
pytorch入坑前言 | 最新0.4及其介紹
首先,pytorch是什麼呢?它是一個python的包,它有以下兩個特徵
- 類numpy的張量計算與利用GPU加速
- 建立在自動微分系統的深度神經網路
除此之外,你也可以利用你喜歡的python包,比如numpy, scipy 和Cython來進行拓展,下表是pytorch的核心庫。

Pytorch的特點:
- GPU支援的張量庫
如果你之前用過numpy,那麼你一定知道張量,張量就是多維度的矩陣,Pytorch 為張量的計算提供CPU和GPU兩種模式,在GPU模式下能極大地加速計算。而Numpy只有CPU計算。

同numpy類似,pytorch提供大量的張量數學計算,比如切分,檢索,和數學操作如線性代數等,最大限度的來適應你的科學計算需求
- 動態神經網路:
Pytorch 有獨特建立神經網路的機制,大多數的框架如 Tensorflow, Theano, Caffe 和CNTK 對於神經網路的建立都是靜態的,這意味著每次建立為完一個神經網路圖,這些框架會重複使用網路圖,改變網路圖的行為需要重頭來建立網路。在pytorch中,使用自動求微分系統,能允許你使用一些屬性改變網路圖的行為
從我的理解上來看: tensorflow 會建立一個完整的圖,每次向前傳播的時候可以選擇執行圖的某個部分,前提是圖需要包含每個分支,pytorch則是根據判斷來動態的建立圖,每次反向傳播都會釋放,所以每次都可以不一樣。
當你使用這些pytorch的特徵,它可以給你的研究賦予最快的速度和靈活性
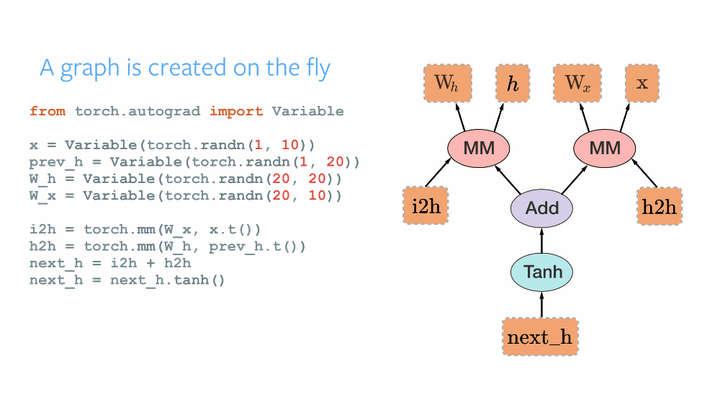
- Python優先:
Pytorch不是單獨和c++框架捆綁在一起的,這是一個和Python深度結合的框架,你可以自然的使用numpy/scipy/scikit-learn等等, 你也可以使用python寫出神經網路層,可以使用你喜歡的庫來擴充套件,比如用CPython來加速等等
- 直觀的體驗:
Pytorch 在設計上是直觀化,線性,和容易使用的。當你執行一條語句時,它不是非同步執行的,當你進行除錯,收到錯誤資訊時和堆疊追蹤時,理解它們是可以直觀體現的,每個錯誤追蹤點都會直接指向你所定義的程式碼, 它希望你在debugging的時候能花費最少的時間
- 快速和簡潔
Pytorch 有最簡潔的結構,pytorch通過集合 Intel MKL 和 NVIDIA的庫來實現速度上的優化,所以不管在大網路還是小網路都可以跑的很快。
- 便於拓展:
你可以很容易寫出新的網路模型,可以為你的網路層寫出c/c++的擴充套件等等
所以什麼人適合使用pytorch呢?如果你在尋找一個能使用GPU加速的類numpy的庫,或者一個能提供最大擴充套件性和速度的深度學習研究的平臺,那麼快來加入pytorch的懷抱吧!!!!
