
Lucene 查詢索引庫
以後用的分詞庫為IKAnalyzer中文分詞庫。
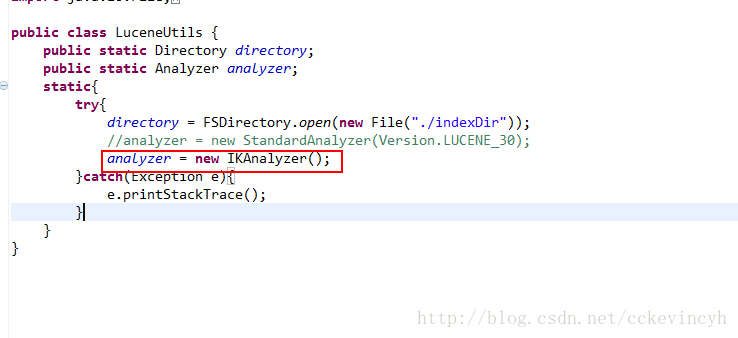
查詢
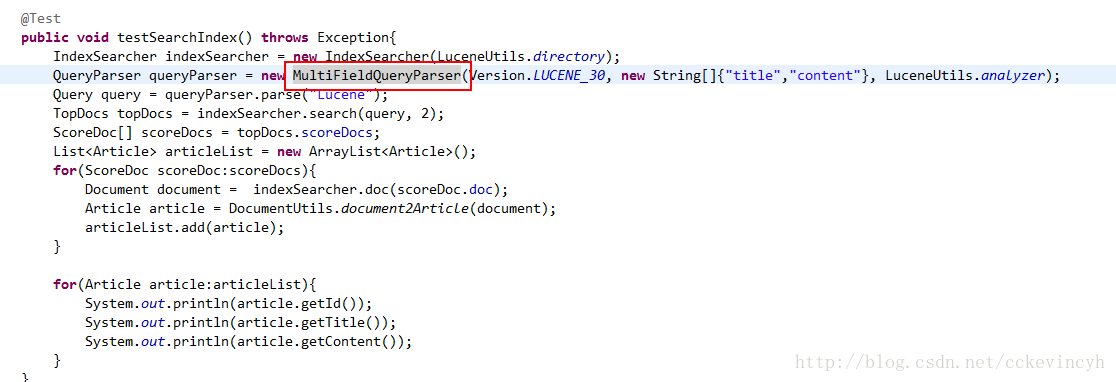
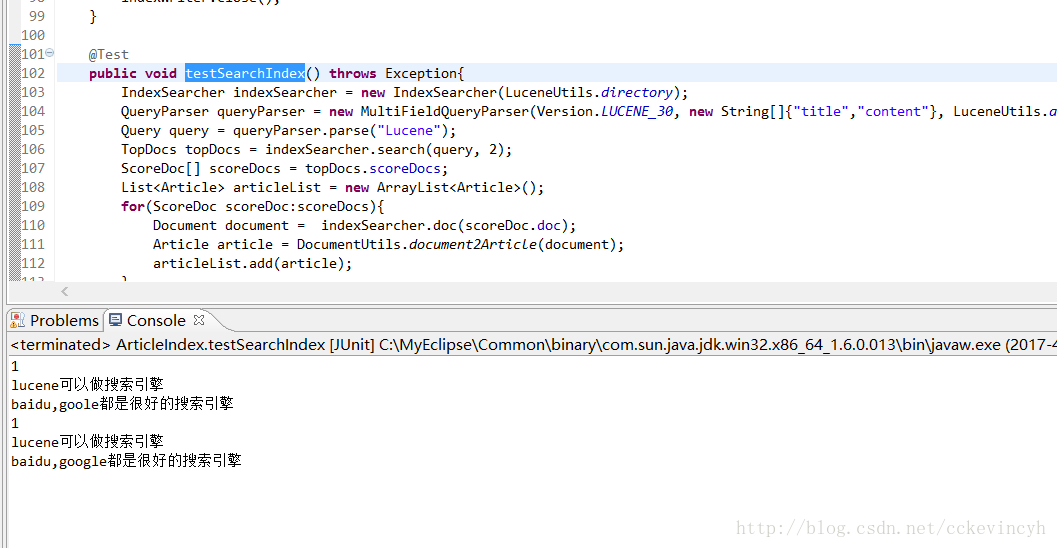
說明:這是QueryParser的繼承結構,在這裡我們用的是MultiFieldQueryParser.