
Spark實踐-日誌查詢
- 環境
win 7
jdk 1.7.0_79 (Oracle Corporation)
scala version 2.10.5
spark 1.6.1
詳細配置:
Spark Properties
spark.app.id local-1461891171126
spark.app.name JavaLogQuery
spark.driver.host 10.170.26.123
spark.driver.port 34998
spark.executor.id driver
spark.externalBlockStore.folderName - 任務
完成對如下日誌的查詢:
"10.10.10.10 - \"FRED\" [18/Jan/2013:17:56:07 +1100] \"GET http://images.com/2013/Generic.jpg " +
"HTTP/1.1\" 304 315 \"http://referall.com/\" \"Mozilla/4.0 (compatible; MSIE 7.0; " +
"Windows NT 5.1; GTB7.4; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648; " +
".NET CLR 3.5.21022; .NET CLR 3.0.4506.2152; .NET CLR 1.0.3705; .NET CLR 1.1.4322; .NET CLR " +
"3.5.30729; Release=ARP)\" 思路:
1.利用正則表示式提取出日誌特徵,然後map在分片後的RDD上。
JavaPairRDD<Tuple3<String, String, String>, Stats> extracted2.執行reducebykey,merge相同的Stats
package org.apache.spark.examples;
import com.google.common.collect.Lists;
import scala.Tuple2;
import scala.Tuple3;
import org.apache.commons.logging.impl.Log4JLogger;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import java.io.Serializable;
import java.util.Collections;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 日誌查詢
* @author jinhang
*
*/
public final class JavaLogQuery {
//模擬日誌 exampleApacheLogs
public static final List<String> exampleApacheLogs = Lists.newArrayList(
"10.10.10.10 - \"FRED\" [18/Jan/2013:17:56:07 +1100] \"GET http://images.com/2013/Generic.jpg " +
"HTTP/1.1\" 304 315 \"http://referall.com/\" \"Mozilla/4.0 (compatible; MSIE 7.0; " +
"Windows NT 5.1; GTB7.4; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648; " +
".NET CLR 3.5.21022; .NET CLR 3.0.4506.2152; .NET CLR 1.0.3705; .NET CLR 1.1.4322; .NET CLR " +
"3.5.30729; Release=ARP)\" \"UD-1\" - \"image/jpeg\" \"whatever\" 0.350 \"-\" - \"\" 265 923 934 \"\" " +
"62.24.11.25 images.com 1358492167 - Whatup",
"10.10.10.10 - \"FRED\" [18/Jan/2013:18:02:37 +1100] \"GET http://images.com/2013/Generic.jpg " +
"HTTP/1.1\" 304 306 \"http:/referall.com\" \"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; " +
"GTB7.4; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648; .NET CLR " +
"3.5.21022; .NET CLR 3.0.4506.2152; .NET CLR 1.0.3705; .NET CLR 1.1.4322; .NET CLR " +
"3.5.30729; Release=ARP)\" \"UD-1\" - \"image/jpeg\" \"whatever\" 0.352 \"-\" - \"\" 256 977 988 \"\" " +
"0 73.23.2.15 images.com 1358492557 - Whatup");
public static final Pattern apacheLogRegex = Pattern.compile(
"^([\\d.]+) (\\S+) (\\S+) \\[([\\w\\d:/]+\\s[+\\-]\\d{4})\\] \"(.+?)\" (\\d{3}) ([\\d\\-]+) \"([^\"]+)\" \"([^\"]+)\".*");
public static class Stats implements Serializable {
private final int count;
private final int numBytes;
public Stats(int count, int numBytes) {
this.count = count;
this.numBytes = numBytes;
}
public Stats merge(Stats other) {
return new Stats(count + other.count, numBytes + other.numBytes);
}
public String toString() {
return String.format("bytes=%s\tn=%s", numBytes, count);
}
}
public static Tuple3<String, String, String> extractKey(String line) {
Matcher m = apacheLogRegex.matcher(line);
if (m.find()) {
String ip = m.group(1);
String user = m.group(3);
String query = m.group(5);
if (!user.equalsIgnoreCase("-")) {
return new Tuple3<String, String, String>(ip, user, query);
}
