
零基礎學Support Vector Machine(SVM)
我本人就是上述問題的受害者之一。我翻閱了很多關於SVM的書籍和資料,但沒有找到一份材料能夠在公式推導、理論介紹,系統分析、變數說明、代數和幾何意義的解釋等方面完整地對SVM加以分析和說明的。換言之,對於普通的一年級非數學專業的研究生而言,要想看懂SVM需要蒐集很多資料,然後對照閱讀和深入思考,才可能比較透徹地理解SVM演算法。由於我本人也在東北大學教授面向一年級碩士研究生的《模式識別技術與應用》課程,因此希望能總結出一份相對完整、簡單和透徹的關於SVM演算法的介紹文字,以便學生能夠快速準確地理解SVM演算法。
以下我會分為四個步驟對最基礎的線性SVM問題加以介紹,分別是1)問題原型,2)數學模型,3)最優化求解,4)幾何解釋。我儘可能用最簡單的語言和最基本的數學知識對上述問題進行介紹,希望能對困惑於SVM演算法的學生有所幫助。
由於個人時間有限,只能找空閒的時間更新,速度會比較慢,請大家諒解。
一、SVM演算法要解決什麼問題
SVM的全稱是Support Vector Machine,即支援向量機,主要用於解決模式識別領域中的資料分類問題,屬於有監督學習演算法的一種。SVM要解決的問題可以用一個經典的二分類問題加以描述。如圖1所示,紅色和藍色的二維資料點顯然是可以被一條直線分開的,在模式識別領域稱為線性可分問題。然而將兩類資料點分開的直線顯然不止一條。圖1(b)和(c)分別給出了A、B兩種不同的分類方案,其中黑色實線為分界線,術語稱為“決策面
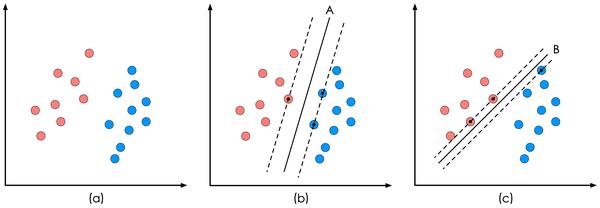
圖1 二分類問題描述
SVM演算法認為圖1中的分類器A在效能上優於分類器B,其依據是A的分類間隔比B要大。這裡涉及到第一個SVM獨有的概念“分類間隔”。在保證決策面方向不變且不會出現錯分樣本的情況下移動決策面,會在原來的決策面兩側找到兩個極限位置(越過該位置就會產生錯分現象),如虛線所示。虛線的位置由決策面的方向和距離原決策面最近的幾個樣本的位置決定。而這兩條平行虛線正中間的分界線就是在保持當前決策面方向不變的前提下的最優決策面。兩條虛線之間的垂直距離就是這個最優決策面對應的分類間隔。顯然每一個可能把資料集正確分開的方向都有一個最優決策面(有些方向無論如何移動決策面的位置也不可能將兩類樣本完全分開
從表面上看,我們優化的物件似乎是這個決策面的方向和位置。但實際上最優決策面的方向和位置完全取決於選擇哪些樣本作為支援向量。而在經過漫長的公式推導後,你最終會發現,其實與線性決策面的方向和位置直接相關的引數都會被約減掉,最終結果只取決於樣本點的選擇結果。
到這裡,我們明確了SVM演算法要解決的是一個最優分類器的設計問題。既然叫作最優分類器,其本質必然是個最優化問題。所以,接下來我們要討論的就是如何把SVM變成用數學語言描述的最優化問題模型,這就是我們在第二部分要講的“線性SVM演算法的數學建模”。
*關於“決策面”,為什麼叫決策面,而不是決策線?好吧,在圖1裡,樣本是二維空間中的點,也就是資料的維度是2,因此1維的直線可以分開它們。但是在更加一般的情況下,樣本點的維度是n,則將它們分開的決策面的維度就是n-1維的超平面(可以想象一下3維空間中的點集被平面分開),所以叫“決策面”更加具有普適性,或者你可以認為直線是決策面的一個特例。
