Large Pose 3D Face Reconstruction 文章理解
Large Pose 3D Face Reconstruction from a Single Image via Direct Volumetric 文章的一點點理解梳理
寫在前面
因為我比較弱,在機器學習和三維重建方面都算是新手,所以並不是很理解這篇文章,只是梳理下文章中的模型結構,當做筆記,我相信大家更加優秀,應該能理解的層次比我更深。我這裡梳理的順序按照由小模組向大模組梳理。
Residual Module
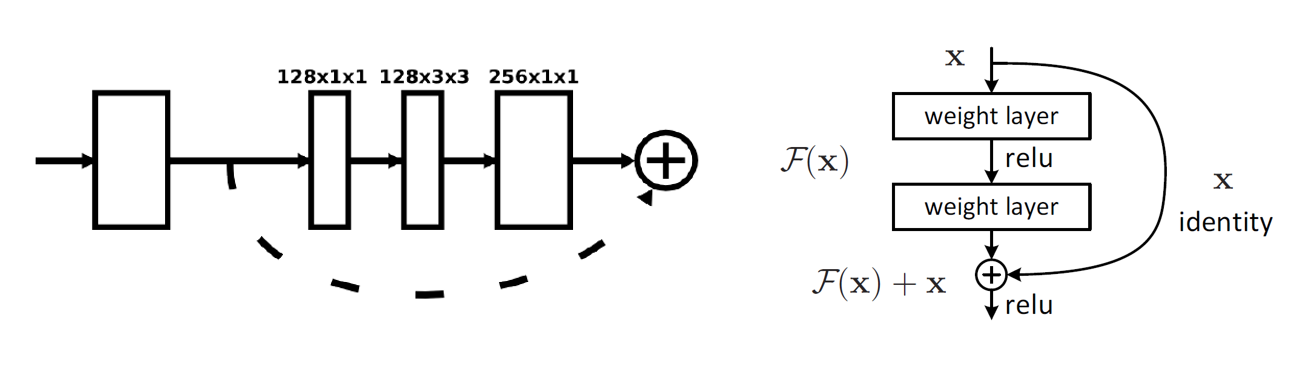
文章中稱為 residual module ,引用的文章中稱為 Residual Learning,是微軟發表的文章,中文常翻譯為殘差學習,源自論文Deep Residual Learning for Image Recognition
他第一行是卷積路,由三個核尺度不同的卷積串聯而成;第二行是跳級路,只包含一個核尺度為1的卷積層。
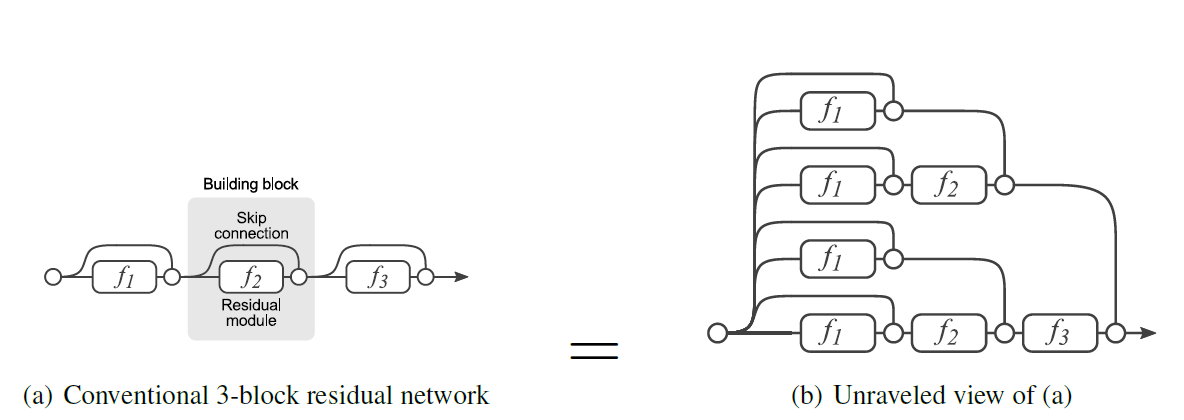
對於多個殘差學習模組串聯的情況也可以展開為如圖的效果。
Hourglass Module
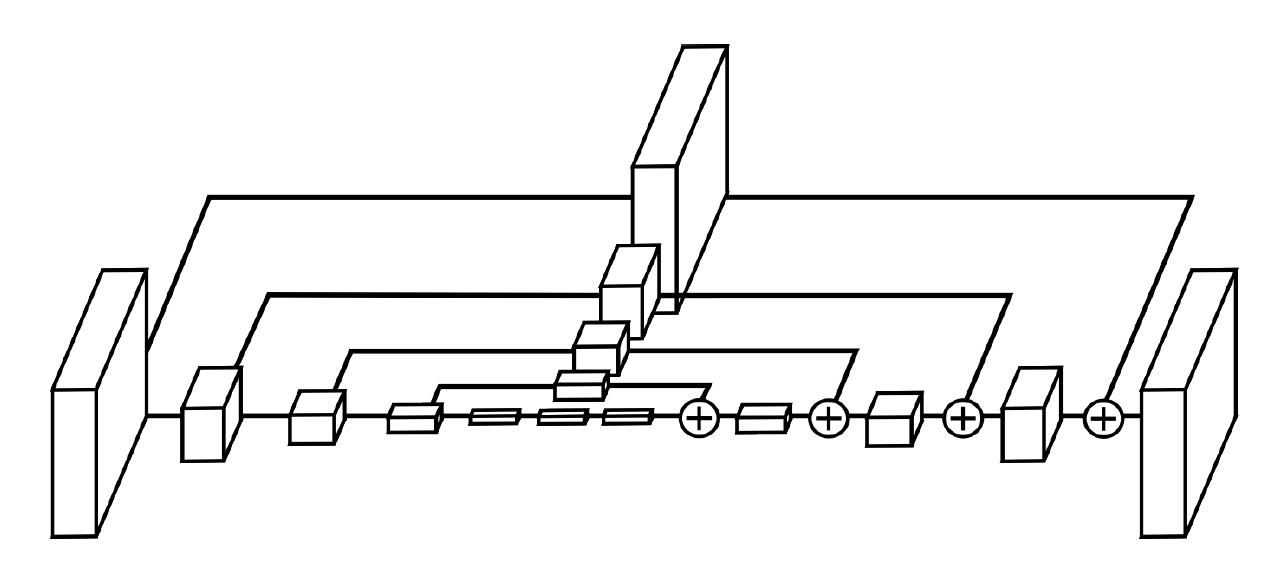