這個類的好處可以選擇多個屬性進行查詢。而QueryParser只能選擇一個。
分頁
先創建出資料:
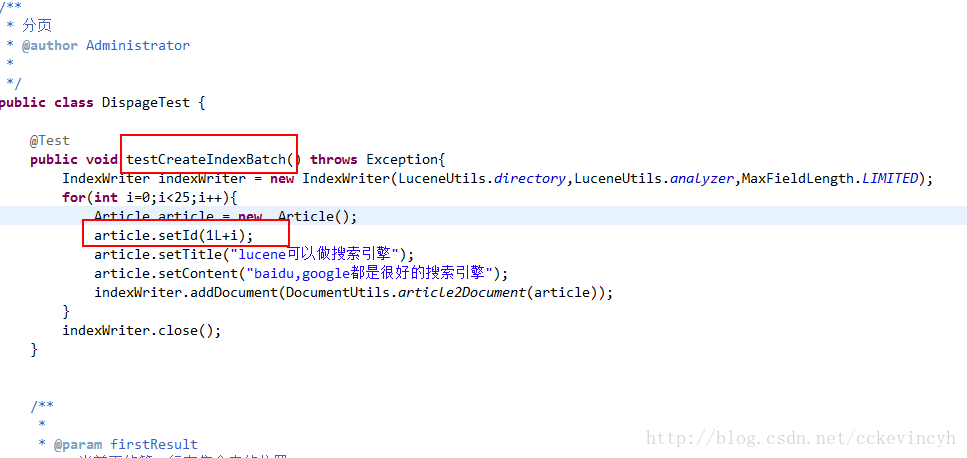

讀取資料看看是否建立成功:
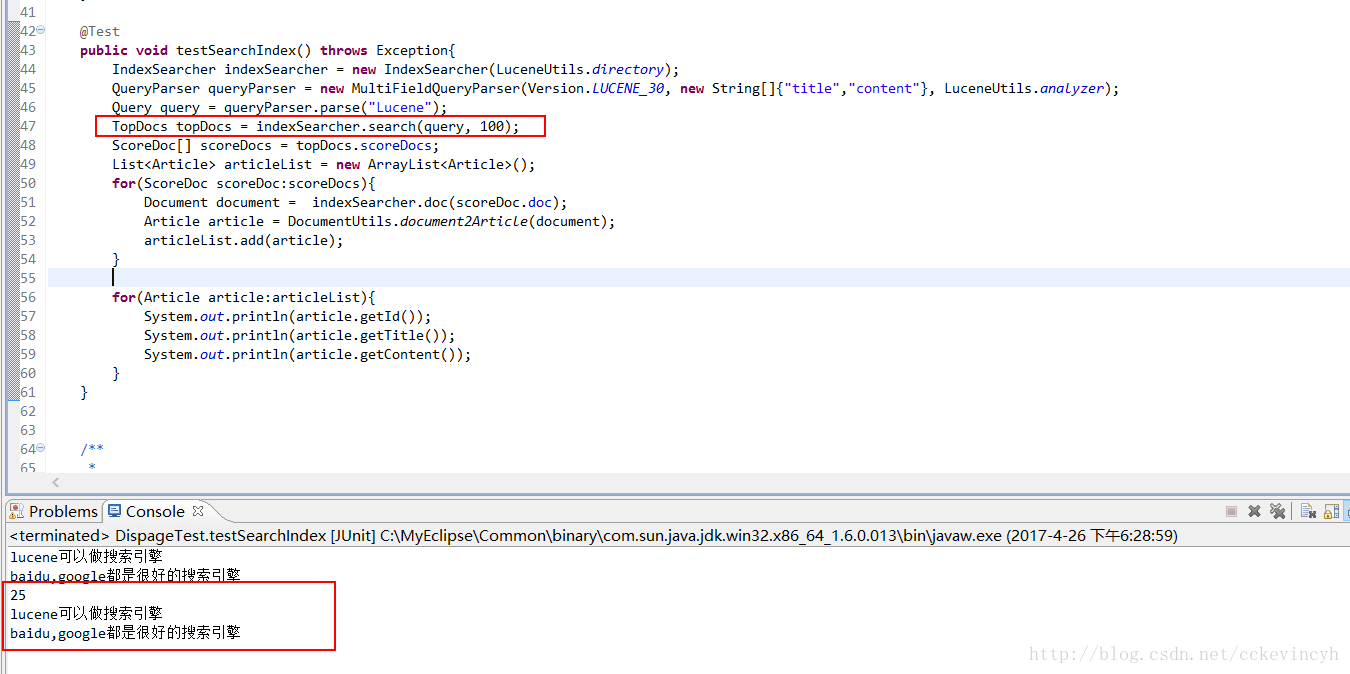
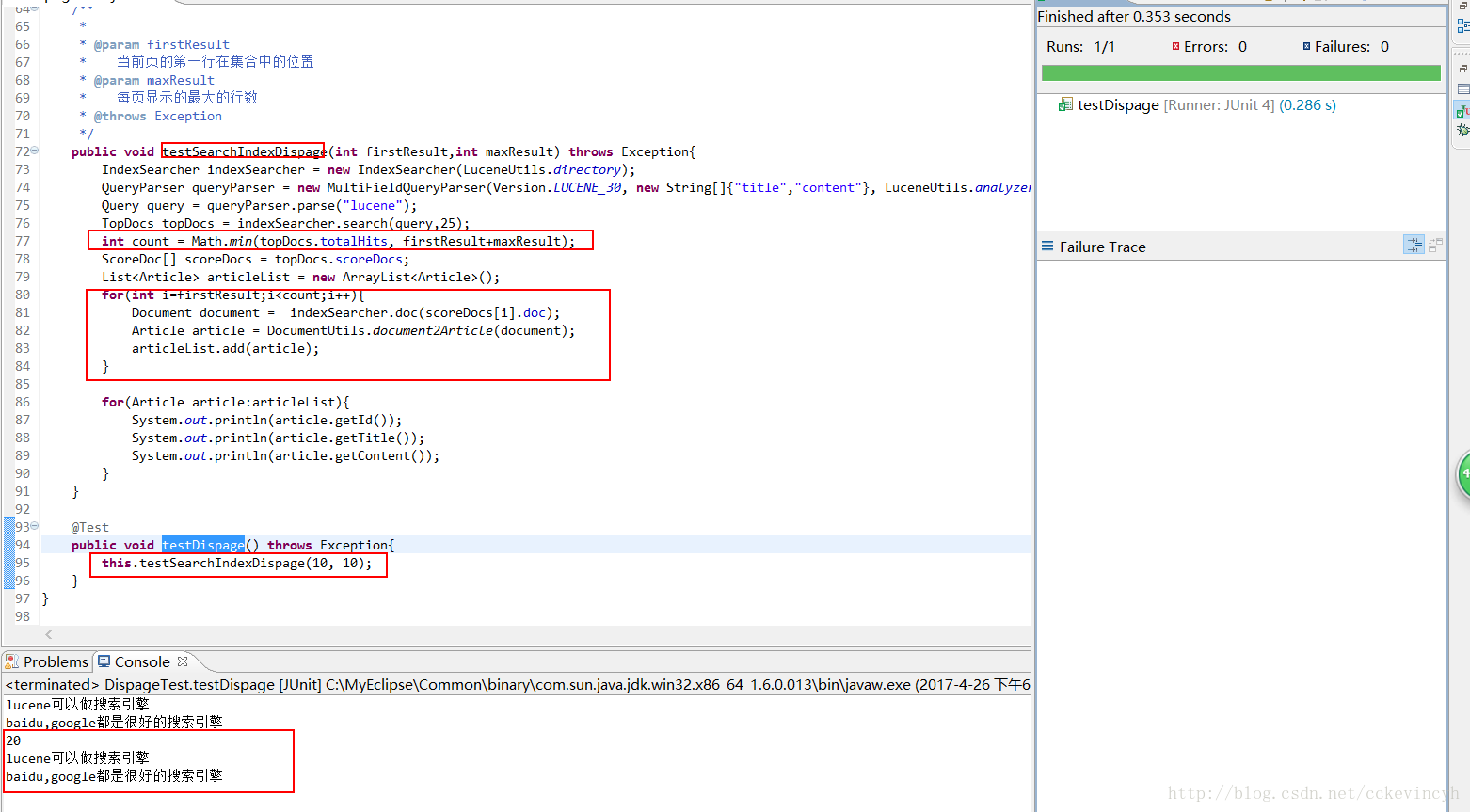
