
ConcurrentHashMap原理深度分析、鎖分段技術
阿新 • • 發佈:2019-02-03
參考:https://www.cnblogs.com/ITtangtang/p/3948786.html
一、背景:
執行緒不安全的HashMap
因為多執行緒環境下,使用Hashmap進行put操作會引起死迴圈,導致CPU利用率接近100%,所以在併發情況下不能使用HashMap。效率低下的HashTable容器
HashTable容器使用synchronized來保證執行緒安全,但線上程競爭激烈的情況下HashTable的效率非常低下。因為當一個執行緒訪問HashTable的同步方法時,其他執行緒訪問HashTable的同步方法時,可能會進入阻塞或輪詢狀態。如執行緒1使用put進行新增元素,執行緒2不但不能使用put方法新增元素,並且也不能使用get方法來獲取元素,所以競爭越激烈效率越低。鎖分段技術
二、應用場景
三、原始碼解讀
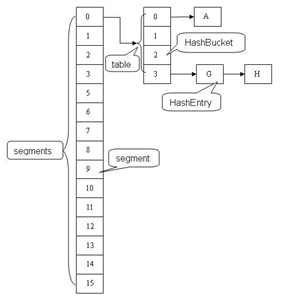
ConcurrentHashMap(1.7及之前)中主要實體類就是三個:ConcurrentHashMap(整個Hash表),Segment(桶),HashEntry(節點),對應上面的圖可以看出之間的關係/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;不變(Immutable)和易變(Volatile)
ConcurrentHashMap完全允許多個讀操作併發進行,讀操作並不需要加鎖。如果使用傳統的技術,如HashMap中的實現,如果允許可以在hash鏈的中間新增或刪除元素,讀操作不加鎖將得到不一致的資料。ConcurrentHashMap實現技術是保證HashEntry幾乎是不可變的。HashEntry代表每個hash鏈中的一個節點,其結構如下所示: static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
} 可以看到除了value不是final的,其它值都是final的,這意味著不能從hash鏈的中間或尾部新增或刪除節點,因為這需要修改next 引用值,所有的節點的修改只能從頭部開始。對於put操作,可以一律新增到Hash鏈的頭部。但是對於remove操作,可能需要從中間刪除一個節點,這就需要將要刪除節點的前面所有節點整個複製一遍,最後一個節點指向要刪除結點的下一個結點。這在講解刪除操作時還會詳述。為了確保讀操作能夠看到最新的值,將value設定成volatile,這避免了加鎖。其它
為了加快定位段以及段中hash槽的速度,每個段hash槽的的個數都是2^n,這使得通過位運算就可以定位段和段中hash槽的位置。當併發級別為預設值16時,也就是段的個數,hash值的高4位決定分配在哪個段中。但是我們也不要忘記《演算法導論》給我們的教訓:hash槽的的個數不應該是 2^n,這可能導致hash槽分配不均,這需要對hash值重新再hash一次。(這段似乎有點多餘了 )定位操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
} 既然ConcurrentHashMap使用分段鎖Segment來保護不同段的資料,那麼在插入和獲取元素的時候,必須先通過雜湊演算法定位到Segment。可以看到ConcurrentHashMap會首先使用Wang/Jenkins hash的變種演算法對元素的hashCode進行一次再雜湊。再雜湊,其目的是為了減少雜湊衝突,使元素能夠均勻的分佈在不同的Segment上,從而提高容器的存取效率。假如雜湊的質量差到極點,那麼所有的元素都在一個Segment中,不僅存取元素緩慢,分段鎖也會失去意義。我做了一個測試,不通過再雜湊而直接執行雜湊計算。System.out.println(Integer.parseInt("0001111", 2) & 15);System.out.println(Integer.parseInt("0011111", 2) & 15);System.out.println(Integer.parseInt("0111111", 2) & 15);System.out.println(Integer.parseInt("1111111", 2) & 15);計算後輸出的雜湊值全是15,通過這個例子可以發現如果不進行再雜湊,雜湊衝突會非常嚴重,因為只要低位一樣,無論高位是什麼數,其雜湊值總是一樣。我們再把上面的二進位制資料進行再雜湊後結果如下,為了方便閱讀,不足32位的高位補了0,每隔四位用豎線分割下。0100|0111|0110|0111|1101|1010|0100|11101111|0111|0100|0011|0000|0001|1011|10000111|0111|0110|1001|0100|0110|0011|11101000|0011|0000|0000|1100|1000|0001|1010可以發現每一位的資料都雜湊開了,通過這種再雜湊能讓數字的每一位都能參加到雜湊運算當中,從而減少雜湊衝突。ConcurrentHashMap通過以下雜湊演算法定位segment。預設情況下segmentShift為28,segmentMask為15,再雜湊後的數最大是32位二進位制資料,向右無符號移動28位,意思是讓高4位參與到hash運算中, (hash >>> segmentShift) & segmentMask的運算結果分別是4,15,7和8,可以看到hash值沒有發生衝突。final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}資料結構
