
hadoop寫檔案流程分析
1.主要概念
1.1 NameNode(NN):
HDFS系統核心元件,負責分散式檔案系統的名字空間管理、INode表的檔案對映管理。如果不開啟備份/故障恢復/Federation模式,一般的HDFS系統就只有1個NameNode,當然這樣是存在單點故障隱患的。
NN管理兩個核心的表:檔案到塊序列的對映、塊到機器序列的對映。
第一個表儲存在磁碟中,第二表在NN每次啟動後重建。
1.2 NameNodeServer(NNS):
負責NN和其它元件的通訊介面的開放(IPC、http)等。
NN通過客戶端協議(ClientProtocol)和客戶端通訊,通過資料節點協議(DataNodeProtocol)和DN通訊。
1.3 FSNameSystem:
管理檔案系統相關,承擔了NN的主要職責。
1.4 DataNode(DN):
分散式檔案系統中存放實際資料的節點,儲存了一系列的檔案塊,一個DFS部署中通常有許多DN。
DN和NN,DN和DN,DN和客戶端都通過不同的IPC協議進行互動。
通常,DN接受來自NN的指令,比如拷貝、刪除檔案塊。
客戶端在通過NN獲取了檔案塊的位置資訊後,就可以和DN直接互動,比如讀取塊、寫入塊資料等。
DN節點只管理一個核心表:檔案塊到位元組流的對映。
在DN的生命週期中,不斷地和NN通訊,報告自己所儲存的檔案塊的狀態,NN不直接向DN通訊,而是應答DN的請求,比如在DN的心跳請求後,回覆一些關於複製、刪除、恢復檔案塊的命令(comands)。
DN和外界通訊的介面會報告給NN,想和此DN互動的客戶端或其它DN可以通過和NN通訊來獲取這一資訊。
1.5 Block
檔案塊,hadoop檔案系統的原語,hadoop分散式檔案系統中儲存的最小單位。一個hadoop檔案就是由一系列分散在不同的DataNode上的block組成。
1.6 BlockLocation
檔案塊在分散式網路中的位置,也包括一些塊的元資料,比如塊是否損壞、塊的大小、塊在檔案中的偏移等。
1.7 DFSClient
分散式檔案系統的客戶端,使用者可以獲取一個客戶端例項和NameNode及DataNode互動,DFSClient通過客戶端協議和hadoop檔案系統互動。
1.8 Lease
租約,當客戶端建立或開啟一個檔案並準備進行寫操作,NameNode會維護一個檔案租約,以標記誰正在對此檔案進行寫操作。客戶端需要定時更新租約,否則當租約過期,NN會關閉檔案或者將檔案的租約交給其它客戶端。
1.9 LeaseRenewer
續約管控執行緒,當一個DFSClient呼叫申請租約後,如果此執行緒尚未啟動,則啟動,並定期向NameNode續約。
2.建立檔案流程分析
建立一個名為tmpfile1.dat的檔案,主要流程如下:
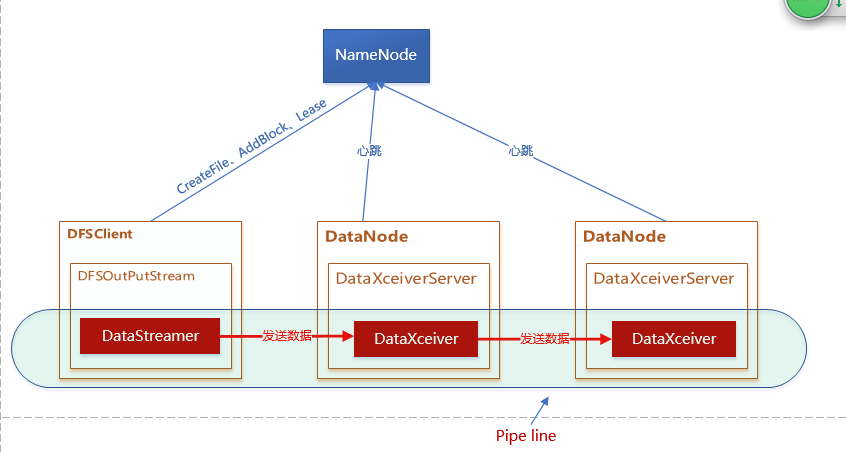
2.1 傳送建立檔案的請求(CreateFile)
客戶端向NN發起請求,獲取檔案資訊,NN會在快取中查詢是否存在請求建立的檔案項(file entry),如果沒找到,就在NameSystem中建立一個新的檔案項:
塊管理器(BlockManager)檢查複製因子是否在範圍內,如果複製因子過小或過大就會異常。
同時會進行許可權驗證、加密、安全模式檢測(如果在安全模式不能建立檔案)等,並記錄操作日誌和事件日誌,然後向客戶端返回檔案狀態。
2.2 申請檔案租用權(beginFileLease)
客戶端取得檔案狀態後,對檔案申請租用(lease),如果租用過期,客戶端將無法再繼續對檔案進行訪問,除非進行續租。
2.3 資料流管控執行緒啟動(DataStreamer & ResponseProcessor)
DataStreamer執行緒負責資料的實際傳送:
當資料佇列(Data Queue)為空時,會睡眠,並定期甦醒以檢測資料佇列是否有新的資料需要傳送、Socket套接字是否超時、是否繼續睡眠等狀態。
ResponseProcessor負責接收和處理pipeline下游傳回的資料接收確認資訊pipelineACK。
2.4 傳送新增塊申請並初始化資料管道(AddBlock & Setup Pipeline)
當有新的資料需要傳送,並且塊建立階段處於PIPELINE_SETUP_CREATE,DataStreamer會和NameNode通訊,呼叫AddBlock方法,通知NN建立、分配新的塊及位置,NN返回後,初始化Pipeline和傳送流。
2.5 DataNode資料接收服務執行緒啟動(DataXceiverServer & DataXceiver)