二、線性SVM演算法的數學建模
一個最優化問題通常有兩個最基本的因素:1)目標函式,也就是你希望什麼東西的什麼指標達到最好;2)優化物件,你期望通過改變哪些因素來使你的目標函式達到最優。在線性SVM演算法中,目標函式顯然就是那個“分類間隔”,而優化物件則是決策面。所以要對SVM問題進行數學建模,首先要對上述兩個物件(“分類間隔”和“決策面”)進行數學描述。按照一般的思維習慣,我們先描述決策面。
2.1 決策面方程
(請注意,以下的描述對於線性代數及格的同學可能顯得比較囉嗦,但請你們照顧一下用高數課治療失眠的同學們。)
請你暫時不要糾結於n維空間中的n-1維超平面這種超出正常人想象力的情景。我們就老老實實地看看二維空間中的一根直線,我們從初中就開始學習的直線方程形式很簡單。
(2.1)
現在我們做個小小的改變,讓原來的軸變成
軸,
變成
軸,於是公式(2.1)中的直線方程會變成下面的樣子
(2.2)
(2.3)
公式(2.3)的向量形式可以寫成
(2.4)
考慮到我們在等式兩邊乘上任何實數都不會改變等式的成立,所以我們可以寫出一個更加一般的向量表達形式:
(2.5)
看到變數略顯粗壯的身體了嗎?他們是黑體,表示變數是個向量,
,
。一般我們提到向量的時候,都預設他們是個列向量,所以我在方括號[
]後面加上了上標T,表示轉置(我知道我真的很囉嗦,但是關於“零基礎”三個字,我是認真的。),它可以幫忙把行向量豎過來變成列向量,所以在公式(2.5)裡面
後面的轉置符號T,會把列向量又轉回到行向量。這樣一個行向量
和一個列向量
就可快快樂樂的按照矩陣乘法的方式結合,變成一個標量,然後好跟後面的標量
相加後相互抵消變成0。
就著公式(2.5),我們再稍稍嘗試深入一點。那就是探尋一下向量和標量
的幾何意義是什麼。讓我們回到公式(2.4),對比公式(2.5),可以發現此時的
。然後再去看公式(2.2),還記得那條我們熟悉的直線方程中的a的幾何意義嗎?對的,那是直線的斜率。如果我們構造一個向量
,它應該跟我們的公式(2.2)描述的直線平行。然後我們求一下兩個向量的點積
,你會驚喜地發現結果是0。我們管這種現象叫作“兩個向量相互正交”。通俗點說就是兩個向量相互垂直。當然,你也可以在草稿紙上自己畫出這兩個向量,比如讓
,你會發現
在第一象限,與橫軸夾角為60°,而
在第四象限與橫軸夾角為30°,所以很顯然他們兩者的夾角為90°。
你現在是不是已經忘了我們討論正交或者垂直的目的是什麼了?那麼請把你的思維從座標系上抽出來,回到決策面方程上來。我是想告訴你向量跟直線
是相互垂直的,也就是說
控制了直線的方向。另外,還記得小時候我們學過的那個叫做截距的名詞嗎?對了,
就是截距,它控制了直線的位置。
然後,在本小節的末尾,我冒昧地提示一下,在n維空間中n-1維的超平面的方程形式也是公式(2.5)的樣子,只不過向量的維度從原來的2維變成了n維。如果你還是想不出來超平面的樣子,也很正常。那麼就請你始終記住平面上它們的樣子也足夠了。
到這裡,我們花了很多篇幅描述一個很簡單的超平面方程(其實只是個直線方程),這裡真正有價值的是這個控制方向的引數。接下來,你會有很長一段時間要思考它到底是個什麼東西,對於SVM產生了怎樣的影響。
