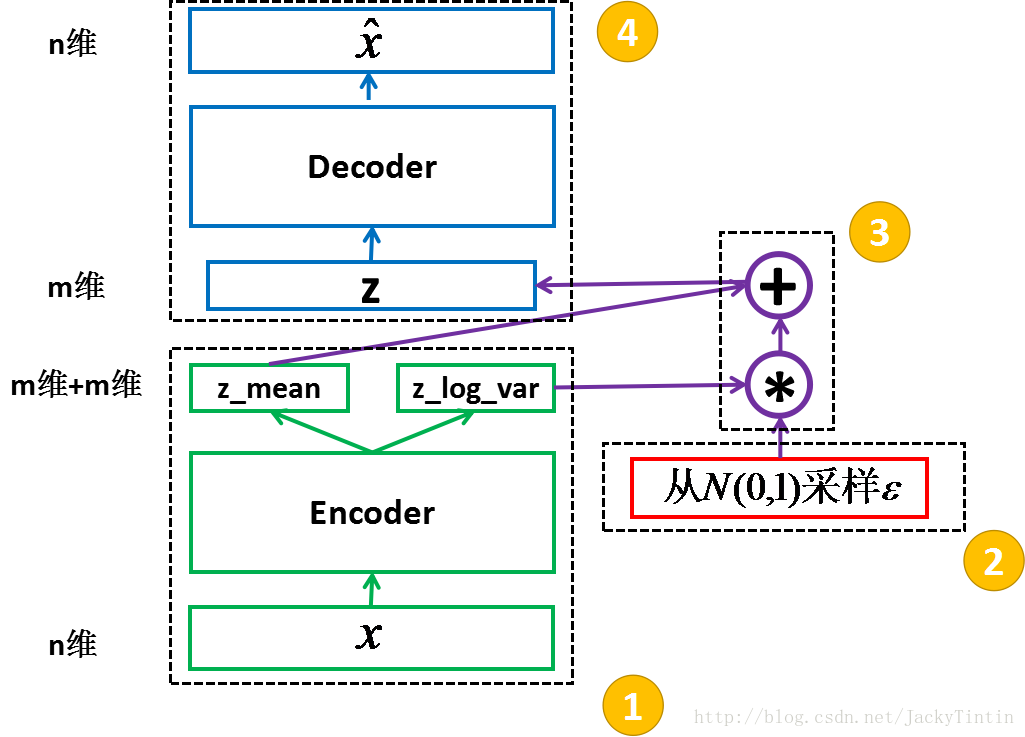
1.3.1 encoder
為了訓練 decoder,我們需要一個輔助的 encoder 網路(又稱 recognition model)(如圖3)。encoder 的輸入為
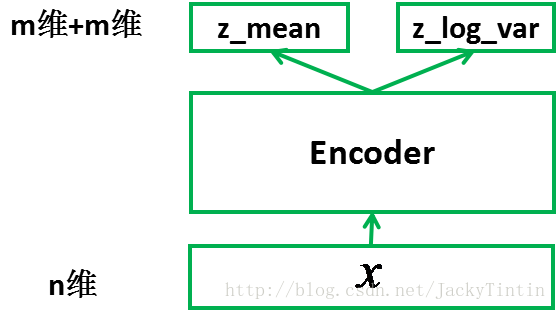
圖 4. encoder
1.3.2 取樣(sampling)
我們將 encoder 的輸出(
接著上面的例子,encoder 的定義如下:
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
然後,根據 encoder 輸出的均值與方差,生成服從相應高斯分佈的隨機數:
- 1
- 2
- 3
- 1
- 2
- 3
圖5. 取樣
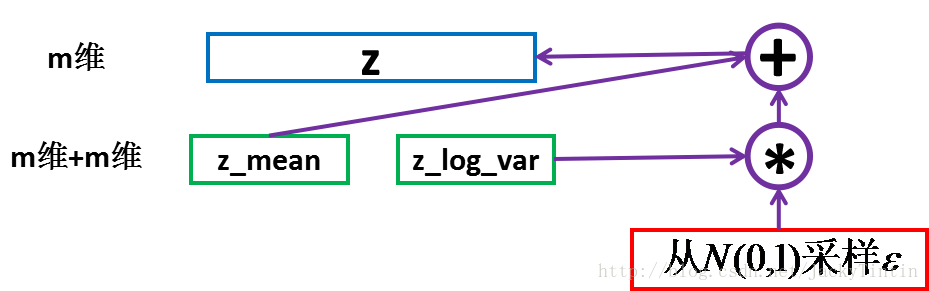
這裡運用了 reparemerization 的技巧。由於
z∼N(μ,σ) ,我們應該從N(μ,σ) 取樣,但這個取樣操作對μ 和σ 是不可導的,導致常規的通過誤差反傳的梯度下降法(GD)不能使用。通過 reparemerization,我們首先從N(0,1) 上取樣ϵ ,然後,z=σ⋅ϵ+μ 。這樣,z∼N(μ,σ) ,而且,從 encoder 輸出到相關推薦
Autoencorder理解(5):VAE(Variational Auto-Encoder,變分自編碼器)
reference: http://blog.csdn.net/jackytintin/article/details/53641885 近年,隨著有監督學習的低枝果實被採摘的所剩無幾,無監督學習成為了研究熱點。VAE(Variational Auto-Encode
白話Variational Autoencoder(變分自編碼器)
本文將簡單介紹一下Variational Autoencoder。作者也在學習當中,如有不正確的地方,請大家指正,謝謝~原始的autoencoder一般分為兩個部分encoder part和decoder part。 encoder是將input轉化為encoding vec
【Learning Notes】變分自編碼器(Variational Auto-Encoder,VAE)
近年,隨著有監督學習的低枝果實被採摘的所剩無幾,無監督學習成為了研究熱點。VAE(Variational Auto-Encoder,變分自編碼器)[1,2] 和 GAN(Generative Adversarial Networks) 等模型,受到越來越多的關注
[深度學習]半監督學習、無監督學習之Variational Auto-Encoder變分自編碼器(附程式碼)
論文全稱:《Auto-Encoding Variational Bayes》 論文地址:https://arxiv.org/pdf/1312.6114.pdf 論文程式碼: keras 版本:https://github.com/bojone/vae pytorch 版本:https
從零上手變分自編碼器(VAE)
閱讀更多,歡迎關注公眾號:論文收割機(paper_reader) Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013. Rez
VAE變分自編碼器的一點理解
前言 網上很多關於VAE的教程都包含大量枯燥難懂的數學公式,如果有大佬特別喜歡推導這些公式,很高興能夠附上以下連結。然而,今天只是想簡單的談下自己的理解,只有圖片,沒有公式。 主要內容 如下圖所示,其實VAE的主要思想就是以均值方差計算模組來作為Enc
VAE----變分自編碼器Keras實現
這篇部落格用來記錄我自己用keras實現(抄寫)VAE過程中,掉進的一個坑。。。。。。 最近這幾天在網上看了很多VAE的介紹,並且看了一下keras中的實現。自我感覺良好,就想按著官方的程式碼自己也去寫一遍。不寫不知道,一寫嚇一跳!!我跳進了一個很大坑中(笑哭),我在把程式碼寫完以後,開始訓
