
Elasticsearch面試題
問題一:
什麼是ElasticSearch?
Elasticsearch是一個基於Lucene的搜尋引擎。它提供了具有HTTP Web介面和無架構JSON文件的分散式,多租戶能力的全文搜尋引擎。Elasticsearch是用Java開發的,根據Apache許可條款作為開源釋出。
問題二:
您可以在文件上執行哪些基本操作?
可以在文件中進行以下操作:
a.使用ELASTICSEARCH索引文件內容。
b.使用ELASTICSEARCH抓取文件內容。
C.使用ELASTICSEARCH更新文件內容。
d.使用ELASTICSEARCH刪除文件內容。
問題三:
Elasticsearch中的倒排索引是什麼?
倒排索引是搜尋引擎的核心。搜尋引擎的主要目標是在查詢發生搜尋條件的文件時提供快速搜尋。倒排索引是一種像資料結構一樣的雜湊圖,可將使用者從單詞導向文件或網頁。它是搜尋引擎的核心。其主要目標是快速搜尋從數百萬檔案中查詢資料。
一般情況下,像下面的一樣,在書中我們已經倒過來索引。根據這個詞,我們可以找到這個詞所在的頁面。

請考慮以下列語句:
-
javainuse是一個很好的網站
-
javainuse是很好的網站之一。
為了索引的目的,上述文字被標記為單獨的術語,並且所有獨特術語被儲存在索引內,諸如該術語出現在哪個文件以及該文件中術語位置是什麼。 因此,檔案文字的倒排索引如下 :

當您搜尋術語網站或網站時,將針對倒排索引執行查詢並查詢術語,並快速識別出現這些術語的文件。
問題四:
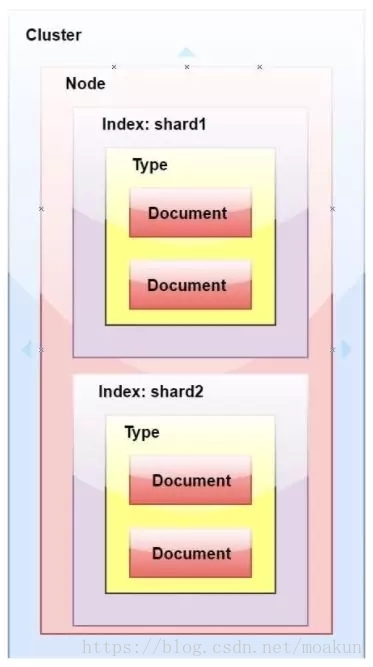
ElasticSearch中的叢集、節點、索引、文件、型別是什麼?
-
群集是一個或多個節點(伺服器)的集合,它們共同儲存您的整個資料,並提供跨所有節點的聯合索引和搜尋功能。群集由唯一名稱標識,預設情況下為“elasticsearch”。此名稱很重要,因為如果節點設定為按名稱加入群集,則該節點只能是群集的一部分。
-
節點是屬於叢集一部分的單個伺服器。它儲存資料並參與群集索引和搜尋功能。
-
索引就像關係資料庫中的“資料庫”。它有一個定義多種型別的對映。索引是邏輯名稱空間,對映到一個或多個主分片,並且可以有零個或多個副本分片。 MySQL =>資料庫 ElasticSearch =>索引
-
文件類似於關係資料庫中的一行。不同之處在於索引中的每個文件可以具有不同的結構(欄位),但是對於通用欄位應該具有相同的資料型別。 MySQL => Databases => Tables => Columns / Rows ElasticSearch => Indices => Types =>具有屬性的文件
-
型別是索引的邏輯類別/分割槽,其語義完全取決於使用者。
問題五:
ElasticSearch是否有架構?
ElasticSearch可以有一個架構。架構是描述文件型別以及如何處理文件的不同欄位的一個或多個欄位的描述。Elasticsearch中的架構是一種對映,它描述了JSON文件中的欄位及其資料型別,以及它們應該如何在Lucene索引中進行索引。因此,在Elasticsearch術語中,我們通常將此模式稱為“對映”。
Elasticsearch具有架構靈活的能力,這意味著可以在不明確提供架構的情況下索引文件。如果未指定對映,則預設情況下,Elasticsearch會在索引期間檢測文件中的新欄位時動態生成一個對映。
問題六:
ElasticSearch中的分片是什麼?
