
hadoop put內部呼叫,hdfs寫檔案流程
HDFS是一個分散式檔案系統,在HDFS上寫檔案的過程與我們平時使用的單機檔案系統非常不同,從巨集觀上來看,在HDFS檔案系統上建立並寫一個檔案,流程如下圖(來自《Hadoop:The Definitive Guide》一書)所示:
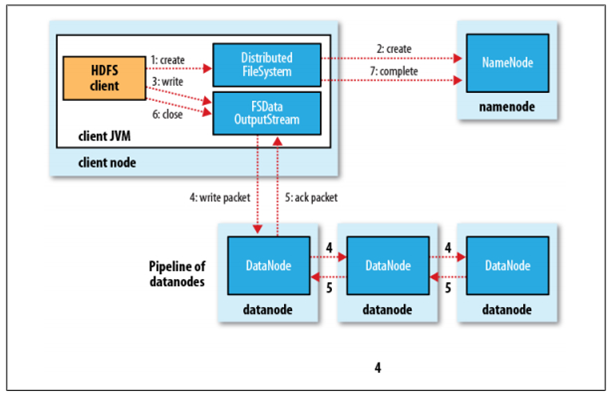
具體過程描述如下:
- Client呼叫DistributedFileSystem物件的create方法,建立一個檔案輸出流(FSDataOutputStream)物件
- 通過DistributedFileSystem物件與Hadoop叢集的NameNode進行一次RPC遠端呼叫,在HDFS的Namespace中建立一個檔案條目(Entry),該條目沒有任何的Block
- 通過FSDataOutputStream物件,向DataNode寫入資料,資料首先被寫入FSDataOutputStream物件內部的Buffer中,然後資料被分割成一個個Packet資料包
- 以Packet最小單位,基於Socket連線傳送到按特定演算法選擇的HDFS叢集中一組DataNode(正常是3個,可能大於等於1)中的一個節點上,在這組DataNode組成的Pipeline上依次傳輸Packet
- 這組DataNode組成的Pipeline反方向上,傳送ack,最終由Pipeline中第一個DataNode節點將Pipeline ack傳送給Client
- 完成向檔案寫入資料,Client在檔案輸出流(FSDataOutputStream)物件上呼叫close方法,關閉流
- 呼叫DistributedFileSystem物件的complete方法,通知NameNode檔案寫入成功
下面程式碼使用Hadoop的API來實現向HDFS的檔案寫入資料,同樣也包括建立一個檔案和寫資料兩個主要過程,程式碼如下所示:
01 |
static String[]
contents = new String[]
{ |
02 |
"aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa", |
03 |
"bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb", |
04 |
"cccccccccccccccccccccccccccccccccccccccccccccccccccccccccc", |
05 |
"dddddddddddddddddddddddddddddddd", |
06 |
"eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee", |
07 |
}; |
08 |
09 |
public static void main(String[]
args) { |
11 |
Path
path = new Path(file); |
12 |
Configuration
conf = new Configuration(); |
13 |
FileSystem
fs = null; |