}
return new Tuple3<String, String, String>(null, null, null);
}
public static Stats extractStats(String line) {
Matcher m = apacheLogRegex.matcher(line);
if (m.find()) {
int bytes = Integer.parseInt(m.group(7));
return new Stats(1, bytes);
} else {
return new Stats(1, 0);
}
}
public static void main(String[] args) {
Logger.getLogger(JavaLogQuery.class).setLevel(Level.FATAL);
SparkConf sparkConf = new SparkConf().setAppName("JavaLogQuery").setMaster("local[1]");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
JavaRDD<String> dataSet = (args.length == 1) ? jsc.textFile(args[0]) : jsc.parallelize(exampleApacheLogs);
JavaPairRDD<Tuple3<String, String, String>, Stats> extracted = dataSet.mapToPair(new PairFunction<String, Tuple3<String, String, String>, Stats>() {
@Override
public Tuple2<Tuple3<String, String, String>, Stats> call(String s) {
return new Tuple2<Tuple3<String, String, String>, Stats>(extractKey(s), extractStats(s));
}
});
JavaPairRDD<Tuple3<String, String, String>, Stats> counts = extracted.reduceByKey(new Function2<Stats, Stats, Stats>() {
@Override
public Stats call(Stats stats, Stats stats2) {
return stats.merge(stats2);
}
});
List<Tuple2<Tuple3<String, String, String>, Stats>> output = counts.collect();
//遍歷結果
for (Tuple2<?,?> t : output) {
System.out.println(t._1() + "\t" + t._2());
}
jsc.stop();
}
}
分析下執行過程:
載入SLF4J
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/D:/JavaProject/spark-demo/lib/spark-assembly-1.6.1-hadoop2.0.0-mr1-cdh4.2.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/D:/JavaProject/spark-demo/lib/spark-examples-1.6.1-hadoop2.0.0-mr1-cdh4.2.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]初始化sparkcontext上下文
16/04/29 09:36:22 INFO SparkContext: Running Spark version 1.6.1
//-Djava.library.path=$HADOOP_HOME/lib/native/Linux-amd64-64/*.jar可以解決
16/04/29 09:36:23 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
16/04/29 09:36:23 INFO SecurityManager: Changing view acls to: hp
16/04/29 09:36:23 INFO SecurityManager: Changing modify acls to: hp
16/04/29 09:36:23 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hp); users with modify permissions: Set(hp)
16/04/29 09:36:23 INFO Utils: Successfully started service 'sparkDriver' on port 36010.
16/04/29 09:36:23 INFO Slf4jLogger: Slf4jLogger started
16/04/29 09:36:24 INFO Remoting: Starting remoting
16/04/29 09:36:24 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@10.170.26.123:36023]
16/04/29 09:36:24 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 36023.
16/04/29 09:36:24 INFO SparkEnv: Registering MapOutputTracker
16/04/29 09:36:24 INFO SparkEnv: Registering BlockManagerMaster
16/04/29 09:36:24 INFO DiskBlockManager: Created local directory at C:\Users\hp\AppData\Local\Temp\blockmgr-84667505-0018-439b-9627-a4360d872118
16/04/29 09:36:24 INFO MemoryStore: MemoryStore started with capacity 517.4 MB
16/04/29 09:36:24 INFO SparkEnv: Registering OutputCommitCoordinator
16/04/29 09:36:24 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/04/29 09:36:24 INFO SparkUI: Started SparkUI at http://10.170.26.123:4040
16/04/29 09:36:24 INFO Executor: Starting executor ID driver on host localhost
16/04/29 09:36:24 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 36030.
