
基於內容的推薦系統
主要參考:
論文The Krakatoa Chronicle - An Interactive, Personalized, Newspaper on the Web
1、首先舉一個具體例項:給使用者推薦電影(相似:新聞/淘寶/旅館等等);
內容:使用者及使用者給電影的評分,組成的矩陣形式如下:
(實際情況中也是包含大量預設值的)

下面是針對如上實際問題進行的一些概念、理論及演算法的研究:
以新聞推薦為例進行具體探討:
1、屬性空間:就是詞彙表;
2、如何代表一個使用者偏好:
隱性:讀、點選、儲存、收藏等等;
顯性:頂、踩、評論等等;
3、如何表示一篇文章:文章中有很多詞,如何表示每個詞的對於文章代表性權重的大小,即如何識別keywords:
Keywords有兩個要素:一個是這些詞在同一個文件出現頻率大;另一個是這些詞在其他文件出現頻率不大(防止定冠詞等通用詞的普遍性)
1)TFIDF:Term Frequency * Inverse Document Frequency
Term frequency: Number of occurrences of a term in the document
Inverse Document frequency: but not appear in other documents:log (documents / documents with term) (分母:包含這些詞的文件個數,其越大,最後TFIDF乘積越小)
4、有了文章詞向量及使用者偏好詞向量,如何找到他們之間的相似性,也即這篇文章與這個使用者喜好的相關性大小的度量:
1)首先考慮一個新聞的通用價值大小的恆量(也即對所有使用者來說他的價值大小):
同樣包括兩個方面屬性:
一個是其關注度/話題熱度(頂/踩個數)的表示;
另一個是其時效性的表示(也就是越新其價值越大);
其計算公式如下(這只是其中一種比較好的度量方式,其他度量方法有機會再與大家分享學習):
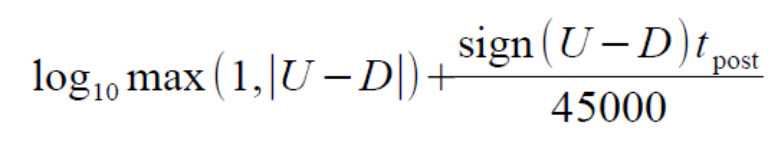
其中U、D表示頂和踩的個數(取log的理解:越往後頂和踩的價值越小,如人云亦云等等),t_post表示時間;
2)相似性度量演算法:
有了如上新聞通用價值的恆量,那麼其值乘上Similarity (this news, this user),就是最終的推薦結果的度量;下面來看一下計算similarity的演算法:
1、集合A、B之間的similarity:
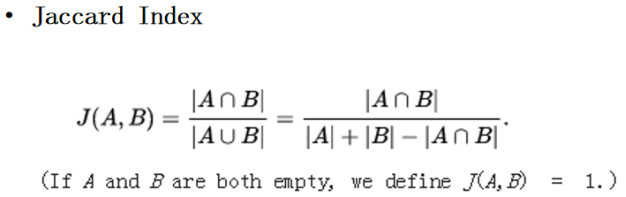
2、歐式距離:向量p、q之間的similarity:
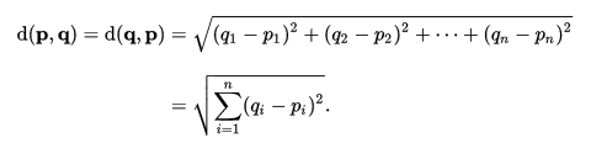
3、Cosine Similarity:向量A、B計算cos值
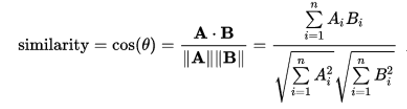
4、Pearson Correlation Coefficient:均值化
計算使用者a及u之間的喜好similarity:
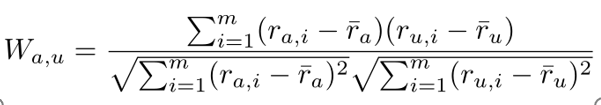
減去均值的原理:比如電影推薦,根據打過分的人及其看過的打分的電影、以及本人以前打過分的人電影,根據人與人之間的喜歡進行推薦預測,如下圖所示:

可以看出alice和user1其之間的品味是差不多的,但是alice偏向於打高分,而user1偏向於打低分,當各自減去自己的均值之後,那麼就可以發現其實他們之間的喜好關係是非常密切的。
5、Pearson Correlation Coefficient (expressed by z-score):標準化

6、Spearman’s rank correlation coefficient:
根據如下一個具體例項解釋一下:計算V1、V2之間的similarity,按照各自其值先進行排序rank,然後按照排序之後的順序序號向量在計算Pearson Correlation Coefficient:
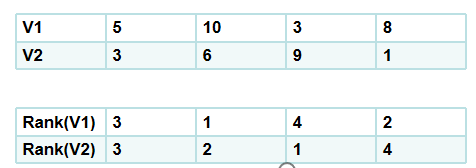
為什麼取rank,因為不同特徵之間其值相差可能很大,如房屋價格決定因素:臥室數量和房屋面積,而房屋面積相對於臥室數量是非常龐大的一個數,直接各自計算在加和將導致各特徵直接權重比例嚴重失調;所以先進行rank處理,相當於正則化處理;
一些挑戰和不足:首先這裡主要是基於文字內容,沒有利用的實際情況中可能地圖片、語言等相關資訊;另一個這只是基於以前的個人偏好,推薦的只是一些以前item的替代品,而不是一些互補性的item難有驚喜之餘(如看過甚至已經買了手機但還是一直推薦手機,這是現在大多數推薦系統的通病,包括天貓/京東等等大公司)