所有的成員都是final的,其中segmentMask和segmentShift主要是為了定位段,參見上面的segmentFor方法。 關於Hash表的基礎資料結構,這裡不想做過多的探討。Hash表的一個很重要方面就是如何解決hash衝突,ConcurrentHashMap 和HashMap使用相同的方式,都是將hash值相同的節點放在一個hash鏈中。與HashMap不同的是,ConcurrentHashMap使用多個子Hash表,也就是段(Segment)。每個Segment相當於一個子Hash表,它的資料成員如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment's region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
} count用來統計該段資料的個數,它是volatile,它用來協調修改和讀取操作,以保證讀取操作能夠讀取到幾乎最新的修改。協調方式是這樣的,每次修改操作做了結構上的改變,如增加/刪除節點(修改節點的值不算結構上的改變),都要寫count值,每次讀取操作開始都要讀取count的值。這利用了 Java 5中對volatile語義的增強,對同一個volatile變數的寫和讀存在happens-before關係。modCount統計段結構改變的次數,主要是為了檢測對多個段進行遍歷過程中某個段是否發生改變,在講述跨段操作時會還會詳述。threashold用來表示需要進行rehash的界限值。table陣列儲存段中節點,每個陣列元素是個hash鏈,用HashEntry表示。table也是volatile,這使得能夠讀取到最新的 table值而不需要同步。loadFactor表示負載因子。刪除操作remove(key)
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
} 整個操作是先定位到段,然後委託給段的remove操作。當多個刪除操作併發進行時,只要它們所在的段不相同,它們就可以同時進行。下面是Segment的remove方法實現: V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
} 整個操作是在持有段鎖的情況下執行的,空白行之前的行主要是定位到要刪除的節點e。接下來,如果不存在這個節點就直接返回null,否則就要將e前面的結點複製一遍,尾結點指向e的下一個結點。e後面的結點不需要複製,它們可以重用。中間那個for迴圈是做什麼用的呢?(*號標記)從程式碼來看,就是將定位之後的所有entry克隆並拼回前面去,但有必要嗎?每次刪除一個元素就要將那之前的元素克隆一遍?這點其實是由entry的不變性來決定的,仔細觀察entry定義,發現除了value,其他所有屬性都是用final來修飾的,這意味著在第一次設定了next域之後便不能再改變它,取而代之的是將它之前的節點全都克隆一次。至於entry為什麼要設定為不變性,這跟不變性的訪問不需要同步從而節省時間有關下面是個示意圖 刪除元素之前: 刪除元素3之後:
刪除元素3之後: 第二個圖其實有點問題,複製的結點中應該是值為2的結點在前面,值為1的結點在後面,也就是剛好和原來結點順序相反,還好這不影響我們的討論。整個remove實現並不複雜,但是需要注意如下幾點。第一,當要刪除的結點存在時,刪除的最後一步操作要將count的值減一。這必須是最後一步操作,否則讀取操作可能看不到之前對段所做的結構性修改。第二,remove執行的開始就將table賦給一個區域性變數tab,這是因為table是 volatile變數,讀寫volatile變數的開銷很大。編譯器也不能對volatile變數的讀寫做任何優化,直接多次訪問非volatile例項變數沒有多大影響,編譯器會做相應優化。
第二個圖其實有點問題,複製的結點中應該是值為2的結點在前面,值為1的結點在後面,也就是剛好和原來結點順序相反,還好這不影響我們的討論。整個remove實現並不複雜,但是需要注意如下幾點。第一,當要刪除的結點存在時,刪除的最後一步操作要將count的值減一。這必須是最後一步操作,否則讀取操作可能看不到之前對段所做的結構性修改。第二,remove執行的開始就將table賦給一個區域性變數tab,這是因為table是 volatile變數,讀寫volatile變數的開銷很大。編譯器也不能對volatile變數的讀寫做任何優化,直接多次訪問非volatile例項變數沒有多大影響,編譯器會做相應優化。get操作
ConcurrentHashMap的get操作是直接委託給Segment的get方法,直接看Segment的get方法:V get(Object key, int hash) {
if (count != 0) { // read-volatile 當前桶的資料個數是否為0
HashEntry<K,V> e = getFirst(hash); 得到頭節點
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