說明:
1) 在全文檢索系統中,一般查詢出來的內容比較多,所以必須將查詢出來的內容進行分頁處理。
2) 原理同hibernate的分頁查詢。在hibernate的分頁查詢中,有兩個引數:
int firstResult 當前頁的第一行在資料庫裡的行數
int maxResult 每頁顯示的頁數
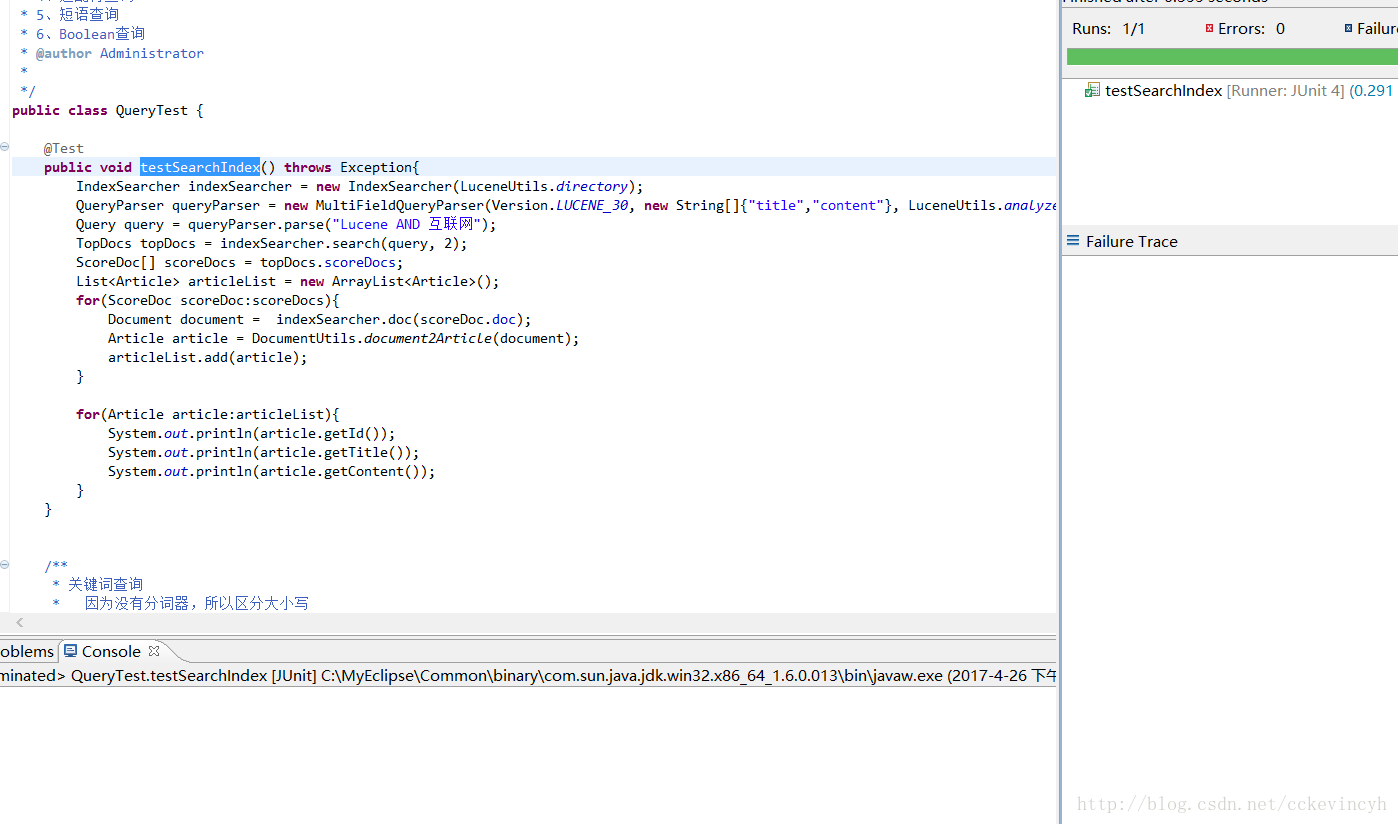
搜尋方式
使用查詢字串