在介紹完pytorch後,我們終於迎來了最新的0.4 release版本,0.4開始官方支援windows平臺,這裡我參考官方的指南給出新版本的總結:
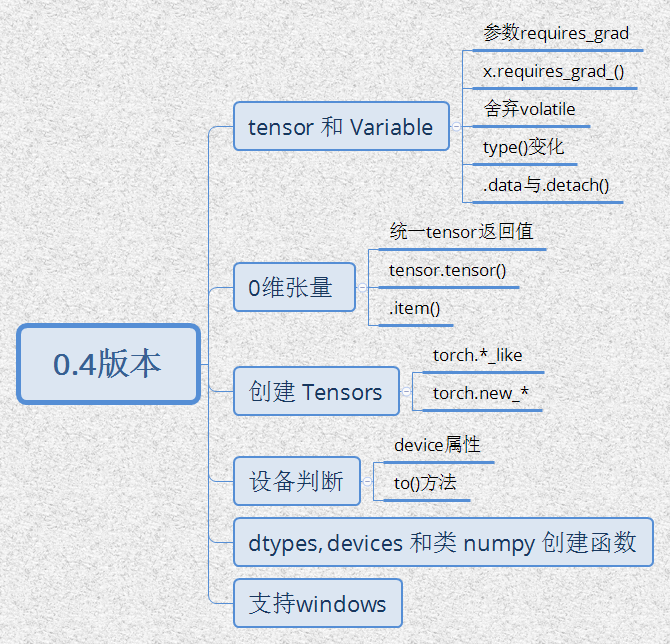
合併Tensor 和 Variable
Variable 仍然像以前一樣工作,只不過返回的是 Tensor . 這意味著我們使用的時候只需要宣告Tensor 就好了,更詳細的,torch.tensor可以像舊的Variable一樣對計算曆史進行追蹤了,你再也不用到處宣告Variable了
- 引數 requires_grad:
變數 requires_grad, Tensor 可以直接使用 requires_grad, 當任何 tensor 的操作有requires_grad = True, 自動微分系統就開始記錄,如下例:
>>> x = torch.ones(1) # 建立一個tensor預設requires_grad=False (default)
>>> x.requires_grad
False
>>> y = torch.ones(1) # 建立另一個tensor 預設requires_grad=False
>>> z = x + y
>>> z.requires_grad # 由於輸入的requires_grad都為false, 所以結果為false
False
>>> z.backward() # 這樣自動微分系統是不會計算的.驗證一下!
RuntimeError: element 0 of tensors does not require grad and
does not have a grad_fn
>>> w = torch.ones(1, requires_grad=True) # 現在建立一個tensor使得requires_grad=True
>>> w.requires_grad
True
>>> total = w + z # 現在建立一個tensor使得requires_grad=True
>>> total.requires_grad #求和處理,由於有一個grad=True,所以結果為
True
>>> total.backward() #可以進行反向傳播
>>> w.grad
tensor([ 1.])
>>> # and no computation is wasted to compute
gradients for x, y and z, which don't require grad
>>> z.grad == x.grad == y.grad == None
True
- in-place 操作 x.requires_grad_()
使用 x.requires_grad_() 這樣的 in-place 操作來直接設定 requires_grad 的屬性,
>>> existing_tensor.requires_grad_()
>>> existing_tensor.requires_grad
True
- 捨棄volatile
Variable 中的 volatile 已經沒有作用了,已經被torch.no_grad(), torch.set_grad_ena ble (grad_mode) 等其他代替了.下面是幾種使用方法:
>>> x = torch.zeros(1, requires_grad=True)
>>> with torch.no_grad():
... y = x * 2
>>> y.requires_grad #False
-----------------------------------------------------------------------------
>>> is_train = False
>>> with torch.set_grad_enabled(is_train):
... y = x * 2
>>> y.requires_grad #False
----------------------------------------------------------------------------
>>> torch.set_grad_enabled(True) # 能作為函式使用
>>> y = x * 2
>>> y.requires_grad #True
>>> torch.set_grad_enabled(False)
>>> y = x * 2
>>> y.requires_grad #False
- Type()的變化
type() 不再返回資料型別只返回 class, 建議使用 isinstance() 或 x.type()
>>> x = torch.DoubleTensor([1, 1, 1])
>>> print(type(x)) # 0.31版本 返回 ‘’torch.DoubleTensor‘’
"<class 'torch.Tensor'>"
>>> print(x.type()) # 同0.31版本一樣,返回 'torch.DoubleTensor'
'torch.DoubleTensor'
>>> print(isinstance(x, torch.DoubleTensor)) # OK: True
True
- .data 與 .detach()
.data 仍保留,但建議使用 .detach(), 區別在於 .data 返回和 x 的相同資料 tensor, 但不會加入到x的計算曆史裡,且require s_grad = False, 這樣有些時候是不安全的, 因為 x.data 不能被 autograd 追蹤求微分 。 .detach() 返回相同資料的 tensor ,且 requires_grad=False ,但能通過 in-place 操作報告給 autograd 在進行反向傳播的時候.
