
python-爬蟲-requests的基本方法函式
1、安裝
Win 平臺:“以管理員身份執行” cmd,執行 pip install requests
小測:
>>>import requests
>>>r=requests.get("http://www.baidu.com")
>>>print(r.status_code)
200
>>>r.text
2、Requests庫的7個主要方法

3、Response物件的屬性


4、理解Requests庫的異常
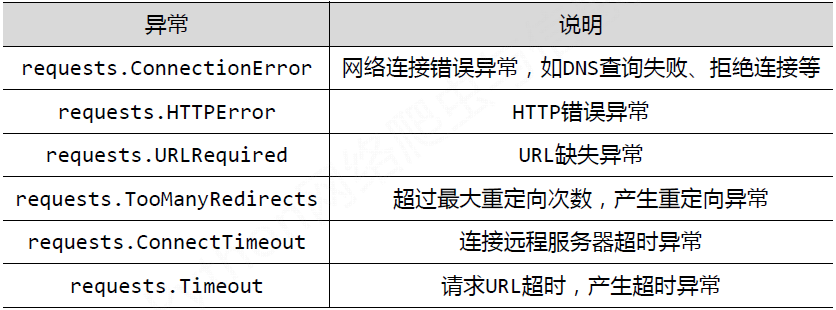

5、爬去網頁的通用程式碼框架
import requests
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status() #如果狀態不是200,引發HTMLError異常
r.encoding=r.apparent_encoding
return r.text
except:
return "產生異常"
if __name__=="__main__":
url="http://www.baidu.com"
print(getHTMLText(url))
6、HTTP協議
HTTP,Hypertext Transfer Protocol,超文字傳輸協議
HTTP是一個基於“請求與響應”模式的、無狀態的應用層協議
HTTP URL的理解:URL是通過HTTP協議存取資源的Internet路徑,一個URL對應一個數據資源
方法細節往下看!!!
響應內容資訊獲取 ,響應頭的建立
1、響應狀態碼
import requests
r = requests.get('https://api.github.com/some/endpoint')
print(r.status_code) #響應狀態碼
print(r.status_code==requests.codes.ok) #內建狀態碼查詢物件
r.raise_for_status() #通過 Response.raise_for_status() 來丟擲異常2、響應頭資訊
import 還有一個特殊點,那就是伺服器可以多次接受同一 header,每次都使用不同的值。但 Requests 會將它們合併,這樣它們就可以用一個對映來表示出來
3、如果某些請求包含cookie,可以使用以下命令獲得cookie
獲取響應資訊中的cookie
import requests
r = requests.get('https://api.douban.com/v2/book/search?小王子')
print(r.cookies)
print(r.cookies['bid'])在傳送請求時加入cookie引數
import requests
url= 'http://httpbin.org/cookies'
cookies = dict(cookies_are='working')
r = requests.get(url,cookies=cookies)
print(r.text)
r.request.headers 二、重定向與請求歷史
import requests
r = requests.get('http://github.com')
print(r.history)
>>[<Response [301]>]通過 allow_redirects 引數禁用重定向處理
import requests
r = requests.get('http://github.com',allow_redirects=False)
print(r.status_code)
print(r.history)
>>301
>>[]使用head重啟重定向
import requests
r = requests.head('http://github.com',allow_redirects=True)
print(r.url)
print(r.status_code)
print(r.history)傳送get,post請求
- res=requests.get(url) #傳送get請求,請求url地址對應的響應
- res=requests.post(url,data={請求的字典}) #傳送post請求
#post請求
import requests
url="http://fanyi.baidu.com/sug"
data={'kw':'早上好'}#該字典鍵值對的形式可以通過form data中查詢
headers={
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Mobile Safari/537.36"
}
res=requests.post(url,data=data,headers=headers)
print(res.text)response方法
- res.text(該方法往往會出現亂碼,出現亂碼使用res.encoding=’utf-8’ 或者res.encoding=res.apparent_encoding)
- res.content.decode(‘utf-8’)#或者’gbk’
- res.json() #針對響應為json字串解碼為python字典
- res.request.url #傳送請求的url地址
- res.url #res響應的url地址(頁面跳轉時,請求的url地址與真正開啟的url地址是不同的)
- res.request.headers #請求頭
- res.headers #res響應頭
傳送帶有header的請求
headers={請求體}#User-agent>>>Referer>>Cookie
-為了模擬瀏覽器,獲取和瀏覽器一樣的內容
超時引數 timeout
requests.get(url,headers=headers,timeout=3) #3秒內必須返回響應,否則會報錯
一般為了避免再發出請求過程中出現異常而中斷請求,一般採用retrying中的retry函式(作為裝飾器呼叫)
from retrying import retry
import requests
@retry(stop_max_attempt_number=3) #讓被裝飾的函式反覆執行三次,三次全部報錯才會報錯;中間有一次正常,程式繼續執行
def _parse_url(url):
print("列印效果")
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
res=requests.get(url,headers=headers,timeout=5)
# print(res.content.decode('utf-8'))
print(res.status_code)
#增加異常處理
def parse_url(url):
try:
html_str=_parse_url(url)
except:
html_str=None
return html_str
if __name__ == '__main__':
url = 'http://www.baidu.com'
parse_url(url)處理cookie請求
直接攜帶cookie請求url地址
1.cookie放在headers中
2.cookie字典傳給cookies引數
cookie=”….”#通過字典推導式得到
cookie_dict={i.split(“=”)[0]: i.split(“=”)[1] for i in cookie.split(“;”)}