Hourglass Module如上圖所示,是Stacked Hourglass Networks for Human Pose Estimation 文章中的一個獨立子模組,圖中每一個立方體都是一個Residual Module。
可以說這篇文章就是直接用Hourglass module堆出來的了,想要理解這個模型,可能必須要讀一下這個模型的出處。這裡附一個文章
VRN
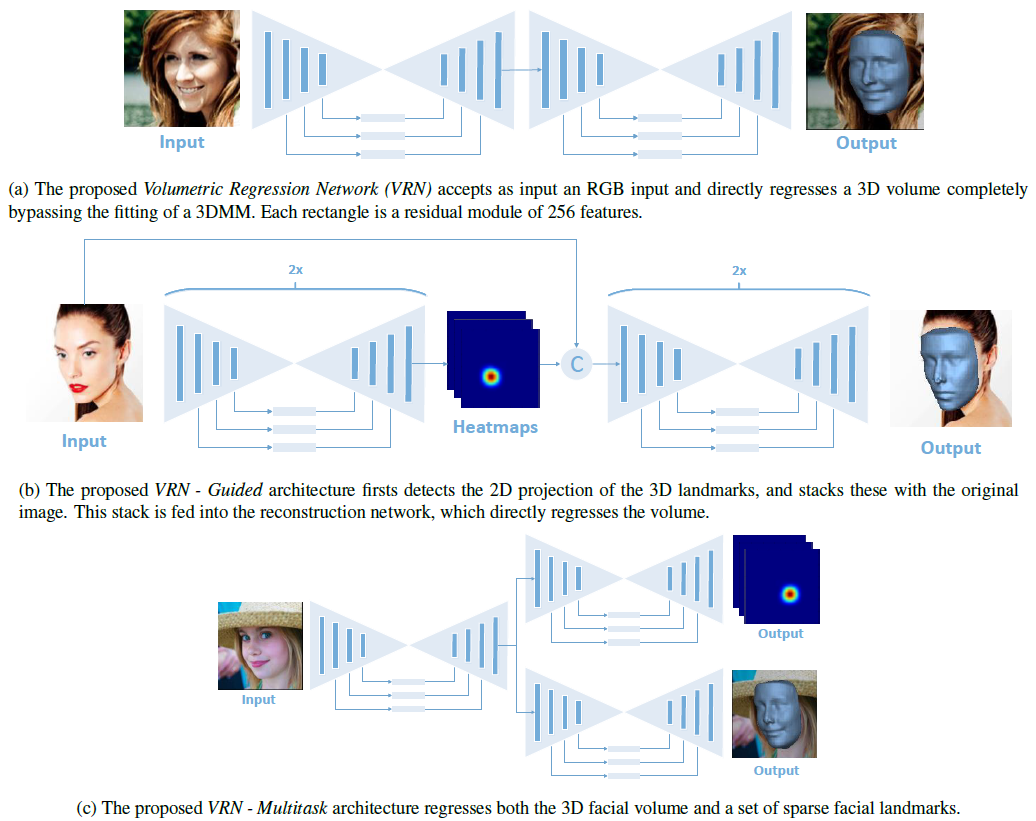
Volumetric Regression Network(VRN) 本文作者使用的模型,由多個沙漏模型組合在一起形成。
- VRN模型使用兩個沙漏模組堆積而成,並且沒有使用hourglass的間接監督結構。
- VRN-guided 模型是使用了Stacked Hourglass Networks for Human Pose Estimation 的工作作為基礎,在前半部分使用兩個沙漏模組用來獲取68個標記點,後半部分使用兩個沙漏模組,以一張RGB圖片和68個通道(每個通道一個標記點)的標記點作為輸入資料。
- VRN-Multitask 模型,用了三個沙漏模組,第一個模組後分支兩個沙漏模組,一個生成三維模型,一個生成68個標記點。