2.2 分類“間隔”的計算模型
我們在第一章裡介紹過分類間隔的定義及其直觀的幾何意義。間隔的大小實際上就是支援向量對應的樣本點到決策面的距離的二倍,如圖2所示。
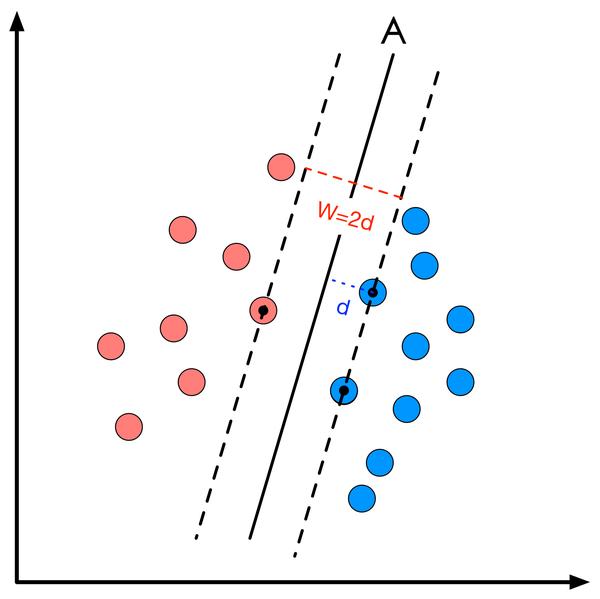
圖2 分類間隔計算
所以分類間隔計算似乎相當簡單,無非就是點到直線的距離公式。如果你想要回憶高中老師在黑板上推導的過程,可以隨便在百度文庫裡搜尋關鍵詞“點到直線距離推導公式”,你會得到至少6、7種推導方法。但這裡,請原諒我給出一個簡單的公式如下:
(2.6)
這裡是向量
的模,表示在空間中向量的長度,
就是支援向量樣本點的座標。
就是決策面方程的引數。而追求
的最大化也就是尋找
的最大化。看起來我們已經找到了目標函式的數學形式。
但問題當然不會這麼簡單,我們還需要面對一連串令人頭疼的麻煩。
2.3 約束條件
接著2.2節的結尾,我們討論一下究竟還有哪些麻煩沒有解決:
1)並不是所有的方向都存在能夠實現100%正確分類的決策面,我們如何判斷一條直線是否能夠將所有的樣本點都正確分類?
2)即便找到了正確的決策面方向,還要注意決策面的位置應該在間隔區域的中軸線上,所以用來確定決策面位置的截距也不能自由的優化,而是受到決策面方向和樣本點分佈的約束。
3)即便取到了合適的方向和截距,公式(2.6)裡面的不是隨隨便便的一個樣本點,而是支援向量對應的樣本點。對於一個給定的決策面,我們該如何找到對應的支援向量?
以上三條麻煩的本質是“約束條件”,也就是說我們要優化的變數的取值範圍受到了限制和約束。事實上約束條件一直是最優化問題裡最讓人頭疼的東西。但既然我們已經論證了這些約束條件確實存在,就不得不用數學語言對他們進行描述。儘管上面看起來是3條約束,但SVM演算法通過一些巧妙的小技巧,將這三條約束條件融合在了一個不等式裡面。
我們首先考慮一個決策面是否能夠將所有的樣本都正確分類的約束。圖2中的樣本點分成兩類(紅色和藍色),我們為每個樣本點加上一個類別標籤
:
(2.7)
如果我們的決策面方程能夠完全正確地對圖2中的樣本點進行分類,就會滿足下面的公式
(2.8)
如果我們要求再高一點,假設決策面正好處於間隔區域的中軸線上,並且相應的支援向量對應的樣本點到決策面的距離為d,那麼公式(2.8)就可以進一步寫成:
(2.9)
符號是“對於所有滿足條件的” 的縮寫。我們對公式(2.9)中的兩個不等式的左右兩邊除上d,就可得到:
(2.10)
其中
把 和
就當成一條直線的方向向量和截距。你會發現事情沒有發生任何變化,因為直線
和直線
其實是一條直線。現在,現在讓我忘記原來的直線方程引數
和
,我們可以把引數
和
重新起個名字,就叫它們
和
。我們可以直接說:“對於存在分類間隔的兩類樣本點,我們一定可以找到一些決策面,使其對於所有的樣本點均滿足下面的條件:”
公式(2.11)可以認為是SVM優化問題的約束條件的基本描述。
2.4 線性SVM優化問題基本描述
公式(2.11)裡面的情況什麼時候會發生呢,參考一下公式(2.9)就會知道,只有當
是決策面
所對應的支援向量樣本點時,等於1或-1的情況才會出現。這一點給了我們另一個簡化目標函式的啟發。回頭看看公式(2.6),你會發現等式右邊分子部分的絕對值符號內部的表示式正好跟公式(2.11)中不等式左邊的表示式完全一致,無論原來這些表示式是1或者-1,其絕對值都是1。所以對於這些支援向量樣本點有:
(2.12)
公式(2.12)的幾何意義就是,支援向量樣本點到決策面方程的距離就是。我們原來的任務是找到一組引數
使得分類間隔
最大化,根據公式(2.12)就可以轉變為
的最小化問題,也等效於
的最小化問題。我們之所以要在
上加上平方和1/2的係數,是為了以後進行最優化的過程中對目標函式求導時比較方便,但這絕不影響最優化問題最後的解。
另外我們還可以嘗試將公式(2.11)給出的約束條件進一步在形式上精練,把類別標籤和兩個不等式左邊相乘,形成統一的表述:
(2.13)
好了,到這裡我們可以給出線性SVM最優化問題的數學描述了:
(2.14)
這裡m是樣本點的總個數,縮寫s. t. 表示“Subject to”,是“服從某某條件”的意思。公式(2.14)描述的是一個典型的不等式約束條件下的二次型函式優化問題,同時也是支援向量機的基本數學模型。(此時此刻,你也許會回頭看2.3節我們提出的三個約束問題,思考它們在公式2.14的約束條件中是否已經得到了充分的體現。但我不建議你現在就這麼做,因為2.14採用了一種比較含蓄的方式表示這些約束條件,所以你即便現在不理解也沒關係,後面隨著推導的深入,這些問題會一點點露出真容。)
接下來,我們將在第三章討論大多數同學比較陌生的問題:如何利用最優化技術求解公式(2.14)描述的問題。哪些令人望而生畏的術語,凸二次優化、拉格朗日對偶、KKT條件、鞍點等等,大多出現在這個部分。全面理解和熟練掌握這些概念當然不容易,但如果你的目的主要是瞭解這些技術如何在SVM問題進行應用的,那麼閱讀過下面一章後,你有很大的機會可以比較直觀地理解這些問題。
come from future______by Chen
*一點小建議,讀到這裡,你可以試著在紙上隨便畫一些點,然後嘗試用SVM的思想手動畫線將兩類不同的點分開。你會發現大多數情況下,你會先畫一條可以成功分開兩類樣本點的直線,然後你會在你的腦海中想象去旋轉這條線,旋轉到某個角度,你就會下意識的停下來,因為如果再旋轉下去,就找不到能夠成功將兩類點分開的直線了。這個過程就是對直線方向的優化過程。對於有些問題,你會發現SVM的最優解往往出現在不能再旋轉下去的邊界位置,這就是約束條件的邊界,對比我們提到的等式約束條件,你會對代數公式與幾何想象之間的關係得到一些相對直觀的印象。
三、基於最優化技術求解線性SVM問題
(Hi,好久不見)就像我們在第二部分結尾時提到的,SVM問題是一個不等式約束條件下的優化問題。絕大多數模式識別教材在討論這個問題時都會在附錄中加上優化演算法的簡介,雖然有些寫得未免太簡略,但看總比不看強,所以這時候如果你手頭有一本模式識別教材,不妨翻到後面找找看。結合附錄看我下面寫的內容,也許會有幫助。
我們先解釋一下我們下面講解的思路以及重點關注哪些問題:
1)有約束優化問題的幾何意象:閉上眼睛你看到什麼?
2)拉格朗日乘子法:約束條件怎麼跑到目標函式裡面去了?
3)KKT條件:約束條件是不等式該怎麼辦?
4)拉格朗日對偶:最小化問題怎麼變成了最大化問題?
5)例項演示:拉格朗日對偶函式到底啥樣子?
6)SVM優化演算法的實現:數學講了辣麼多,到底要怎麼用啊?
