
H.264-AVC視訊編碼原理及實現
1.1視訊
時間連續的影象序列稱為視訊。

1.2相關性
影象本身具有的自己特性,影象與影象之間具有一定的關聯性。
時間相關性:一幅影象中的大部分元素都同樣存在於其相鄰的影象(前後)之中。
空間相關性:一幅影象中相鄰畫素之間具有相關性。
統計相關性:影象在儲存的過程中,通過不同的統計方法,可以得到比原始資料較少的資料。
試驗表明,人眼對於影象中的亮度分量(明暗)最敏感,對於影象中的色度(顏色)分量相對來講敏感度相差。

DTS:Decoder Time Stamp,用來表示影象的解碼時間。
PTS:Presentation Time Stamp,用來表示影象的顯示時間。
引入這兩變數主要是因為,在存在雙向參考幀時,影象在編碼影象的順序和編碼輸出的順序不同。


1.5 重構幀
在編碼的過程中,需要對已經編碼的影象進行解碼,解碼後的影象稱作重構幀(restructure frame)。重構幀將作為其後編碼影象的參考幀。
1.6 逐行和隔行
逐行比較好理解,假設一幀影象的大小是704x576,那麼逐行的話就是576行。
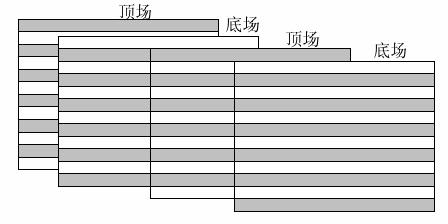
隔行影象,是早期電視訊號中引入的概念,把一幀影象分為上下兩場,兩場影象在時間上具有先後,但傳輸時同時傳送到顯示端,顯示端在顯示按各自的時間分開進行顯示。該方式主要是利用了人眼的餘輝效應,通過隔行顯示,提高了顯示的流暢性。

2.1
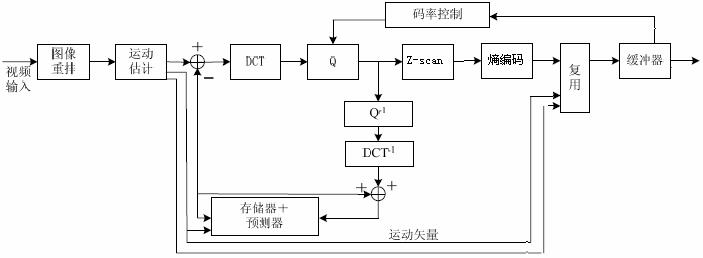
目前常用的視訊編碼演算法基本上都是以運動估計和以塊為單位的時-頻變換為基礎。
運動估計,處理了相鄰視訊幀中的相同部分。
時-頻變換,使得資料塊的能量更加集中地分佈。常用的時-頻變換是DCT變換。
2.2 運動估計
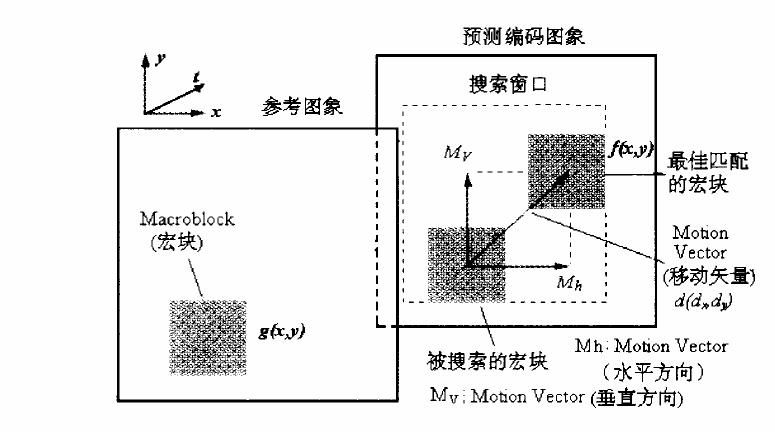
運動估計(Motion Estimation),相鄰視訊幀之間的內容存在一定的相關性。把影象分成若干塊,通過一定的搜尋演算法,在鄰近幀中找到和該塊最相似的塊,這個過程稱為運動估計,二者之間的相對偏移量稱為運動向量。
在編碼的過程中,對運動向量和預測的參差進行編碼。通過運動估計減少了幀間的時間冗餘。
常用的運動估計的匹配演算法有:
常用運動估計的搜尋演算法有:
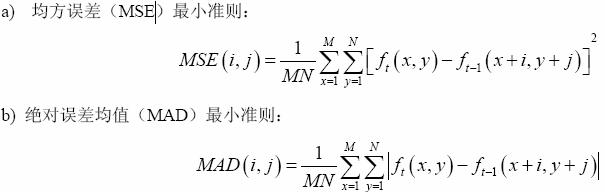
1 全匹配法
光柵方式掃描所有畫素,找到最匹配的塊位置。
2 二維對數法
又稱五點搜尋,邊緣點以原步長繼續搜尋,中心點或邊界點步長減半。
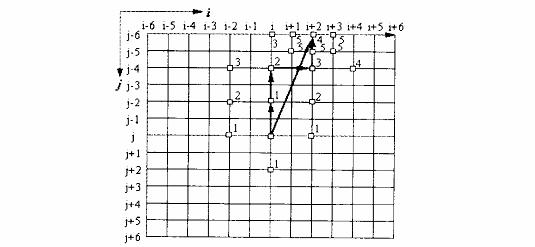
3 三步搜尋
又稱8點搜尋,每次確定下一步的搜尋點,並將步長減半。
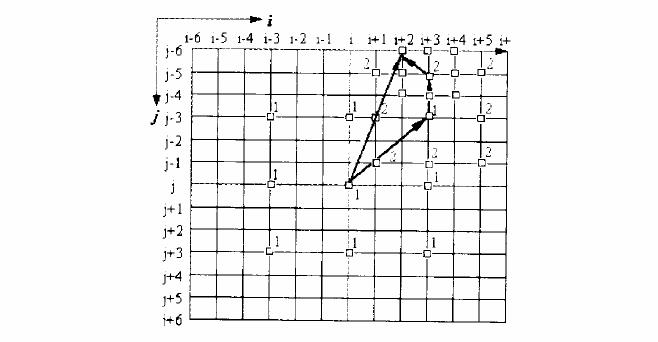
4 領域搜尋
根據鄰近已編碼MB的位置,確定中心的,如果原點最匹配,停止搜尋,如果最匹配點是搜尋框邊緣,繼續以該點為中心進行搜尋。
5 其它
菱形搜尋
鑽石搜尋
2.3 DCT
對資料塊進行空域到時域的變換,能量更加集中。
轉換公式:
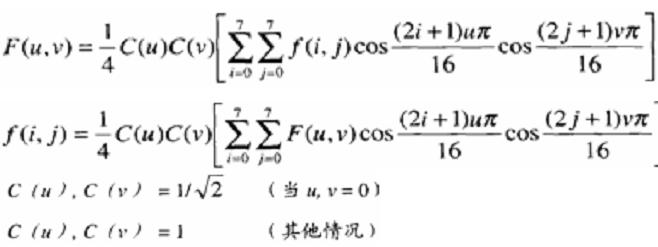
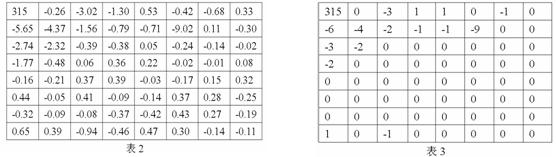
對於一個8x8的資料塊(表1)經過DCT後轉換成表2:
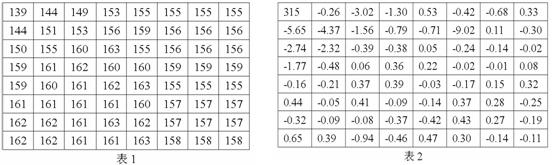
在DCT的轉換過程中,當u=0,v=0時,F(0,0)代表了整個8*8影象塊的均值,F(0,0)稱為直流係數(DC),其餘變換後的63個數,稱為交流係數(AC)。交流係數距離直流係數越遠,交流係數的頻率越高。

2.4 量化
量化:目的是使儲存資料的位元數降低,手段是把一批輸入值對應到一個輸出級上,結果降低了資料的精度。
量化示例:
結論:經過量化後的資料,在進行解碼還原時勢必導致影象的失真。量化的精度,決定了影象還原時的失真程度,精度越高,失真越小,反映在位元速率上,就是量化精度越高,位元速率越大。
幀內編碼和幀間編碼採用的不同量化方式
編碼時對量化值進行編碼傳輸。
量化公式:
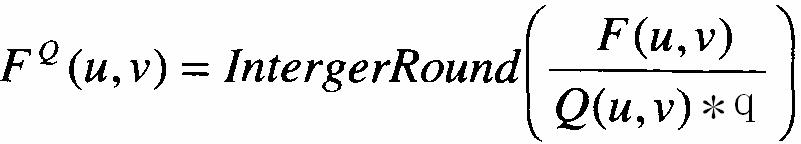
2.5 Z-Scan
DCT加量化後的資料,能量都集中在左上角,在進行資料儲存時採用Z掃描的順序進行儲存。
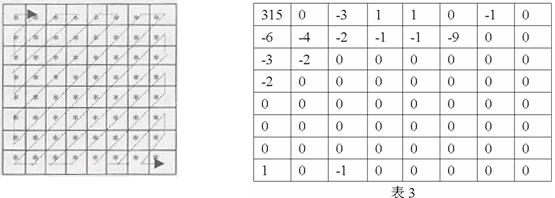
經過Z掃描後,直流係數和交流係數的低頻部分,會排在新陣列的前面,而交流係數的高頻部分排到後面,而高頻中大部分數的值大多都是0,這樣我們就把可以得到一長串的“0”的序列,為下一步的編碼做好準備。
2.6 熵編碼