QueryParser->Query物件
可以使用查詢條件
“lucene AND 網際網路” 都出現符合查詢條件
“lucene OR 網際網路” 只要出現其一就符合查詢條件
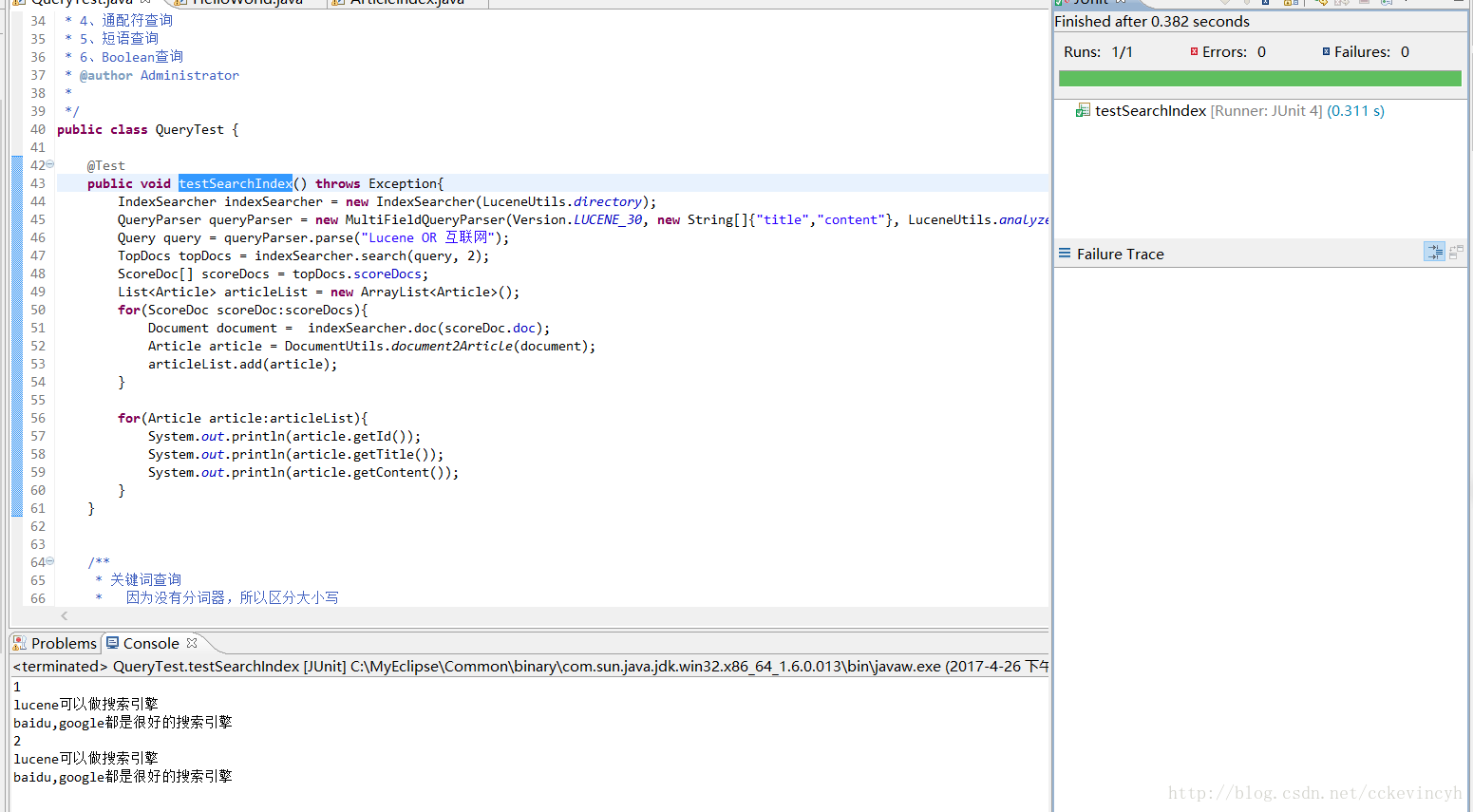
自己建立與配置Query物件
關鍵詞查詢(TermQuery)

注:因為儲存引索的時候是通過分詞器儲存,所以所有的因為在索引