3.1 有約束優化問題的幾何意象
約束條件一般分為等式約束和不等式約束兩種,前者表示為(注意這裡的
跟第二章裡面的樣本x沒有任何關係,只是一種通用的表示);後者表示為
(你可能會問為什麼不是
,彆著急,到KKT那裡你就明白了)。
假設(就是這個向量一共有d個標量組成),則
的幾何意象就是d維空間中的d-1維曲面,如果函式
是線性的,
則是個d-1維的超平面。那麼有約束優化問題就要求在這個d-1維的曲面或者超平面上找到能使得目標函式最小的點,這個d-1維的曲面就是“可行解區域”。
對於不等式約束條件,,則可行解區域從d-1維曲面擴充套件成為d維空間的一個子集。我們可以從d=2的二維空間進行對比理解。等式約束對應的可行解空間就是一條線;不等式約束對應的則是這條線以及線的某一側對應的區域,就像下面這幅圖的樣子(圖中的目標函式等高線其實就是等值線,在同一條等值線上的點對應的目標函式值相同)。
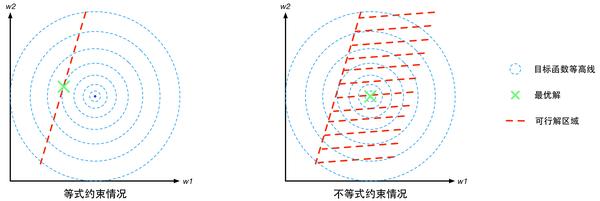
圖3 有約束優化問題的幾何意象圖圖3 有約束優化問題的幾何意象圖
3.2 拉格朗日乘子法
儘管在3.1節我們已經想象出有約束優化問題的幾何意象。可是如何利用代數方法找到這個被約束了的最優解呢?這就需要用到拉格朗日乘子法。
首先定義原始目標函式,拉格朗日乘子法的基本思想是把約束條件轉化為新的目標函式
的一部分(關於
的意義我們一會兒再解釋),從而使有約束優化問題變成我們習慣的無約束優化問題。那麼該如何去改造原來的目標函式
使得新的目標函式
的最優解恰好就在可行解區域中呢?這需要我們去分析可行解區域中最優解的特點。
1)最優解的特點分析
這裡比較有代表性的是等式約束條件(不等式約束條件的情況我們在KKT條件裡再講)。我們觀察一下圖3中的紅色虛線(可行解空間)和藍色虛線(目標函式的等值線),發現這個被約束的最優解恰好在二者相切的位置。這是個偶然嗎?我可以負責任地說:“NO!它們溫柔的相遇,是三生的宿命。”為了解釋這個相遇,我們先介紹梯度的概念。梯度可以直觀的認為是函式的變化量,可以描述為包含變化方向和變化幅度的一個向量。然後我們給出一個推論:
推論1:“在那個宿命的相遇點(也就是等式約束條件下的優化問題的最優解),原始目標函式
的梯度向量
必然與約束條件
的切線方向垂直。”
關於推論1的粗淺的論證如下:
如果梯度向量不垂直於
在
點的切線方向,就會在
的切線方向上存在不等於0的分量,也就是說在相遇點
附近,
還在沿著
變化。這意味在
上
這一點的附近一定有一個點的函式值比
更小,那麼
就不會是那個約束條件下的最優解了。所以,梯度向量
必然與約束條件
的切線方向垂直。
推論2:“函式的梯度方向也必然與函式自身等值線切線方向垂直。”
推論2的粗淺論證:與推論1 的論證基本相同,如果的梯度方向不垂直於該點等值線的切線方向,
就會在等值線上有變化,這條線也就不能稱之為等值線了。
根據推論1和推論2,函式的梯度方向在
點同時垂直於約束條件
和自身的等值線的切線方向,也就是說函式
的等值線與約束條件曲線
在
點具有相同(或相反)的法線方向,所以它們在該點也必然相切。
讓我們再進一步,約束條件也可以被視為函式
的一條等值線。按照推論2中“函式的梯度方向必然與自身的等值線切線方向垂直”的說法,函式
在
點的梯度向量
也與
的切線方向垂直。
到此我們可以將目標函式和約束條件視為兩個具有平等地位的函式,並得到推論3:
推論3:“函式與函式
的等值線在最優解點
處相切,即兩者在
點的梯度方向相同或相反”,
於是我們可以寫出公式(3.1),用來描述最優解的一個特性:
(3.1)
這裡增加了一個新變數,用來描述兩個梯度向量的長度比例。那麼是不是有了公式(3.1)就能確定
的具體數值了呢?顯然不行!從代數解方程的角度看,公式(3.1)相當於d個方程(假設
是d維向量,函式
的梯度就是d個偏導陣列成的向量,所以公式(2.15)實際上是1個d維向量方程,等價於d個標量方程),而未知數除了
的d個分量以外,還有1個
。所以相當於用d個方程求解d+1個未知量,應有無窮多組解;從幾何角度看,在任意曲線
(k為值域範圍內的任意實數)上都能至少找到一個滿足公式(3.1)的點,也就是可以找到無窮多個這樣的相切點。所以我們還需要增加一點限制,使得無窮多個解變成一個解。好在這個限制是現成的,那就是:
(3.2)
把公式(3.1)和(3.2)放在一起,我們有d+1個方程,解d+1個未知數,方程有唯一解,這樣就能找到這個最優點了。
2)構造拉格朗日函式
雖然根據公式(3.1)和(3.2),已經可以求出等式約束條件下的最優解了,但為了在數學上更加便捷和優雅一點,我們按照本節初提到的思想,構造一個拉格朗日函式,將有約束優化問題轉為無約束優化問題。拉格朗日函式具體形式如下:
(3.3)
新的拉格朗日目標函式有兩個自變數,根據我們熟悉的求解無約束優化問題的思路,將公式(3.3)分別對
求導,令結果等於零,就可以建立兩個方程。同學們可以自己試一下,很容易就能發現這兩個由導數等於0構造出來的方程正好就是公式(3.1)和(3.2)。說明新構造的拉格朗日目標函式的優化問題完全等價於原來的等式約束條件下的優化問題。
至此,我們說明白了“為什麼構造拉格朗日目標函式可以實現等式約束條件下的目標優化問題的求解”。可是,我們回頭看一下公式(2.14),也就是我們的SVM優化問題的數學表達。囧,約束條件是不等式啊!怎麼辦呢?