原理:資訊冗餘
常用的熵編碼有:
RLE:行程長度編碼,是針對交流係數進行編碼的,它的編碼原理是,使用一個位元組的高4位表示連續的0的個數,使用它的低4位表示編碼下一個非0係數所需要的位數,跟在後面的是非0係數的值。
Huffman:在變長編碼中,對出現概率大的符號賦予短碼字,對出現概率小的符號賦予長碼字。
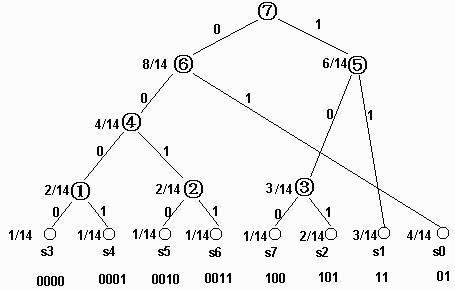
其它:CAVLC,CABAC
2.7 重構
模擬解碼器對已經編碼的資料進行解碼,解碼後的視訊資料作為其後編碼的視訊的參考幀資料。
3.1 I幀編碼
MPEG-2編碼巨集塊大小為16x16,分解4個8x8Y資料塊和2個CrCb資料塊。
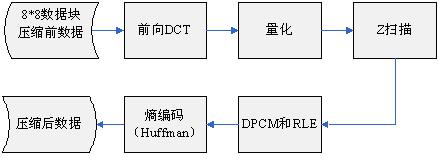
I幀編碼後的重構見下節。
3.2 B,P幀編碼
B,P幀以16x16巨集塊大小為單位進行ME,其後操作和I幀相同;對於所有幀都要在量化進行重構,重構後的重構幀作為其後編碼幀的參考幀。

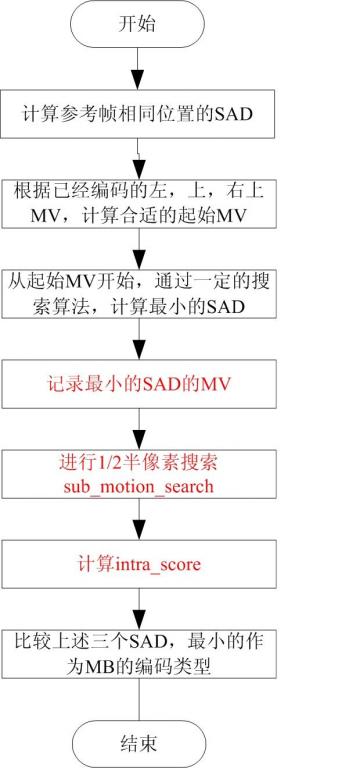
3.3 P幀MB的運動估計
P幀進行前向預測,參考其編碼的I幀或P幀。在對P幀中的MB進行運動估計時,一般會先參考該巨集塊左方、上方和右上方的巨集塊的運動向量,找到最佳的匹配塊位置。P幀中MB的最終編碼型別,還需要比較幀內編碼(Intra)和幀間(Inter)編碼的MSE,來確定最終的編碼型別。因此在P幀中,一般會有幀內和幀間兩種編碼型別。
同時,在MPEG-2中,增加了1/2畫素搜尋,這樣增加了匹配的準確度。
3.4 B幀的MB的運動估計
B幀的巨集塊可能存在的編碼型別有:I型別,P型別,B型別和Bi型別。
具體的ME過程如下:
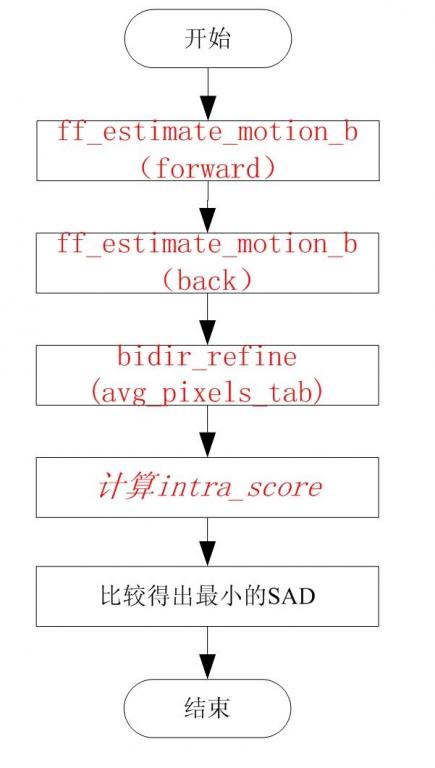
由上圖我們可以看到,在進行B塊的運動估計時,需要對forward,Back,Bidir,itnra四種方式進行比較,得到最佳的SAD作為最終的編碼型別。
3.5 Skip MB和I_PCM MB
在MPEG-2編碼時,有一些MB不需要進行編碼,這樣的MB稱為Skip MB。Skip MB需要滿足的基本條件包括:
1 運動向量為0
2 CBP為0
有些編碼器也其它的條件限制,比如在FFMPEG中,Skip MB不可以是非右邊和下邊的邊界點。