庫裡都為小寫,所以lucene必須得小寫,不然查詢不到。如果使用
查詢字串進行查詢,對應的語法格式為:title:lucene
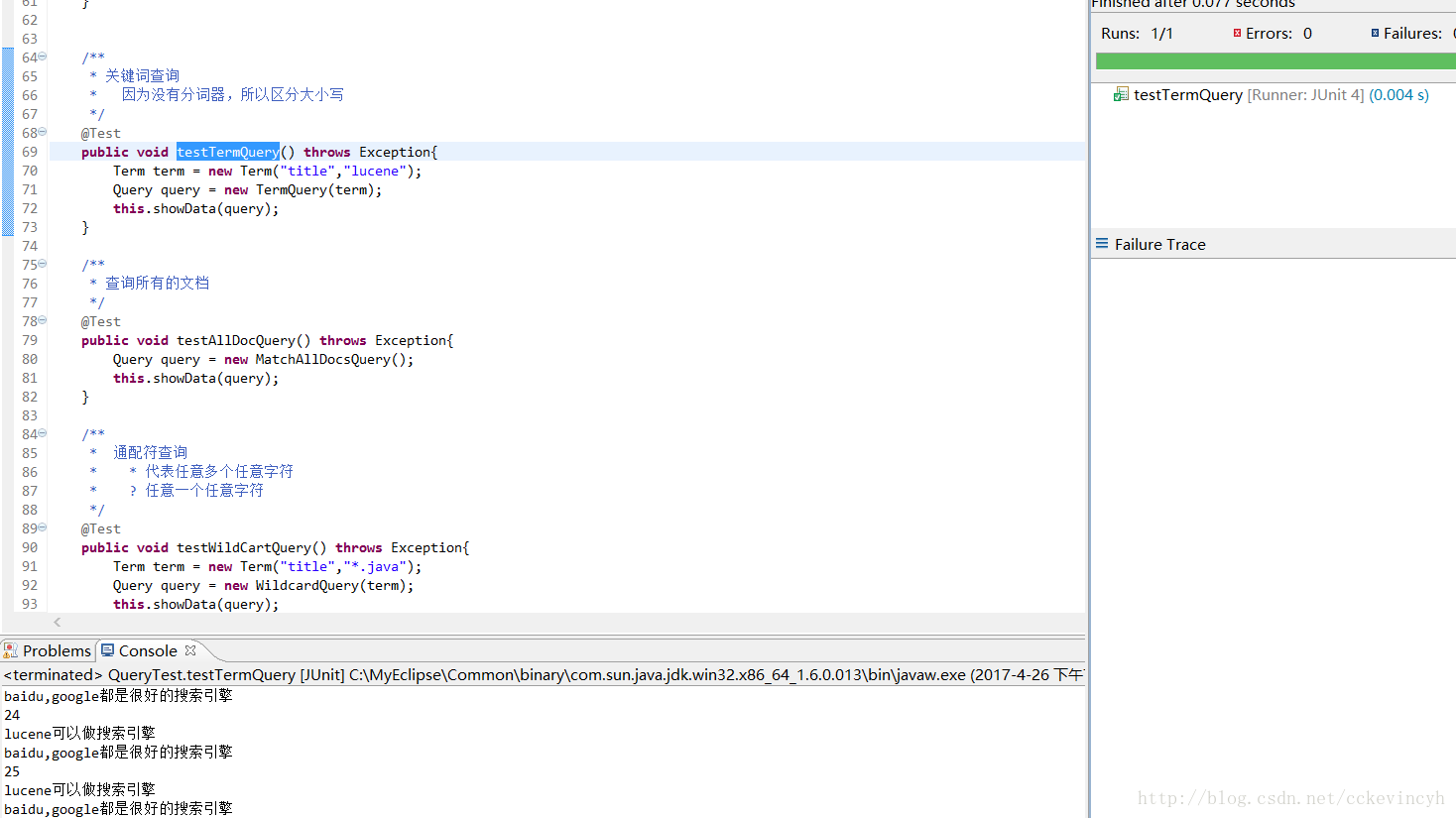
查詢所有文件
如果使用查詢字串,對應語法:*:*
範圍查詢
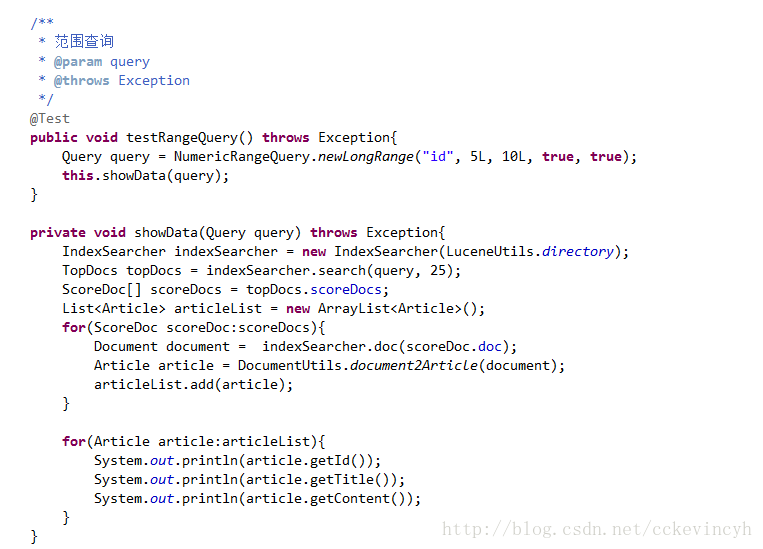
如果使用查詢字串,
第一個: id:[5 TO 15]
第二個: id:{5 TO 15}
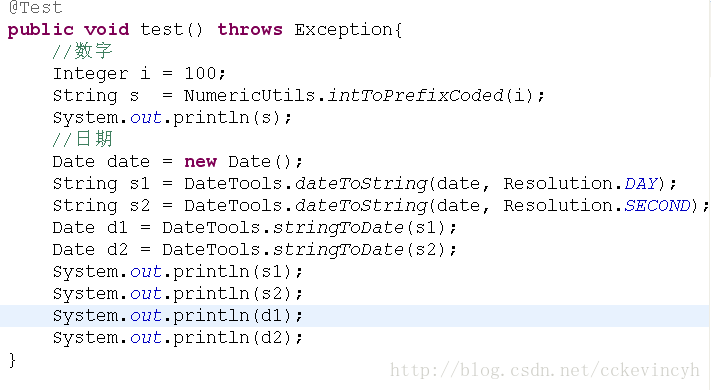
注:在lucene中,處理數字是不能直接寫入的,要進行轉化。NumberStringTools幫助類給出了轉化工具:
在工具類DocumentUtils中也做相應的轉化:

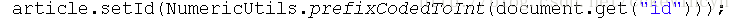
萬用字元查詢

如果使用查詢字串:title:lucen?
