
支援向量機(support vector machine)(二):線性SVM
通常情況下,存在以下兩種情況:
1、分類完全正確的超平面不一定是最好的;
2、樣本資料不是線性可分的;
如圖1所示,如果按照完全分對這個準則來劃分時,L1為最優分割超平面,但是實際情況如果按照L2來進行劃分,效果可能會更好,分類結果會更加魯棒。
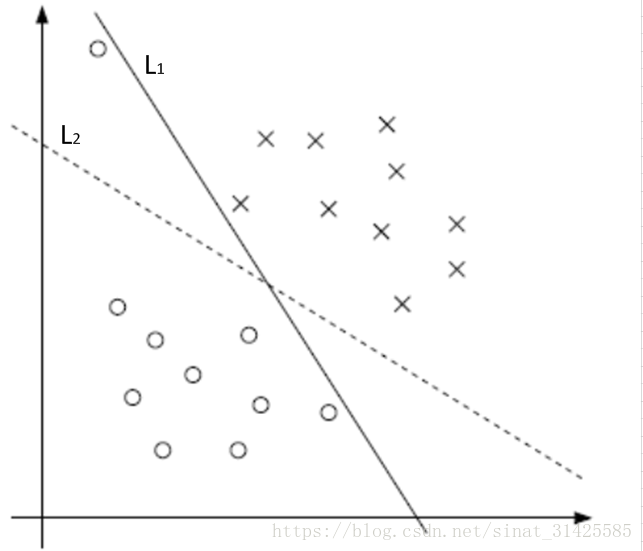
圖1 樣本分佈示意圖
通過引入鬆弛因子,放寬對於離群點的約束
,注意,如果
任意大,任意超平面都會符合條件,因此我們需要對
引入拉格朗日乘子有:
將L分別對求偏導有:
將三個條件回代到L有:
約束條件為:
第二個約束條件是因為,即
,得
這裡C需要預先設定引數,C越大,容許的就越小,對於離群點偏離群體的位置容忍度就越小,SVM對應排空區域(過渡帶)就越小,分類器容易發生過擬合;C越小,容許的
就越大,對於離群點偏離群體的位置容忍度就越大,SVM對應排空區域(過渡帶)就越大,C如果過小,分類器的效能就會較差。
參考資料:
支援向量機通俗導論(理解SVM的三層境界)
周志華. 機器學習 : = Machine learning[M]. 清華大學出版社, 2016.