I_PCM,直接傳輸影象畫素值,不經過任何變換。應用場合包括:
1. 影象本身不規則,編碼比不編碼使用的位元數還多。
更精確地傳輸影象4.1 FFMPEG簡介
FFmpeg is a complete solution to record, convert and stream audio and video. It includes libavcodec, the leading audio/video codec library. FFmpeg is developed under Linux, but it can compiled under most operating systems, including Windows.
組成部分:
- ffmpeg 是一個命令列工具,用來對視訊檔案轉換格式,也支援對電視卡即時編碼
- ffserver 是一個 HTTP 多媒體即時廣播串流伺服器,支援時光平移
- ffplay 是一個簡單的播放器,基於 SDL 與 FFmpeg 函式庫
- libavcodec 包含了全部 FFmpeg 音訊/視訊 編解碼函式庫
- libavformat 包含 demuxers 和 muxer 函式庫
- libavutil 包含一些工具函式庫
- libpostproc 對於視訊做前處理的函式庫
- libswscale 對於影像作縮放的函式庫
相關網站:
http://ffmpeg.org/
http://www.ffmpeg.com.cn/index.php
4.2 FFMPEG的程式碼體系結構
FFMPEG包括了多種視音訊的CODEC,對於每種CODEC,FFMPEG要求提供一個滿足結構體AVCodec的資料結構:
/**
* AVCodec.
*/
typedef struct AVCodec {
const char *name;
enum CodecType type;
enum CodecID id;
int priv_data_size;
int (*init)(AVCodecContext *);
int (*encode)(AVCodecContext *, uint8_t *buf, int buf_size, void *data);
int (*close)(AVCodecContext *);
int (*decode)(AVCodecContext *, void *outdata, int *outdata_size,