3.3 KKT條件
對於不等式約束條件的情況,如圖4所示,最優解所在的位置
有兩種可能,或者在邊界曲線
上或者在可行解區域內部滿足不等式
的地方。
第一種情況:最優解在邊界上,就相當於約束條件就是。參考圖4,注意此時目標函式
的最優解在可行解區域外面,所以函式
在最優解
附近的變化趨勢是“在可行解區域內側較大而在區域外側較小”,與之對應的是函式
在可行解區域內小於0,在區域外大於零,所以在最優解
附近的變化趨勢是內部較小而外部較大。這意味著目標函式
的梯度方向與約束條件函式
的梯度方向相反。因此根據公式(3.1),可以推斷出引數
.
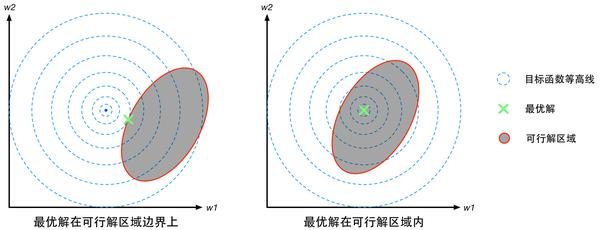
圖4:不等式約束條件下最優解位置分佈的兩種情況
第二種情況:如果在區域內,則相當於約束條件沒有起作用,因此公式(2.17)的拉格朗日函式中的引數。整合這兩種情況,可以寫出一個約束條件的統一表達,如公式(2.18)所示。
(3.4)
其中第一個式子是約束條件本身。第二個式子是對拉格朗日乘子的描述。第三個式子是第一種情況和第二種情況的整合:在第一種情況裡,
;在第二種情況下,
。所以無論哪一種情況都有
。公式(3.4)就稱為Karush-Kuhn-Tucker條件,簡稱KKT條件。
推導除了KKT條件,感覺有點奇怪。因為本來問題的約束條件就是一個,怎麼這個KKT條件又多弄出來兩條,這不是讓問題變得更復雜了嗎?這裡我們要適當的解釋一下:
1)KKT條件是對最優解的約束,而原始問題中的約束條件是對可行解的約束。
2)KKT條件的推導對於後面馬上要介紹的拉格朗日對偶問題的推導很重要。
3.4 拉格朗日對偶
接下來讓我們進入重頭戲——拉格朗日對偶。很多教材到這裡自然而然的就開始介紹“對偶問題”的概念,這實際上是一種“先知式”的教學方式,對於學生研究問題的思路開拓有害無益。所以,在介紹這個知識點之前,我們先要從巨集觀的視野上了解一下拉格朗日對偶問題出現的原因和背景。
按照前面等式約束條件下的優化問題的求解思路,構造拉格朗日方程的目的是將約束條件放到目標函式中,從而將有約束優化問題轉換為無約束優化問題。我們仍然秉承這一思路去解決不等式約束條件下的優化問題,那麼如何針對不等式約束條件下的優化問題構建拉格朗日函式呢?