在大多數環境中,每個節點都在單獨的盒子或虛擬機器上執行。
-
索引 - 在Elasticsearch中,索引是文件的集合。
-
分片 -因為Elasticsearch是一個分散式搜尋引擎,所以索引通常被分割成分佈在多個節點上的被稱為分片的元素。
問題七:
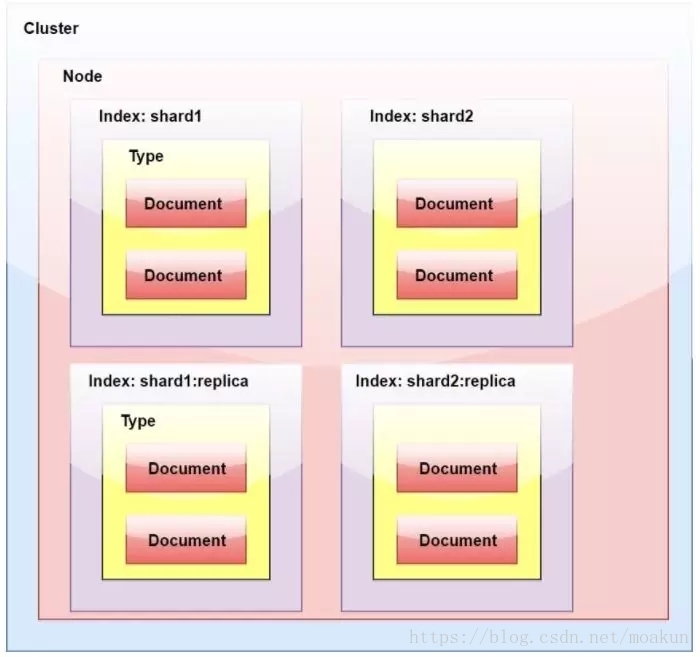
ElasticSearch中的副本是什麼?
一個索引被分解成碎片以便於分發和擴充套件。副本是分片的副本。一個節點是一個屬於一個叢集的ElasticSearch的執行例項。一個叢集由一個或多個共享相同叢集名稱的節點組成。
問題八:
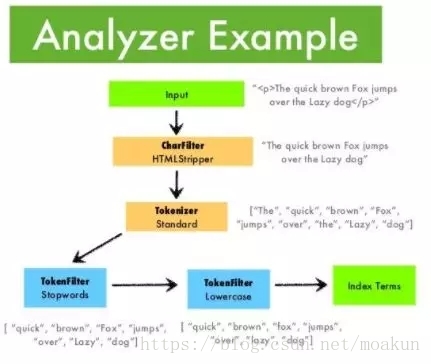
ElasticSearch中的分析器是什麼?
在ElasticSearch中索引資料時,資料由為索引定義的Analyzer在內部進行轉換。 分析器由一個Tokenizer和零個或多個TokenFilter組成。編譯器可以在一個或多個CharFilter之前。分析模組允許您在邏輯名稱下注冊分析器,然後可以在對映定義或某些API中引用它們。
Elasticsearch附帶了許多可以隨時使用的預建分析器。或者,您可以組合內建的字元過濾器,編譯器和過濾器器來建立自定義分析器。
問題九:
什麼是ElasticSearch中的編譯器?
編譯器用於將字串分解為術語或標記流。一個簡單的編譯器可能會將字串拆分為任何遇到空格或標點的地方。Elasticsearch有許多內建標記器,可用於構建自定義分析器。
問題十:
什麼是ElasticSearch中的過濾器?
資料由Tokenizer處理後,在編制索引之前,過濾器會對其進行處理。
問題十一:
啟用屬性,索引和儲存的用途是什麼?
enabled屬性適用於各類ElasticSearch特定/建立領域,如index和size。使用者提供的欄位沒有“已啟用”屬性。 儲存意味著資料由Lucene儲存,如果詢問,將返回這些資料。
儲存欄位不一定是可搜尋的。預設情況下,欄位不儲存,但原始檔是完整的。因為您希望使用預設值(這是有意義的),所以不要設定store屬性 該指數屬性用於搜尋。
索引屬性只能用於搜尋。只有索引域可以進行搜尋。差異的原因是在分析期間對索引欄位進行了轉換,因此如果需要的話,您不能檢索原始資料。