uint8_t *buf, int buf_size);
int capabilities;
#if LIBAVCODEC_VERSION_INT < ((50<<16)+(0<<8)+0)
void *dummy; // FIXME remove next time we break binary compatibility
#endif
struct AVCodec *next;
void (*flush)(AVCodecContext *);
const AVRational *supported_framerates; ///array of supported framerates, or NULL if any, array is terminated by {0,0}
const enum PixelFormat *pix_fmts; ///array of supported pixel formats, or NULL if unknown, array is terminanted by -1
} AVCodec;
這個資料結構中主要包括了CODEC的標識及各種操作函式,如decode 或encode等。這樣FFPMEG提供一個統一的呼叫介面,具體呼叫哪種CODEC由CODEC標識和操作函式來決定。
一般CODEC的函式呼叫順序包括:
avcodec_init
avcodec_register_all
avcodec_find_encoder/decoder
avcodec_open
avcodec_encode_video/encoder_video/ encode_audio/encoder_audio
avcodec_close
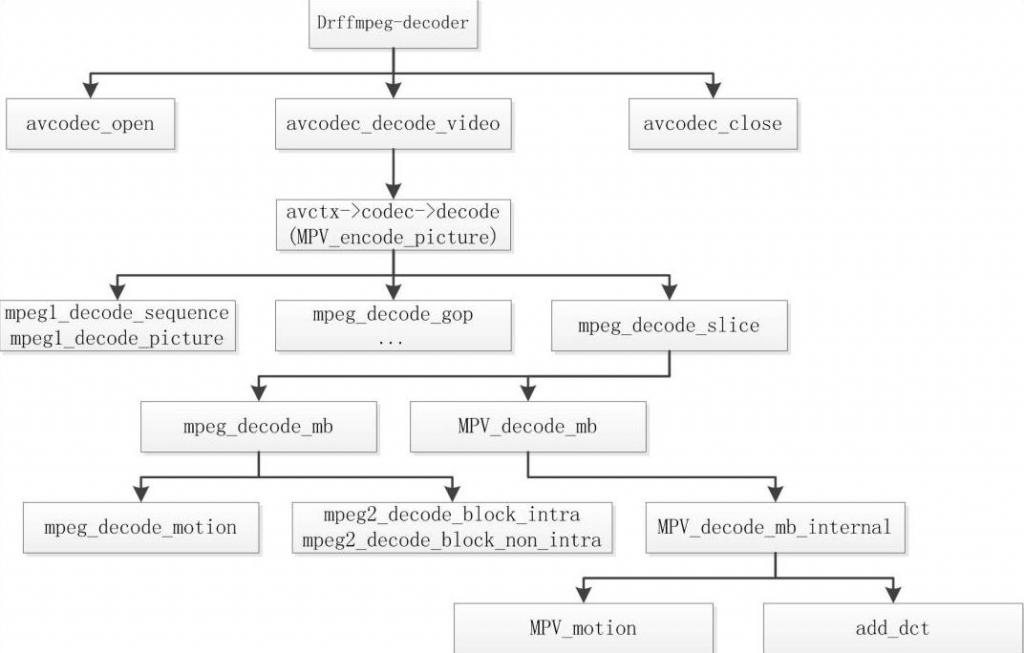
4.3 FFMPEG中的MPEG-2程式碼流程
4.3.1Encoder
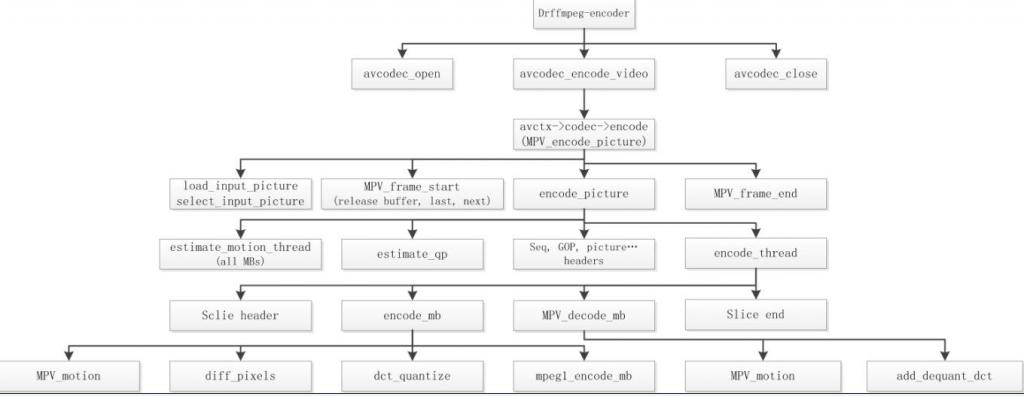
4.3.2 Decoder
5.1 編碼原理圖
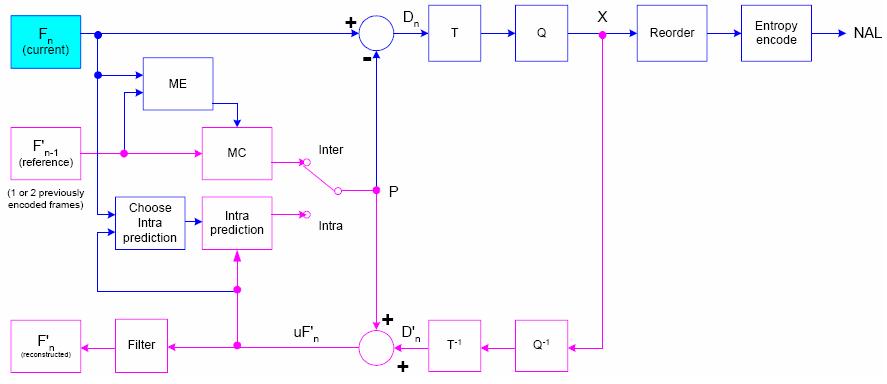
對比上圖和基本原理圖,我們會發現只是多了一個Fitler,那麼H.264和MPEG-2編碼之間的區別只是在於這一個Filter嗎?