當DataNode啟動後,其內部的DataXceiverServer元件啟動,此執行緒管理向其所屬的DN傳送資料的連線建立工作,新連線來時,DataXceiverServer會啟動一個DataXceiver執行緒,此執行緒負責流向DN的資料接收工作。
2.6 在Pipeline中處理資料的傳送和接收
客戶端在獲取了NameNode分配的檔案塊的網路位置之後,就可以和存放此塊的DataNode互動。
客戶端通過SASL加密方式和DN建立連線,並通過pipeline來發送資料。
2.6.1 從pipeline接收資料
pipeline由資料來源節點、多個數據目的節點組成,請參考上面的流程圖。位於pipeline中的第一個DataNode會接收到來自客戶端的資料流,其內部DataXceiver元件,通過讀取操作型別(OP),來區分進行何種操作,如下所示:
protected final void processOp(Op op) throws IOException {
switch(op) {
case READ_BLOCK:
opReadBlock();
break;
//本例中將會使用WRITE_BLOCK指令
case WRITE_BLOCK:
opWriteBlock(in);
break;
//略...
default:
throw new IOException("Unknown op " + op + " in data stream");
}
}
如果OP是WRITE_BLOCK,呼叫寫資料塊的方法,此方法會根據資料來源是客戶端還是其他DataNode、塊建立的階段等條件進行不同的邏輯。
2.6.2 資料在pipeline中流動
在本例中,第一個收到資料的DN會再啟動一個blockReceiver執行緒,以接收實際的塊資料,在本地儲存了塊資料後,其負責向pipeline中的後續DN繼續傳送塊資料。每次向下遊DN節點發送資料,標誌著資料目的節點的targets陣列都會排除自身,這樣,就控制了pipeline的長度。
下游收到塊資料的DN會向上遊DN或者客戶端報告資料接收狀態。
這種鏈式或者序列化的資料轉移方式,就像資料在管道中從上游流向下游,所以這種方式稱作pipeline。2.6.3 pipeline的生命週期
在本例中:
DataStreamer執行緒啟動後,pipeline進入PIPELINE_SETUP_CREATE階段;
資料流初始化後,pipeline進入DATA_STREAMING階段;
資料傳送完畢後,pipeline進入PIPELINE_CLOSE階段。客戶端在DataStreamer執行緒啟動後,同時啟動了一個ResponseProcessor執行緒,此執行緒用於接收pipeline中來自下游節點的資料接收狀態報告pipelineACK,同時此執行緒和DataStreamer執行緒協調管理pipeline狀態。
當DataStreamer向pipeline傳送資料時,會將傳送的資料包(packet)從資料佇列(Data Queue)中移除,並加入資料確認佇列(Ack Queue):
//DataStreamer傳送資料後,將dataQueue的第一個元素出隊,並加入ackQueue
one = dataQueue.getFirst();
dataQueue.removeFirst();
ackQueue.addLast(one);
而當ResponseProcessor收到下游的pipelineAck後,據此確認資訊來判斷pipeline狀態,是否需要重置和重新調整。如果確認資訊是下游節點資料接收成功了,就將確認佇列(AckQueue)的第一個資料包刪除。//ResponseProcessor收到成功的Ack,就將ackQueue的第一個包移除
lastAckedSeqno = seqno;
ackQueue.removeFirst();
dataQueue.notifyAll();
通過這樣的方式,DataStreamer可以確認資料包是否傳送成功,也可以確認全部的資料包是否已經發送完畢。顯然,當AckQueue空了,並且已經發送的資料包是塊裡的最後一個包,資料就傳送完畢了。
傳送完畢的判斷如下所示:
if (one.lastPacketInBlock) {
// wait for all data packets have been successfully acked
synchronized (dataQueue) {