16/04/29 09:36:24 INFO NettyBlockTransferService: Server created on 36030
16/04/29 09:36:24 INFO BlockManagerMaster: Trying to register BlockManager
16/04/29 09:36:24 INFO BlockManagerMasterEndpoint: Registering block manager localhost:36030 with 517.4 MB RAM, BlockManagerId(driver, localhost, 36030)
16/04/29 09:36:24 INFO BlockManagerMaster: Registered BlockManager
SecurityManager
‘sparkDriver’ on port 36010
Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:36023]
MapOutputTracker
BlockManagerMaster
DiskBlockManager: Created local directory at C:\Users\hp\AppData\Local\Temp\blockmgr-84667505-0018-439b-9627-
OutputCommitCoordinator
Executor
org.apache.spark.network.netty.NettyBlockTransferService
這幾個是幾個主要過程。
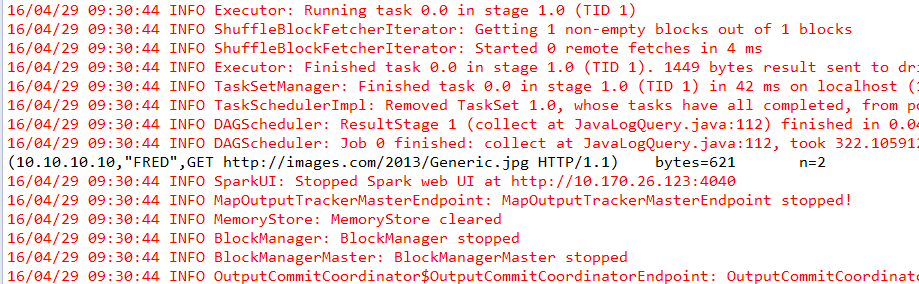
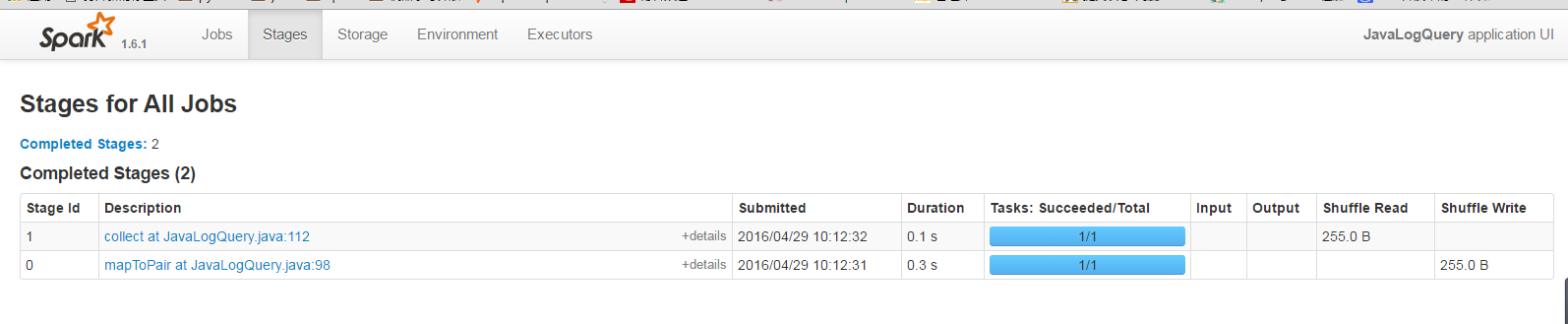
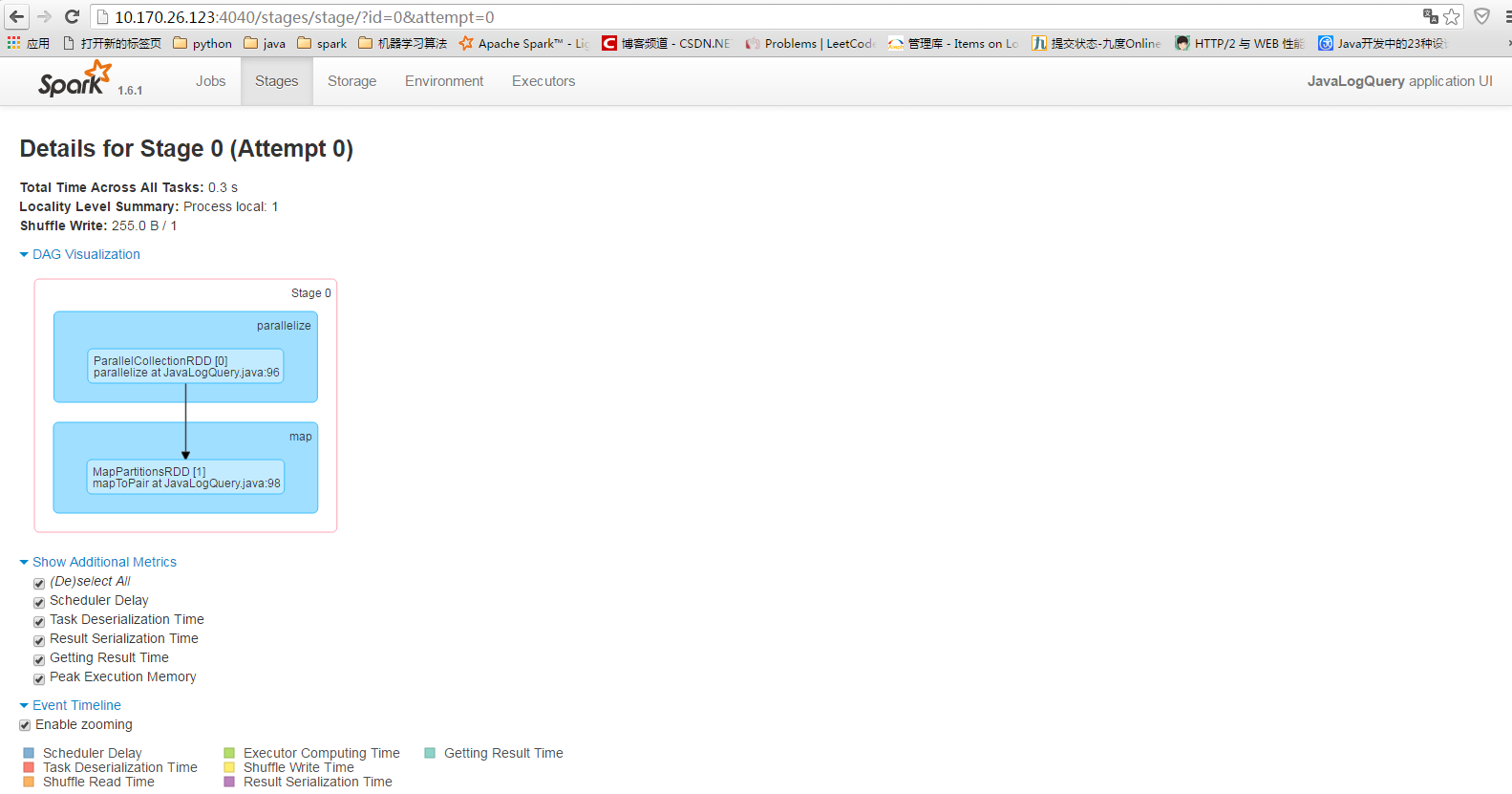
開始執行job
16/04/29 10:12:31 INFO SparkContext: Starting job: collect at JavaLogQuery.java:112
16/04/29 10:12:31 INFO DAGScheduler: Registering RDD 1 (mapToPair at JavaLogQuery.java:98)
16/04/29 10:12:31 INFO DAGScheduler: Got job 0 (collect at JavaLogQuery.java:112) with 1 output partitions
16/04/29 10:12:31 INFO DAGScheduler: Final stage: ResultStage 1 (collect at JavaLogQuery.java:112)
16/04/29 10:12:31 INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
16/04/29 10:12:31 INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
16/04/29 10:12:31 INFO DAGScheduler: Submitting ShuffleMapStage 0 (MapPartitionsRDD[1] at mapToPair at JavaLogQuery.java:98), which has no missing parents
16/04/29 10:12:31 WARN SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
16/04/29 10:12:31 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 3.1 KB, free 3.1 KB)
16/04/29 10:12:31 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1897.0 B, free 5.0 KB)