H.264和MPEG-2編碼效率的主要提升在於以下幾方面的主要區別:
n 幀內預測編碼
n 多幀參考
n ME時巨集塊和ME時細化巨集塊,子巨集塊比較,¼畫素ME
n 多幀參考
n 更高效的熵編碼CAVLC和CABAC
n Deblock Filter
到目前為止,H.264共有四個級別的Profile:
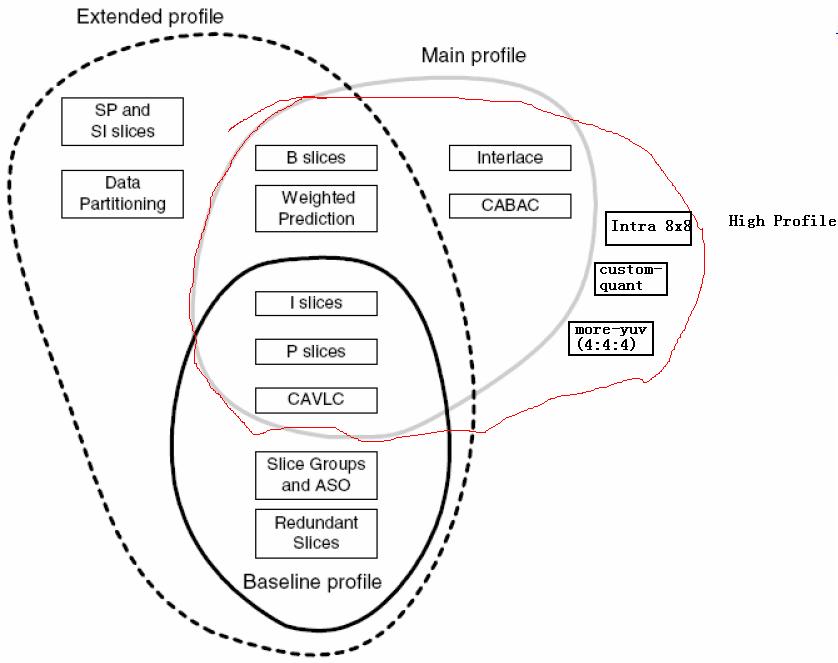
各個Profile的特點在圖中已經標明,這些不同的特點決定不同Profile的不同應用場合。
Baseline:一般用在可視電話,會議電視,無線通訊等實時通訊情況下。
Main:執行隔行,主要用於數字電視與數字視訊儲存。
Extended:支援碼流的切換,主要用於流媒體。
High:用在高清解析度的場合。
由上圖我們可知,各等級之間並不是子集的關係。
5.3 幀內預測編碼
我們知道,在MPEG-2中,幀內編碼就是直接對MB進行DCT變換,然後儲存相關的引數。在H.264中,對幀內編碼引入了預測編碼,所謂幀內預測就是在對MB進行DCT變換前,先根據其周圍已編碼的MB或sub-MB進行預測,僅對預測後的殘差和預測方式進行編碼。
針對16x16和4x4,H.264提供了多種預測方式。
5.3.1 4x4幀內預測編碼
4x4預測適用於細節較多的MB。
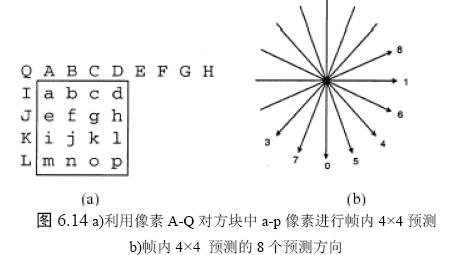
4x4預測編碼共9種方式:
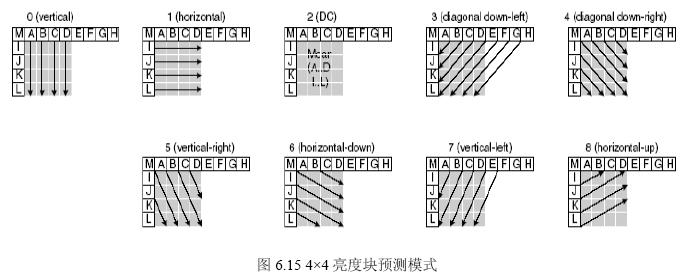


5.3.2 16x16幀內預測編碼