requests.get(url,headers=headers,cookies=cookie_dict)先發送post請求,獲取cookie,帶上cookie請求登陸後的頁面 —requests.session() 會話保持
1.例項化session
session=requests.session()#此時session例項同requests一樣
2.session.post(url,data,headers)#伺服器設定在本地的cookie會被儲存在被session中注意post請求的url可以通過兩種方式獲取:
-檢視該登陸頁面的原始碼,找到form表單中的action提交的連結 -在登陸頁面的NETWORK中勾選Perserver log,然後再頁面跳轉後找到post請求的url3.session.get(url)#發出get請求會帶上之前儲存在session中的cookie,能夠請求成功
#爬去人人網資訊
#方法1--沒有cookie的html資訊
import requests
url="http://zhibo.renren.com/top"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
res=requests.get(url,headers=headers,timeout=5)
with open('renren1.html','w',encoding='utf-8') as f:
f.write(res.content.decode())
#方法2---在headers中放入cookie(在html中nx.user會出現使用者名稱)
import requests
url="http://zhibo.renren.com/top"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36",
"Cookie":"anonymid=jf3bo25ktzrg8e; depovince=SH; _r01_=1; ick_login=89a0be82-b23f-4aa2-9587-80b352b7d64f; _de=ED5538112FD97F3944B0A57815E527E7696BF75400CE19CC; ick=cb553aab-cde4-413f-864d-25644c96ea00; __utma=151146938.1210742990.1521771869.1521771869.1521771869.1; __utmc=151146938; __utmz=151146938.1521771869.1.1.utmcsr=renren.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmt=1; __utmb=151146938.1.10.1521771869; t=5812e6c25a16acd7d295e245218a8cd49; societyguester=5812e6c25a16acd7d295e245218a8cd49; id=964865629; xnsid=af52771f; XNESSESSIONID=292a42dae8f0; WebOnLineNotice_964865629=1; ch_id=10016; JSESSIONID=abcJKBMLTnzbs_aP1Rqjw; springskin=set; vip=1; wp_fold=0; jebecookies=cdb11dcd-461b-46e2-bfc5-9548dbe6a95e|||||"
}
res=requests.get(url,headers=headers,timeout=5)
with open('renren2.html','w',encoding='utf-8') as f:
f.write(res.content.decode())
#方法3--requests.session方法
import requests
session=requests.session()#例項化session
post_url="http://www.renren.com/PLogin.do" #此處的url地址是form表單中action的地址
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
post_data={
'email':'17612167260',
'password':'068499'}
session.post(url,headers=headers,data=post_data)#使用session傳送post請求,獲取儲存在本地的cookie
url="http://zhibo.renren.com/top"#次數的url是登陸頁面的url
res=session.get(url,headers=headers)#使用session,請求登陸後的頁面
with open('renren3.html','w',encoding='utf-8') as f:
f.write(res.content.decode()) 上傳檔案 files
import requests
#建立files檔案字典
dict_files={"file":open(r"C:\Users\poliy\Desktop\Crawler\1.png","rb")}
response=requests.post("http://httpbin.org/post",files=dict_files)
print(response.text)證書認證 (12306證書認證)
#方法1---設定verify=False,並取消提示警告
import requestsfrom requests.packages import urllib3import ssl
context = ssl._create_unverified_context()
urllib3.disable_warnings()
res=requests.get("https://www.12306.cn",verify=False)
print(res.status_code)
#方法2--通過cert引數放入證書路徑
res=requests.get("https://www.12306.cn",cert='PATH')設定代理
import requests
my_proxies={
"http":"http://61.135.217.7:80",
"https":"https://42.96.168.79:8888"
}
res=requests.get("https://www.baidu.com",proxies=my_proxies)
print(res.text)異常處理
requests的異常都在requests.exceptions中
import requests
from requests.exceptions import ReadTimeout,ConnectionError,RequestException
try:
res=requests.get("http://httpbin.org/get",timeout=0.1)
print(res.status_code)
except ReadTimeout:
print("timeout")
except ConnectionError:
print("timeout")
except RequestException:
print("error")