關於FV(Fisher Vector)和變分自編碼VAE(Variational Autoencoder)的原理簡介
1. FV(Fisher Vector) FV的思想用一句話概括就是:用所有的聚類中心的線性組合去表示每個特徵點 簡單來說,假設樣本各特徵符合獨立同分布(i.i.d)則樣本的概率分佈可以由各個特徵維度的概率分佈的乘積得到。對該式取對數的話,就可以將乘法運算轉換為加
Variational Autoencoder(變分自編碼)
使用通用自編碼器的時候,首先將輸入encoder壓縮為一個小的 form,然後將其decoder轉換成輸出的一個估計。如果目標是簡單的重現輸入效果很好,但是若想生成新的物件就不太可行了,因為其實我們根本不知道這個網路所生成的編碼具體是什麼。雖然我們可以通過結果去對比不同的物件,但是要理解
沒有任何公式——直觀的理解變分自動編碼器VAE
autoencoders作為一種非常直觀的無監督的學習方法是很受歡迎的,最簡單的情況是三層的神經網路,第一層是資料輸入,第二層的節點數一般少於輸入層,並且第三層與輸入層類似,層與層之間互相全連線,這種網路被稱作自動編碼器,因為該網路將輸入“編碼”成一個隱藏程式碼,
變分自編碼(VAE)及程式碼解讀
這幾天在看GAN模型的時候,順便關注了另外一種生成模型——VAE。其實這種生成模型在早幾年就有了,而且有了一些應用。著名黑客George Hotz在其開源的自主駕駛專案中就應用到了VAE模型。這其中的具體應用在我上一篇轉載的部落格comma.ai中有詳細介紹。在對VAE基本原
LearningNotes 變分自編碼 VariationalAutoEncoder VAE
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Autoencoder(自編碼器)
自編碼器原理: 在神經網路中是監督學習下的操作,那麼它又如何應用到無監督學習中呢?一個直觀的想法就是讓經過了神經網路的輸入等於元輸入,或者儘量相差不大。這樣做不就可以學習到輸入資料中隱含著某些特定的結構,甚至通過設計神經元數目來完成資料壓縮嗎?自編碼器由一個編碼器(encoder)函
文章解析整理:《基於TensorFlow理解三大降維技術:Pca,t-SNE 和自編碼器》
本文僅是博主自己學習用來加深印象和留存整理,對該內容有興趣請去閱讀原文 首先降維很重要 先從PCA開始 PCA,主成份分析,有很多種實現方案,這裡主要是其中兩種:Eigen分解和奇異值分解(SVD) 這兩種方法是靠自己的方式找到一種操作並分解x的方法
echarts2.0修改markpoint及markline的屬性(markpoint顯示隱藏,並且實現自定義圖例)
//圖例線條顏色,按順序來,不夠需要新增 var gar_colors = ['#CC6666', '#FFA026', '#FF0200', '#666633', '#FF00CC', '#CC6633', '#9933FF', '#CC33CC', '#33CCFF',
深度自解碼器(Deep Auto-encoder)
本部落格是針對李巨集毅教授在youtube上釋出的課程視訊的學習筆記。 Auto-encoder Encoder and Decoder Each one of them can’t be trained respectively(no
16、【李巨集毅機器學習(2017)】Unsupervised Learning: Deep Auto-encoder(無監督學習:深度自動編碼器)
本篇部落格將介紹無監督學習演算法中的 Deep Auto-encoder。 目錄 Deep Auto-encoder 輸入28*28維度的影象畫素,由NN encoder輸出code,code的維度往往小於784,但我們並不知道code的