因為我們要求解的是最小化問題,所以一個直觀的想法是如果我能夠構造一個函式,使得該函式在可行解區域內與原目標函式完全一致,而在可行解區域外的數值非常大,甚至是無窮大,那麼這個沒有約束條件的新目標函式的優化問題就與原來有約束條件的原始目標函式的優化是等價的問題。
拉格朗日對偶問題其實就是沿著這一思路往下走的過程中,為了方便求解而使用的一種技巧。於是在這裡出現了三個問題:1)有約束的原始目標函式優化問題;2)新構造的拉格朗日目標函式優化問題;3)拉格朗日對偶函式的優化問題。我們希望的是這三個問題具有完全相同的最優解,而在數學技巧上通常第三個問題——拉格朗日對偶優化問題——最好解決。所以拉格朗日對偶不是必須的,只是一條捷徑。
1)原始目標函式(有約束條件)
為了接下來的討論,更具有一般性,我們把等式約束條件也放進來,進而有約束的原始目標函式優化問題重新給出統一的描述:
(3.5)
公式(3.5)表示m個等式約束條件和n個不等式約束條件下的目標函式的最小化問題。
2)新構造的目標函式(沒有約束條件)
接下來我們構造一個基於廣義拉格朗日函式的新目標函式,記為:
(3.6)
其中為廣義拉格朗日函式,定義為:
(3.7)
這裡,,是我們在構造新目標函式時加入的係數變數,同時也是公式(3.6)中最大化問題的自變數。將公式(3.7)帶入公式(3.6)有:
(3.8)
我們對比公式(3.5)中的約束條件,將論域範圍分為可行解區域和可行解區域外兩個部分對公式(3.8)的取值進行分析,將可行解區域記為,當
時有:
可行解區域內:由於,
且係數
, 所以有:
可行解區域外:代表公式(3.5)中至少有一組約束條件沒有得到滿足。如果,則調整係數
就可以使
;如果
,調整係數
就可以使
。這意味著,此時有
(3.10)
把公式(3.8),(3.9)和(3.10)結合在一起就得到我們新構造的目標函式的取值分佈情況:
相關推薦
零基礎學Support Vector Machine(SVM)
如果你是一名模式識別專業的研究生,又或者你是機器學習愛好者,SVM是一個你避不開的問題。如果你只是有一堆資料需要SVM幫你處理一下,那麼無論是Matlab的SVM工具箱,LIBSVM還是python框架下的SciKit Learn都可以提供方便快捷的解決方案。但如果你要追求的不僅僅是會用,還希望挑戰一下“理解
支援向量機(Support Vector Machine, SVM)
感知演算法 線性分類器:f(x;w,b)=⟨w,x⟩+bf({\rm{x}};{\rm{w}},b)=\left \langle {\rm{w}},{\rm{x}} \right \rangle+bf(
Support Vector Machine(SVM) sklearn實現
SVM演算法原理 SVM是一種有監督的機器學習演算法,解決的是二元分類問題,即分兩類的問題,多元分類問題可以通過構造多個SVM分類器的方法來解決。 問題描述 假設給定一組訓練樣本T={(x1,y1),(x2,y2),⋯,(xN,yN)}T
【機器學習實戰】第6章 支援向量機(Support Vector Machine / SVM)
第6章 支援向量機 <script type="text/javascript" src="http://cdn.mathjax.org/mathjax/latest/MathJax.js?config=default"></script>
機器學習實戰(五)支援向量機SVM(Support Vector Machine)
目錄 0. 前言 1. 尋找最大間隔 2. 拉格朗日乘子法和KKT條件 3. 鬆弛變數 4. 帶鬆弛變數的拉格朗日乘子法和KKT條件 5. 序列最小優化SMO(Sequential Minimal Optimiz
支援向量機(support vector machine)(一):線性可分SVM
總結一下,不然過段時間就全忘了,加油~ 1、問題描述 假設,存在兩類資料A,B,如圖1所示,A中資料對應於圖中的實心點,B中資料對應圖中的空心點,現在我們需要得到一條直線,能夠將二者進行區分,這樣的線存在無數條,如圖1中的黑色直線所示,這些線都能夠
支援向量機(support vector machine)(二):線性SVM
通常情況下,存在以下兩種情況: 1、分類完全正確的超平面不一定是最好的; 2、樣本資料不是線性可分的; 如圖1所示,如果按照完全分對這個準則來劃分時,L1為最優分割超平面,但是實際情況如果按照L2來進行劃分,效果可能會更好,分類結果會更加魯棒。
支援向量機的公式推導(Support Vector Machine,SVM)