16/04/29 10:12:31 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:36394 (size: 1897.0 B, free: 517.4 MB)
16/04/29 10:12:31 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1006
16/04/29 10:12:31 INFO DAGScheduler: Submitting 1 missing tasks from ShuffleMapStage 0 (MapPartitionsRDD[1] at mapToPair at JavaLogQuery.java:98)
16/04/29 10:12:31 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
16/04/29 10:12:31 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 3033 bytes)
16/04/29 10:12:31 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
16/04/29 10:12:32 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 1158 bytes result sent to driver
16/04/29 10:12:32 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 320 ms on localhost (1/1)
16/04/29 10:12:32 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
16/04/29 10:12:32 INFO DAGScheduler: ShuffleMapStage 0 (mapToPair at JavaLogQuery.java:98) finished in 0.349 s
16/04/29 10:12:32 INFO DAGScheduler: looking for newly runnable stages
16/04/29 10:12:32 INFO DAGScheduler: running: Set()
16/04/29 10:12:32 INFO DAGScheduler: waiting: Set(ResultStage 1)
16/04/29 10:12:32 INFO DAGScheduler: failed: Set()
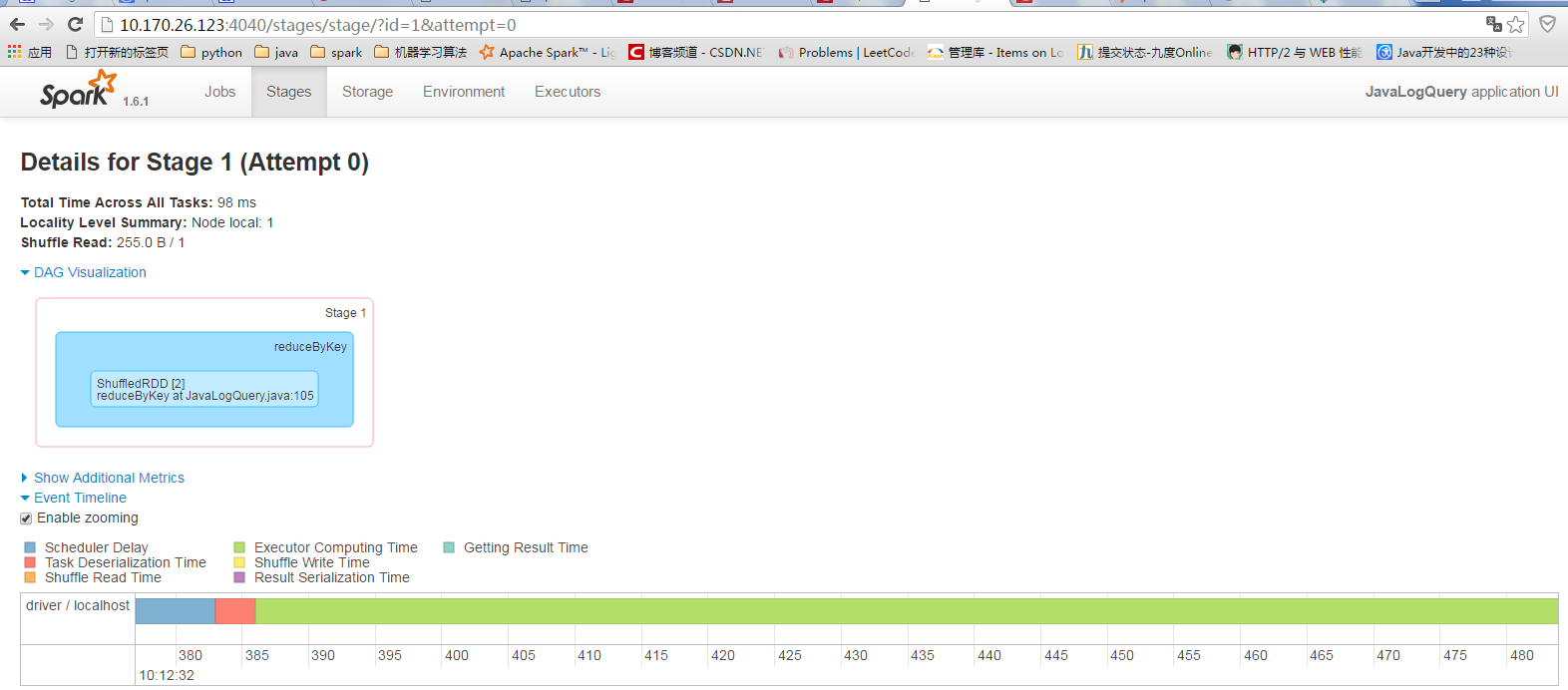
16/04/29 10:12:32 INFO DAGScheduler: Submitting ResultStage 1 ***(ShuffledRDD[2] at reduceByKey at JavaLogQuery.java:105), which has no missing parents***
16/04/29 10:12:32 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 2.9 KB, free 7.9 KB)
16/04/29 10:12:32 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 1746.0 B, free 9.6 KB)
16/04/29 10:12:32 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:36394 (size: 1746.0 B, free: 517.4 MB)
16/04/29 10:12:32 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006