16x16預測適合平坦區域的MB的。
5.3.3色度8x8幀內預測
每個幀內編碼巨集塊的8×8 色度成分由已編碼左上方色度畫素預測而得,兩種色度成分常用同一種預測模式。4 種預測模式類似於幀內16×16 預測的4 種預測模式,只是模式編號不同。其中DC(模式0)、水平(模式1)、垂直(模式2)、平面(模式3)。
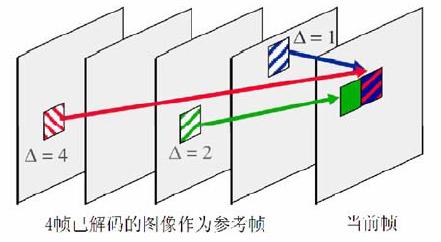
5.4 多幀參考
在H.264中,參考幀最多數目可以達到16個。H.264維護了兩個List用於儲存參考幀影象,List中影象基於POC進行排序,包括了前向參考和後向參考的影象。
5.5 幀間ME
5.5.1幀間ME的巨集塊及巨集塊分割
l 巨集塊分割
ME時16x16MB有以下幾種分割方式:
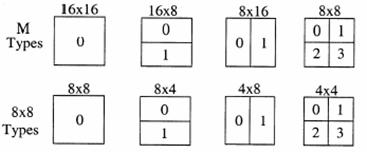
色度塊分割則為相應的亮度的一半。
下圖是一個預測後的殘差幀:
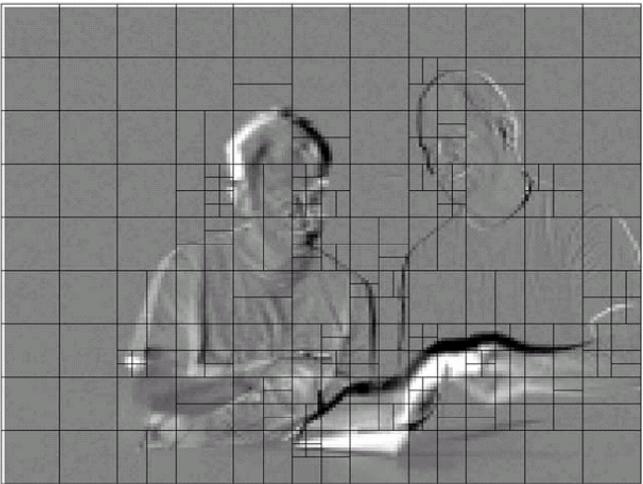
我們可以看到在平坦區域一般是16x16分割,在細節較多的區域採用較細的分割。
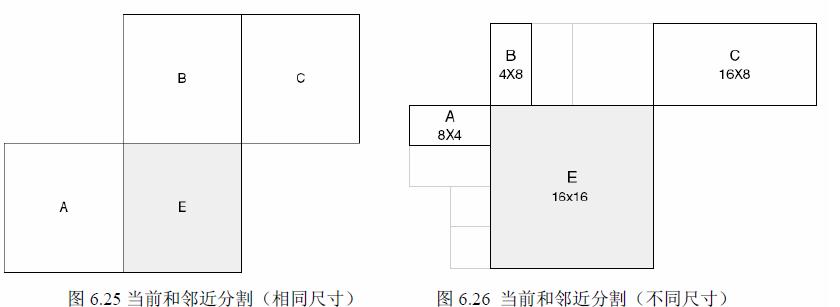
l MV預測
預測向量MVp 基於已計算MV 和MVD(預測與當前的差異)並被編碼和傳送。MVp 則取決於運動補償尺寸和鄰近MV 的有無。
其中:
1) 傳輸分割不包括16×8 和8×16 時,MVp 為A、B、C 分割MV 的中值;
2) 16×8 分割,上面部分MVp 由B 預測,下面部分MVp 由A 預測;