轉:https://www.cnblogs.com/pursued-deer/p/7857306.html 1 認識向量機 支援向量機是處理資料分類問題,目的是學會一個二分類的函式模型,屬於監督式學習的方法,被廣泛應用於統計分類和迴歸分析。通過建立一個超平面對樣本資料進行分類,超平面涉及到凸
支援向量機(Support Vector Machine,SVM)—— 線性SVM
支援向量機(Support Vector Machine,簡稱 SVM)於 1995 年正式發表,由於其在文字分類任務中的卓越效能,很快就成為機器學習的主流技術。儘管現在 Deep Learning 很流行,SVM 仍然是一種很有的機器學習演算法,在資料集小的情況下能比 Deep Learning 取得更
機器學習之支援向量機SVM Support Vector Machine (五) scikit-learn演算法庫
一、scikit-learn SVM演算法庫概述 scikit-learn中SVM的演算法庫分為兩類,一類是分類演算法庫,包括SVC、 NuSVC和LinearSVC三個類。另一類是迴歸演算法庫,包括SVR、NuSVR和LinearSVR三個類。相關的
機器學習——支援向量機SVM(Support Vector Machine)(下)
1、SVM演算法特徵 (1)訓練好的模型的演算法複雜度是由支援向量的個數決定的,而不是由資料的維度決定。所以,SVM不太容易產生overfitting。 (2)SVM訓練出來的模型完全依賴於支援向量(
神經網路學習筆記-支援向量機(Support Vector Machine,SVM )
基於誤差反向傳播演算法的多層感知器 徑向基函式網路 支援向量機(SupportVector Machine , SVM ) 都是前饋神經網路 ,都用於解決模式分類與非線性對映問題 。 線性可分模
機器學習:SVM(Support Vector Machine)支援向量機簡介
SVM(Support Vector Machine): 支援向量機 有監督學習模型 應用:模式識別、分類以及迴歸分析 SVM的主要思想: 它是針對線性可分情況進行分析,對於線性不可分的情況
如何使用支援向量機(Support Vector Machine,SVM)思想解決迴歸問題
迴歸問題的本質其實就是找到一根直線也好曲線也好,能夠最佳程度擬合我們的資料點,在這裡,怎樣定義擬合其實就是迴歸演算法的關鍵。比如說我們之前學過的線性迴歸演算法定義擬合的方式,就是讓我們的資料點到我們預測的直線相應的MSE的值最小,而對於SVM演算法的思路來說,對擬
機器學習之支援向量機SVM Support Vector Machine (六) 高斯核調參
在支援向量機(以下簡稱SVM)的核函式中,高斯核(以下簡稱RBF)是最常用的,理論上 RBF一定不比線性核函式差,但是在實際應用中,卻面臨幾個重要超引數的調優問題。如果調的不好,可能比線性核函式還要差。所以實際應用中,能用線性核函式得到較好效果的都會選擇
零基礎學Java編程語言就要對癥下藥
選擇學習Java編程語言,大部分人還是沖著高薪就業去的,既然如此,就業是學習Java的最終目的,企業需要什麽我們就學什麽。熱點資訊 下面小編就來分析一下企業需要什麽,這些也是我們在學習中應該著重關心的。當然,如果你是因為興趣或是喜歡才學Java編程依然可以看一下,學以致用。
零基礎學python-3.7 還有一個程序 python讀寫文本
efi == put ret mode nbsp inpu exce for each 今天我們引入另外一個程序,文件的讀寫 我們先把簡單的程序代碼貼上。然後通過我們多次的改進。希望最後可以變成一個簡單的文本編輯器 以下是我們最簡單的代碼: ‘crudfile--讀寫文
關於零基礎學HTML5
arc footer intel a13 要求 初學者 lin 計算 工具 關於零基礎學HTML5,學習HTML5之前需要有CSS及JavaScript基礎,聽起來感覺很難,其實沒有想象的復雜。對於初學者來說,想要先學習CSS你只要具備最基本的計算機使用,剩下的老師都會
零基礎學python-4.2 其它內建類型
介紹 src one 一個 tex == water 文件 div 這一章節我們來聊聊其它內建類型 1.類型type 在python2.2的時候,type是通過字符串實現的,再後來才把類型和類統一 我們再次使用上一章節的圖片來說明一些問題 我們通
零基礎學python-2.7 列表與元組
cells one iss 顯示 不同 元組 jsb lsp ext 事實上,能夠把列表和元組看成普通的數組。可是這個數組能夠存儲不同的數據類型(對象) 列表和元組的差別 列表 元組 使用的符號 [] () 元素數量 可變 不可變 改動元素 不能