16/04/29 10:12:32 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (ShuffledRDD[2] at reduceByKey at JavaLogQuery.java:105)
16/04/29 10:12:32 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
16/04/29 10:12:32 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, partition 0,NODE_LOCAL, 1894 bytes)
16/04/29 10:12:32 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
16/04/29 10:12:32 INFO ShuffleBlockFetcherIterator: Getting 1 non-empty blocks out of 1 blocks
16/04/29 10:12:32 INFO ShuffleBlockFetcherIterator: Started 0 remote fetches in 16 ms
16/04/29 10:12:32 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 1449 bytes result sent to driver
16/04/29 10:12:32 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 107 ms on localhost (1/1)
16/04/29 10:12:32 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
16/04/29 10:12:32 INFO DAGScheduler: ResultStage 1 (collect at JavaLogQuery.java:112) finished in 0.108 s
16/04/29 10:12:32 INFO DAGScheduler: Job 0 finished: collect at JavaLogQuery.java:112, took 0.850227 s
(10.10.10.10,"FRED",GET http://images.com/2013/Generic.jpg HTTP/1.1) bytes=621 n=2
16/04/29 10:12:56 INFO BlockManagerInfo: Removed broadcast_1_piece0 on localhost:36394 in memory (size: 1746.0 B, free: 517.4 MB)
結束
16/04/29 10:12:56 INFO BlockManagerInfo: Removed broadcast_1_piece0 on localhost:36394 in memory (size: 1746.0 B, free: 517.4 MB)
16/04/29 10:16:13 INFO ContextCleaner: Cleaned accumulator 2
16/04/29 10:16:13 INFO BlockManagerInfo: Removed broadcast_0_piece0 on localhost:36394 in memory (size: 1897.0 B, free: 517.4 MB)
16/04/29 10:16:13 INFO ContextCleaner: Cleaned accumulator 1
16/04/29 10:24:29 WARN QueuedThreadPool: 5 threads could not be stopped
16/04/29 10:24:29 INFO SparkUI: Stopped Spark web UI at http://10.170.26.123:4040
16/04/29 10:24:29 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