短語查詢

上面的0代表第0個位置
上面的1代表第3個位置
使用查詢字串:title:”lucene ? ? 網際網路”
Boolean查詢
可以把多個查詢條件組合成一個查詢條件

如圖為:同時滿足title中有lucene關鍵字和ID為5到15的所有索引資料。不包括5和15
使用查詢字串:+id:{5 TO 15} +title:lucene
注意:
1、 單獨使用MUST_NOT 沒有意義
2、 MUST_NOT和MUST_NOT 無意義,檢索無結果
3、單獨使用SHOULD:結果相當於MUST
4、SHOULD和MUST_NOT: 此時SHOULD相當於MUST,結果同MUST和MUST_NOT
5、MUST和SHOULD:此時SHOULD無意義,結果為MUST子句的檢索結果
過濾
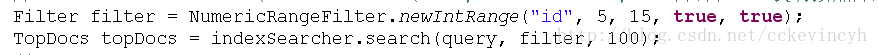
利用indexSearch.search的過載函式的過濾器引數實現對結果的過濾。從這裡可以看出這是一個範圍過濾器。第二個引數與第三個引數為5,15。但是lucene會把這兩個引數當作字串來對待。所以這樣搜尋結果為0。
進行如下處理:
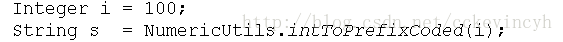
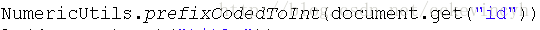
凡是數字型別的都必須經過這樣的方式進行處理。

凡是日期型別的都必須經過這樣的方式進行處理。這樣才能保證結果的正確性。
排序
相關度得分
實驗一:
在索引庫中內容完全相同的情況下,用幾個關鍵詞搜尋,看是否得分相同。
結果:
同一個關鍵詞得分對於所有的Document是一樣的。但是不同的關鍵詞的分數不一樣。關鍵詞和文字內容匹配越多,得分越高。也就是相關度得分就高
實驗二:
再插入一個Document,在其中的content中增加一個關鍵詞,然後儲存到索引庫中。如圖:

在content中,google的後面又加了一個詞”網際網路”。然後再進行搜尋,這個時候,id為26的被排到了第一位。相關度得分最高。因為其他的Document在content中匹配”網際網路”只有一處,而id為26的有兩處。
結果:
同一個關鍵詞如果在所有匹配的文字中的相關度得分不一樣,按照相關度得分從高到低的順序排列。
實驗三:
如果想從百度上排名第一,就得控制相關度得分。在lucene中,可以人為控制相關度得分。如圖:

利用Document.setBoost可以控制得分。預設值為1
結論:
利用Document.setBoost可以人為控制相關度得分,從而把某一個引索內容排到最前面。
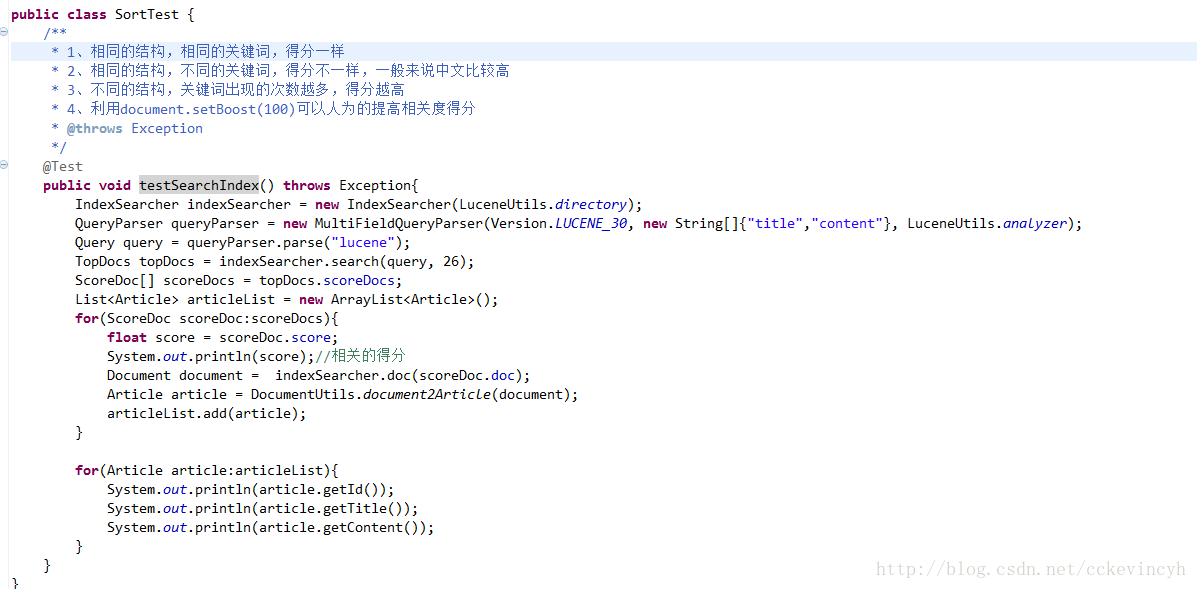
按照某個欄位進行排序

如圖所示的程式碼,過載了indexSearcher.search方法。在這個方法中,Sort對 象就是指定的按照id升序排列。SortField.INT指定了ID的型別。型別不一樣,大小的比較就不一樣。

上面程式碼查詢出來以後是按照id的升序排列。

這個程式碼為按照id的降序排列。其中最後一個引數為reverse
Reverse為false 升序(預設)
Reverse 為true 降序
注:按照某個欄位進行排序與相關度得分沒有關係。
高亮
高亮的作用
1) 使關鍵字的顏色和其他字的顏色不一樣,這樣關鍵字就比較突出。
方法:在關鍵字周圍加上字首和字尾
<font color=’red’>中國</font>2) 生成摘要(從關鍵詞出現最多的地方擷取一段文字),可以配置要擷取文字的字元數量。
程式設計步驟
/**
* 高亮
* * 使關鍵字變色
* * 設定
* * 使用
* * 控制摘要的大小
* @author Administrator
*/
public class HighlighterTest {
@Test
public void testSearchIndex() throws Exception{
IndexSearcher indexSearcher = new IndexSearcher(LuceneUtils.directory);
QueryParser queryParser = new MultiFieldQueryParser(Version.LUCENE_30, new String[]{"title","content"}, LuceneUtils.analyzer);