} get操作不需要鎖。 除非讀到的值是空的才會加鎖重讀,我們知道HashTable容器的get方法是需要加鎖的,那麼ConcurrentHashMap的get操作是如何做到不加鎖的呢?原因是它的get方法裡將要使用的共享變數都定義成volatile 第一步是訪問count變數,這是一個volatile變數,由於所有的修改操作在進行結構修改時都會在最後一步寫count 變數,通過這種機制保證get操作能夠得到幾乎最新的結構更新。對於非結構更新,也就是結點值的改變,由於HashEntry的value變數是 volatile的,也能保證讀取到最新的值。 接下來就是根據hash和key對hash鏈進行遍歷找到要獲取的結點,如果沒有找到,直接訪回null。對hash鏈進行遍歷不需要加鎖的原因在於鏈指標next是final的。但是頭指標卻不是final的,這是通過getFirst(hash)方法返回,也就是存在 table陣列中的值。這使得getFirst(hash)可能返回過時的頭結點,例如,當執行get方法時,剛執行完getFirst(hash)之後,另一個執行緒執行了刪除操作並更新頭結點,這就導致get方法中返回的頭結點不是最新的。這是可以允許,通過對count變數的協調機制,get能讀取到幾乎最新的資料,雖然可能不是最新的。要得到最新的資料,只有採用完全的同步。 最後,如果找到了所求的結點,判斷它的值如果非空就直接返回,否則在有鎖的狀態下再讀一次。這似乎有些費解,理論上結點的值不可能為空,這是因為 put的時候就進行了判斷,如果為空就要拋NullPointerException。空值的唯一源頭就是HashEntry中的預設值,因為 HashEntry中的value不是final的,非同步讀取有可能讀取到空值。仔細看下put操作的語句:tab[index] = new HashEntry<K,V>(key, hash, first, value),在這條語句中,HashEntry建構函式中對value的賦值以及對tab[index]的賦值可能被重新排序,這就可能導致結點的值為空。這裡當v為空時,可能是一個執行緒正在改變節點,而之前的get操作都未進行鎖定,根據bernstein條件,讀後寫或寫後讀都會引起資料的不一致,所以這裡要對這個e重新上鎖再讀一遍,以保證得到的是正確值。 V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
} 如用於統計當前Segement大小的count欄位和用於儲存值的HashEntry的value。定義成volatile的變數,能夠線上程之間保持可見性,能夠被多執行緒同時讀,並且保證不會讀到過期的值,但是隻能被單執行緒寫(有一種情況可以被多執行緒寫,就是寫入的值不依賴於原值),在get操作裡只需要讀不需要寫共享變數count和value,所以可以不用加鎖。之所以不會讀到過期的值,是根據java記憶體模型的happen before原則,對volatile欄位的寫入操作先於讀操作,即使兩個執行緒同時修改和獲取volatile變數,get操作也能拿到最新的值,這是用volatile替換鎖的經典應用場景put操作
同樣地put操作也是委託給段的put方法。下面是段的put方法: V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
} 該方法也是在持有段鎖(鎖定整個segment)的情況下執行的,這當然是為了併發的安全,修改資料是不能併發進行的,必須得有個判斷是否超限的語句以確保容量不足時能夠rehash。接著是找是否存在同樣一個key的結點,如果存在就直接替換這個結點的值。否則建立一個新的結點並新增到hash鏈的頭部,這時一定要修改modCount和count的值,同樣修改count的值一定要放在最後一步。put方法呼叫了rehash方法,reash方法實現得也很精巧,主要利用了table的大小為2^n,這裡就不介紹了。而比較難懂的是這句int index = hash & (tab.length - 1),原來segment裡面才是真正的hashtable,即每個segment是一個傳統意義上的hashtable,如上圖,從兩者的結構就可以看出區別,這裡就是找出需要的entry在table的哪一個位置,之後得到的entry就是這個鏈的第一個節點,如果e!=null,說明找到了,這是就要替換節點的值(onlyIfAbsent == false),否則,我們需要new一個entry,它的後繼是first,而讓tab[index]指向它,什麼意思呢?實際上就是將這個新entry插入到鏈頭,剩下的就非常容易理解了 由於put方法裡需要對共享變數進行寫入操作,所以為了執行緒安全,在操作共享變數時必須得加鎖。Put方法首先定位到Segment,然後在Segment裡進行插入操作。插入操作需要經歷兩個步驟,第一步判斷是否需要對Segment裡的HashEntry陣列進行擴容,第二步定位新增元素的位置然後放在HashEntry數組裡。- 是否需要擴容。在插入元素前會先判斷Segment裡的HashEntry陣列是否超過容量(threshold),如果超過閥值,陣列進行擴容。值得一提的是,Segment的擴容判斷比HashMap更恰當,因為HashMap是在插入元素後判斷元素是否已經到達容量的,如果到達了就進行擴容,但是很有可能擴容之後沒有新元素插入,這時HashMap就進行了一次無效的擴容。
- 如何擴容。擴容的時候首先會建立一個兩倍於原容量的陣列,然後將原數組裡的元素進行再hash後插入到新的數組裡。為了高效ConcurrentHashMap不會對整個容器進行擴容,而只對某個segment進行擴容。
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}