3) 8×16 分割,左面部分MVp 由A 預測,右面部分MVp 由C 預測;
4) 跳躍巨集塊(skipped MB),同1)。
l 1/2,1/4畫素搜尋
1/2畫素內插:
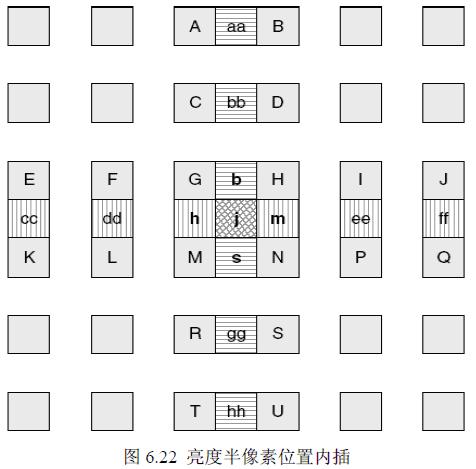
內插演算法:
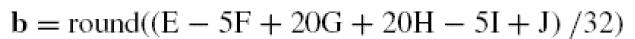
1/4內插:
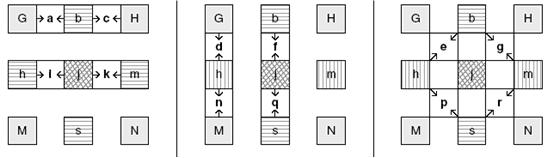
1/4內插演算法在1/2基礎上通過線性進行。
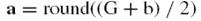
5.6 熵編碼
n CAVLC
n CABAC
塊效應的產生,是由於預測時基於方塊進行的。在進行量化後,方塊的邊界有時變得非常明顯。
n 解碼完的一幀資料進行Deblocking
n Intra編碼的MB沒有進行Deblocking

去塊效應的具體方法:

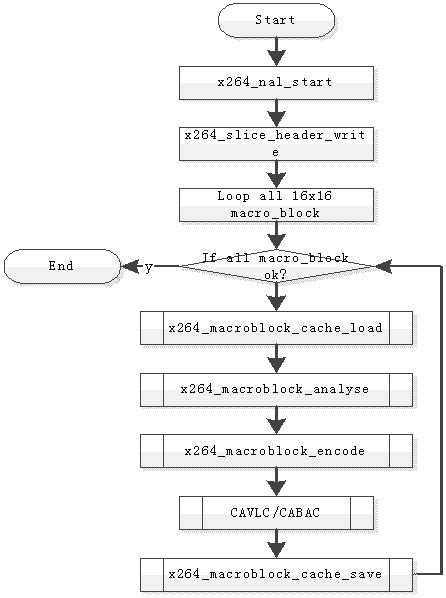
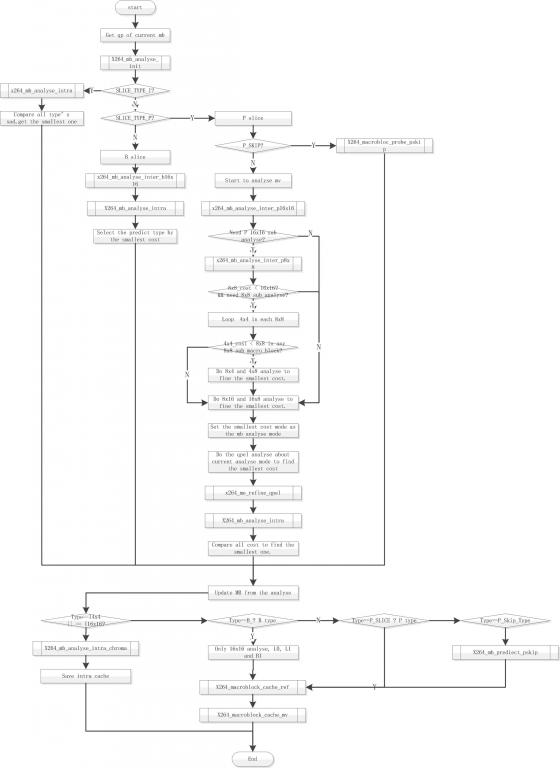
六X264程式碼結構
6.1 整體結構

七例項解析
× 降低已經編碼視訊流的位元速率:僅修改量化係數,重新進行熵編碼。
× Mpeg-2轉碼H.264:
1 直接使用Mpeg-2中的運動向量。
2 在Mpeg-2運動向量的基礎上增加H.264的多幀搜尋和子巨集塊搜尋。
× 已編碼視訊疊加LOGO:
1 對LOGO區域和對LOGO邊緣巨集塊進行重新編碼。
2 對其它區域使用原來的編碼引數。