data例子:
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> c = out.data
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的數值被c.zero_()修改
tensor([ 0., 0., 0.])
>>> out.sum().backward() # 反向傳播
>>> a.grad # 這個結果很嚴重的錯誤,因為out已經改變了
tensor([ 0., 0., 0.])
detach()例子
>>> a = torch.tensor([1,2,3.], requires_grad =True)
>>> out = a.sigmoid()
>>> c = out.detach()
>>> c.zero_()
tensor([ 0., 0., 0.])
>>> out # out的值被c.zero_()修改 !!
tensor([ 0., 0., 0.])
>>> out.sum().backward() # 需要原來out得值,但是已經被c.zero_()覆蓋了,結果報錯
RuntimeError: one of the variables needed for gradient
computation has been modified by an
支援 0 維 的張量tensor
- 統一tensor返回值
在之前的版本中,一維的 tensor 和 Variable 在檢索和降維操作上會有不同,比如 tensor 的檢索返回 python number, 但 Variable 返回size為 (1,) 的 variable 向量, 同樣的情況出現在 tensor.sum() 上。
- Tensor.tensor() 直接生成0維張量
另外新版本中可以使用 torch.tensor() 直接生成0維的張量,最好理解是將 torch.tensor看做是numpy.array
- .item() 獲得 python number
由於統一返回值,tensor 返回都為 tensor , 為了獲得 python number 現在需要通過.item()來實現,考慮到之前的 loss 累加為 total_loss +=loss.data[0], 由於現在 loss 為0維張量, 0維檢索是沒有意義的,所以應該使用 total_loss+=loss.item(),通過.item() 從張量中獲得 python number.
需要注意的是, 如果你的 loss 不轉為 python number 再累加,你可能會發現你的記憶體消耗一直在增加。這是因為0維張量會增加梯度的計算曆史。
>>> torch.tensor(3) # 直接生成0維張量,0.3版本中會生成torch.size([3])的張量
tensor(3)
>>> torch.tensor(3).size() # 張量為0維
torch.Size([])
>>> vector = torch.arange(2, 6) # 生成一個向量
>>> vector[3] # 檢索返回張量, 0.31版本直接返回python
number
tensor(5.)
>>> vector[3].item() # 通過.item()返回python number
5.0
>>> mysum = torch.tensor([2, 3]).sum() # .sum()等操作也同意返回張量
>>> mysum
tensor(5)
>>> mysum.size()
torch.Size([])
dtypes, devices 和 類numpy 生成函式
在前作的版本中, 我們需要對於資料型別, 裝置和分佈情況 (密集和稀疏) 在' tensor type' 裡, 比如 torch.cuda.sparse.DoubleTensor 是double的tensor型別。
在新版本中,我們引入 torch.dtype, torch.device 和torch.layout 類來分別管理這些特性
- Torch.dtype
下面是完整的 dtype 列表,張量的 dtype 可以通過其 dtype 屬性來獲得

- Torch.device
Torch.device 包含了一個裝置型別('cpu'或者'cuda') 和一個可選的該裝置的序列號 (id) 可以被初始化為 torch.device('{device_type}') 或 torch.device('{device_type}:{device_ or dinal}' 如果裝置的序列號沒有被定義,那麼預設使用當前的裝置,比如 torch.device('cuda' ) 等於 torch.device('cuda:X') ,其中 X 是 torch.cuda.current_device( ) 的返回值
對於張量的裝置型別可以通過其 device 屬性獲得
- Torch.layout
Torch.layout 代表了資料分佈型別,目前支援 torch.strided 和 torch.sparse_coo 型別
張量的 layout 情況可以通過其 layout 屬性獲得
建立Tensors
在新版本中,建立一個 tensors 可以特別指明 dtype,device, layout 和 requires_grad 來返回特定的 tensor, 如果 dtype 型別未指明,pytorch 會給資料賦予最合適的型別,比如:
>>> x = torch.randn(3, 3, dtype=torch.float64,
device=device)
tensor([[-0.6344, 0.8562,-1.2758],
[ 0.8414, 1.7962, 1.0589],
[-0.1369, -1.0462,-0.4373]], dtype=torch.float64, device='cuda:1')
>>> torch.tensor([1, 2.3]).dtype # type inferece
torch.float32
>>> torch.tensor([1, 2]).dtype # type inferece
torch.int64
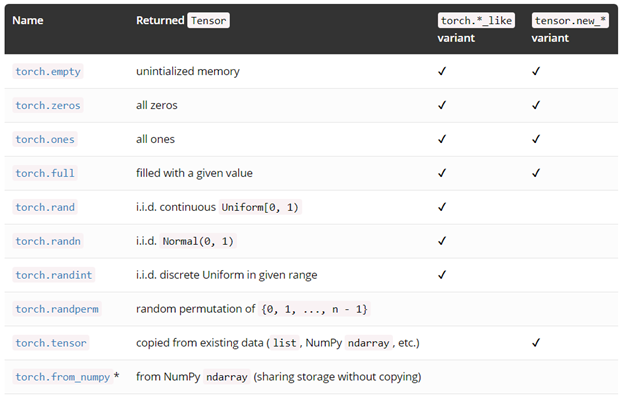
另外更多的建立 tensor 的方法,其中有些擁有 torch.*_like 和 tensor.new_* 的方法
- torch.*_like
利用tensor作為輸入而不是 tesnor.size(), 會返回一個指定資料並具有與輸入相同屬性的tensor
>>> x = torch.randn(3, dtype=torch.float64)
>>>
torch.zeros_like(x)
tensor([ 0., 0., 0.], dtype=torch.float64)
- torch.new_*
同樣返回一個與輸入具有相同屬性的 tensor, 但輸入需要指定張量形狀
>>> x = torch.randn(3, dtype=torch.float64)
>>>
x.new_ones(2)
tensor([ 1., 1.], dtype=torch.float64)
指定生成特殊張量,你可以利用元組或變數作為引數,如 torch.zeros((2,3))和torch.zero(2,3)
裝置判斷:
前一個版本 pytorch 很難寫程式碼去判斷裝置無關等,Pytorch 0.4.0做了下面兩個調整:
- device 屬性適用於所有 tensor 的 tensor.device
- to 方法可以輕鬆的將目標從一個裝置轉移到另一個裝置(比如從 cpu 到 cuda )
Pytorch 推薦如下程式碼來實現
# at beginning of the script
device = torch.device("cuda:0" if
torch.cuda.is_available() else "cpu")
...
# then whenever you get a new Tensor or Module
# this won't copy if they are already on the desired device
input = data.to(device)
model = MyModule(...).to(device)
最後
下面的程式碼將前面的全部集合,程式碼如下,讓我們happy pytorch-ing
0.3.1 (old):
model = MyRNN()
if use_cuda:
model = model.cuda()
# train
total_loss = 0
for input, target in train_loader:
input, target = Variable(input), Variable(target)
hidden =Variable(torch.zeros(*h_shape)) # inithidden
if use_cuda:
input, target, hidden = input.cuda(), target.cuda(), hidden.cuda()
... # get loss and optimize
total_loss +=loss.data[0]
# evaluate
for input, target in test_loader:
input = Variable(input, volatile=True)
if use_cuda:
...
...
0.4.0 (new):
# torch.device object used throughout this script
device = torch.device("cuda" if use_cuda else "cpu")
model = MyRNN().to(device)
# train
total_loss = 0
for input, target in train_loader:
input, target = input.to(device), target.to(device)
hidden = input.new_zeros(*h_shape) # has the same device & dtype as `input`
... # get loss and optimize
total_loss += loss.item() # get Python number from 1-element Tensor
# evaluate
with torch.no_grad(): # operations inside don't track history
for input, target in test_loader:
...請支援原創,本部落格純屬個人興趣愛好!