16/04/29 10:24:29 INFO MemoryStore: MemoryStore cleared
16/04/29 10:24:29 INFO BlockManager: BlockManager stopped
16/04/29 10:24:29 INFO BlockManagerMaster: BlockManagerMaster stopped
16/04/29 10:24:30 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
16/04/29 10:24:30 INFO SparkContext: Successfully stopped SparkContext
16/04/29 10:24:30 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
16/04/29 10:24:30 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
16/04/29 10:24:30 INFO RemoteActorRefProvider$RemotingTerminator: Remoting shut down.- 總結
java的程式碼實現spark API雖然程式碼冗餘很多,但是很清楚顯示了spark的執行過程,先比於scala的程式碼,較為清楚,而且java的程式碼和其他的專案結合效果可能好些。
相關推薦
Spark實踐-日誌查詢
環境 win 7 jdk 1.7.0_79 (Oracle Corporation) scala version 2.10.5 spark 1.6.1 詳細配置: Spark Properties spark.app.id
spark 處理網路日誌 查詢pv uv例項
這裡我們先理解一下spark處理資料的流程,由於spark 有standalone,local,yarn等多種模式,每種模式都有不同之處,但是總體流程都是一樣的,大致就是客戶端向叢集管理者提交作業,生成有向無環圖,圖中的內容包括分成幾個stage,每個stage有幾個task
17_慢日誌查詢
查詢 ros -- slow microsoft -s var query pan 什麽是慢日誌查詢? -- 配置自動記錄慢日誌 -- 查看慢日誌 如何配置慢日誌? 默認關閉 set_query_log = ON
linux具體時間段日誌查詢
方法 文件 rep 命令 時間 inux access log日誌 實現 查看某個時間段的日誌(比如access.log日誌),如何實現? 方法有很多種,比如我要看查的時間是2018年2月5號--2月6號的日誌吧。 (1).用sed命令,格式為:sed -n ‘/起始時間/
個推 Spark實踐教你繞過開發那些“坑”
個推 spark Spark作為一個開源數據處理框架,它在數據計算過程中把中間數據直接緩存到內存裏,能大大地提高處理速度,特別是復雜的叠代計算。Spark主要包括SparkSQL,SparkStreaming,Spark MLLib以及圖計算。Spark核心概念簡介 1、RDD即彈性分布式數據集,通過
kibana 日誌查詢
err -h 查詢 handler iba mage rdquo 分享 info type:"order-handler-wcf-error" AND message:"代扣失敗" 多查詢的連接“AND”一定要大寫
MySQL---正確使用索引、limit分頁、執行計劃、慢日誌查詢
ngs 數據庫 配置 服務 esc 操作 com ora 條件 正確使用索引 數據庫表中添加索引後確實會讓查詢速度起飛,但前提必須是正確的使用索引來查詢,如果以錯誤的方式使用,則即使建立索引也會不奏效。即使建立索引,索引也不會生效: 1 - like ‘%xx‘ 2
Spark 實踐
1.1 避免使用 GroupByKey 讓我們看一下使用兩種不同的方式去計算單詞的個數,第一種方式使用 reduceByKey, 另外一種方式使用 groupByKey: val words = Array("one", "two", "two", "three", "thr