Query query = queryParser.parse("Lucene");
TopDocs topDocs = indexSearcher.search(query, 25);
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
/***********************************************************************/
/**
* 給關鍵字加上字首和字尾
*/
Formatter formatter = new SimpleHTMLFormatter("<font color='red'>","</font>");
/**
* scorer封裝了關鍵字
*/
Scorer scorer = new QueryScorer(query);
Highlighter highlighter = new Highlighter(formatter,scorer);
/**
* 建立一個摘要
*/
Fragmenter fragmenter = new SimpleFragmenter(10);
highlighter.setTextFragmenter(fragmenter);
/***********************************************************************/
List<Article> articleList = new ArrayList<Article>();
for(ScoreDoc scoreDoc:scoreDocs){
float score = scoreDoc.score;
System.out.println(score);//相關的得分
Document document = indexSearcher.doc(scoreDoc.doc);
Article article = DocumentUtils.document2Article(document);
/*
* 使用高亮器
*/
/**
* 1、分詞器
* 查詢關鍵詞
* 2、欄位
* 在哪個欄位上進行高亮
* 3、欄位的內容
* 把欄位的內容提取出來
*/
String titleText = highlighter.getBestFragment(LuceneUtils.analyzer, "title", document.get("title"));
String contentText = highlighter.getBestFragment(LuceneUtils.analyzer, "content", document.get("content"));
if(titleText!=null){
article.setTitle(titleText);
}
if(contentText!=null){
article.setContent(contentText);
}
articleList.add(article);
}
for(Article article:articleList){
System.out.println(article.getId());
System.out.println(article.getTitle());
System.out.println(article.getContent());
}
}
}建立和配置高量器
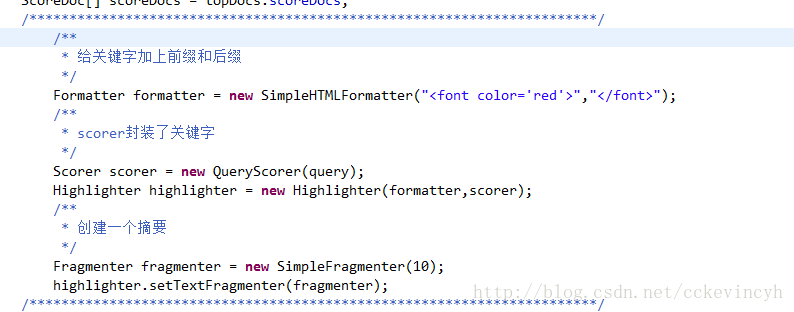

一個高亮器的建立需要兩個條件:
Formatter 要把關鍵詞顯示成什麼樣子
Scorer 查詢條件
Fragmenter設定文字的長度。預設為100。
如果文字的內容長度超過所設定的大小,超過的部分將顯示不出來。
使用高亮器
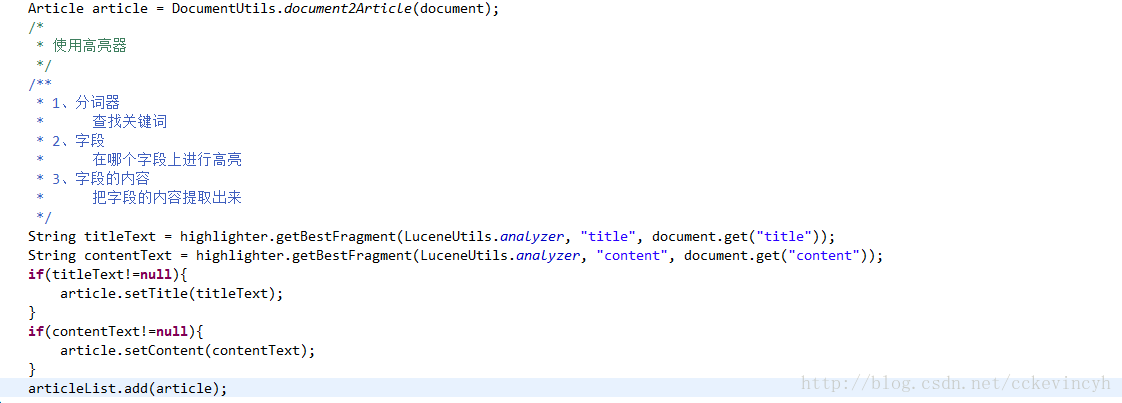

getBestFragment為得到高亮後的文字。
引數:
分詞器
如果是英文:StandardAnalyzer 如果是中文:IKAnalyzer在哪個屬性上進行高亮
- 要高亮的內容