while (!streamerClosed && !hasError &&
ackQueue.size() != 0 && dfsClient.clientRunning) {
try {
// wait for acks to arrive from datanodes
dataQueue.wait(1000);
} catch (InterruptedException e) {
DFSClient.LOG.warn("Caught exception ", e);
}
}
}
if (streamerClosed || hasError || !dfsClient.clientRunning) {
continue;
}
//在沒有錯誤的情況下,AckQueue為空,並且包one是block的最後一個包,資料就傳送完了
stage = BlockConstructionStage.PIPELINE_CLOSE;
}
2.7 傳送檔案操作完成請求(completeFile)
客戶端向NameNode傳送completeFile請求:
NN收到請求後,驗證塊的BlockPoolId是否正確,接著對操作許可權、檔案寫鎖(write lock)、安全模式、租約、INode是否存在、INode型別等等進行驗證,最後記錄操作日誌並返回給客戶端。
2.8 停止檔案租約(endFileLease)
客戶端在完成檔案寫操作後,呼叫leaseRenewer(LR)例項,從LR管理的續約檔案表中刪除此檔案,表明不再更新租約,一段時間後,租約在NN端自然失效。
總結:
在向DataNode寫資料的時候,Client需要知道它需要知道自身的資料要寫往何處,在茫茫Cluster 中,DataNode成百上千,寫到DataNode的那個Block塊下,是Client需要清楚的。在通過create建立一個空檔案時,輸出流會向 NameNode申請Block的位置資訊,在拿到新的Block位置資訊和版本號後,輸出流就可以聯絡DataNode節點,通過寫資料流建立資料流管 道,輸出流中的資料被分成一個個檔案包,並最終打包成資料包發往資料流管道,流經管道上的各個DataNode節點,並持久化。
Client在寫資料的檔案副本預設是3份,換言之,在HDFS叢集上,共有3個DataNode節點會儲存這份資料的3個副本,客戶端在傳送 資料時,不是同時發往3個DataNode節點上寫資料,而是將資料先發送到第一個DateNode節點,然後,第一個DataNode節點在本地儲存數 據,同時推送資料到第二個DataNode節點,依此類推,直到管道的最後一個DataNode節點,資料確認包由最後一個DataNode產生,並逆向 回送給Client端,在沿途的DataNode節點在確認本地寫入成功後,才會往自己的上游傳遞應答資訊包。這樣做的好處總結如下:
分攤寫資料的流量:由每個DataNode節點分攤寫資料過程的網路流量。
降低功耗:減小Client同時傳送多份資料到DataNode節點造成的網路衝擊。
另外,在寫完一個Block後,DataNode節點會通過心跳上報自己的Block資訊,並提交Block資訊到NameNode儲存。當 Client端完成資料的寫入之後,會呼叫close()方法關閉輸出流,在關閉之後,Client端不會在往流中寫資料,因而,在輸出流都收到應答包 後,就可以通知NameNode節點關閉檔案,完成一次正常的寫入流程。
在寫資料的過程當中,也是有可能出現節點異常。然而這些異常資訊對於Client端來說是透明的,Client端不會關心寫資料失敗後 DataNode會採取哪些措施,但是,我們需要清楚它的處理細節。首先,在發生寫資料異常後,資料流管道會被關閉,在已經發送到管道中的資料,但是還沒 有收到確認應答包檔案,該部分資料被重新新增到資料流,這樣保證了無論資料流管道的哪個節點發生異常,都不會造成資料丟失。而當前正常工作的 DateNode節點會被賦予新的版本號,並通知NameNode。即使,在故障節點恢復後,上面只有部分資料的Block會因為Blcok的版本號與 NameNode儲存的版本號不一致而被刪除。之後,在重新建立新的管道,並繼續寫資料到正常工作的DataNode節點,在檔案關閉 後,NameNode節點會檢測Block的副本數是否達標,在未達標的情況下,會選擇一個新的DataNode節點並複製其中的Block,建立新的副 本。這裡需要注意的是,DataNode節點出現異常,只會影響一個Block的寫操作,後續的Block寫入不會收到影響