日誌php-fpm慢日誌查詢
專案用php開發,在生產執行的過程中,應該一段時間監測下php指令碼執行狀態,哪些php程序速度太慢,有哪些錯誤日誌。 問:如何來檢視檢測比較慢的php指令碼呢? 答:檢視php-fpm慢日誌。
ELKStack分散式日誌查詢分析伺服器安裝及配置(ElasticSearch、Logstash、Kibana、Redis)
ELK對於沒有接觸的來說,並沒有一般的服務那麼容易安裝和使用,不過也沒有那麼難,elk一般作為日誌分析套裝工具使用。logs由logstash輸 入,logstash通過配置檔案對日誌做過濾、匹配,就是用來分析日誌的,輸出到elasticsearch,所以他的配置需要和日誌相匹配。 elas
spark core 日誌遮蔽
(1)切換logback日誌: 刪除slf4j-log4j相關jar包,增加ch.qos.logback.core_1.0.0.jar及ch.qos.logback.classic_1.0.0.jar (2)配置logback.xml並儲存至conf目錄: &
阿里雲釋出鏈路追蹤服務Tracing Analysis,從此告別告別日誌查詢
近日,在杭州雲棲大會上,阿里雲釋出了鏈路追蹤服務Tracing Analysis,成本是自建鏈路追蹤系統的1/5或更少,可為分散式應用的開發者提供完整的呼叫鏈路還原、呼叫請求量統計、鏈路拓撲、應用依賴分析等工具,幫助開發者快速分析和診斷分散式應用架構下的效能瓶頸,提高微服務時代下的開發診斷效
解決mysql binlog日誌查詢不出語句的問題
當bin-log的模式設定為 row時 不僅日誌長得快 並且檢視執行的sql時 也稍微麻煩一點:1.干擾語句多;2生成sql的編碼需要解碼。 binlog_format=row 直接mysqlbinlog出來的 檔案 執行sql部分的sql顯示為base64編碼
Spark學習筆記(9)—— Spark IP位置查詢
1 資料來源 ip.txt 1.0.1.0|1.0.3.255|16777472|16778239|亞洲|中國|福建|福州||電信|350100|China|CN|119.306239|26.07530
AOP實踐-日誌記錄
AOP實踐-自定義註解實現日誌記錄 專案環境springboot spring AOP預設是使用AspectJ的註解 https://www.eclipse.org/aspectj/ 1.引入jar包 <dependency>
Kibana日誌查詢表示式
Kibana 日誌查詢 kibana 以下示例展示kibana基礎查詢語法 基礎字串匹配(全文檢索) 實用指數 5 例如想查詢某個IP,直接輸入ip即可 "192.168.163.104" 知道日誌某段內容可直接放到kibana中直接查詢 "根據小程式co
檢視spark任務日誌
登入resource manager所在伺服器, 進入/var/log/hadoop-yarn/yarn tail rm-audit.log 讀取日誌,找到如下內容: 2018-10-31 07:11:27,148 INFO resourcemanager.RMAud
Spark實踐 -- 夜出顧客服務分析
文章目錄 業務需求 業務實現 第一版 只統計了晚上出現的顧客 第二版 對白天進店了的顧客形成列表然後用於過濾 第三版 業務需求 最近做的24小時書店大資料平臺中的一個需求:
spark讀取日誌檔案,把RDD轉化成DataFrame
一、先開啟Hadoop和spark 略 二、啟動spark-shell spark-shell --master local[2] --jars /usr/local/src/spark-1.6.1-bin-hadoop2.6/libext/com.mysql.jdbc
IDEA 本地開發 Spark Streming 日誌輸出太多影響檢視輸出 INFO改為ERRO
在本地開發測試Spark Streaming 的時候 日誌資訊輸出太多,不方便檢視資料流的輸出 方法一 val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCo