
java併發程式設計——ConcurrentHashMap(1.8)
阿新 • • 發佈:2019-02-03
請先閱讀ConcurrentHashMap1.7原始碼閱讀,對JDK1.7(1.6中也基本一致)中的ConcurrentHashMap有個大致瞭解。
前言
本文通過閱讀原始碼,藉助debug方式對費解的地方嘗試逐句分析.透徹的講解1.8版本ConcurrentHashMap
我們閱讀原始碼的思路是從一個使用樣例入手,一步步debug去分析:
public class ConcurrentHashMapTest {
public static void main(String[] args) throws InterruptedException {
//閱讀初始化原始碼 初始化ConcurrentHashMap
重要成員變數:
/**
* 負數(hash buckets正在初始化或者重新擴容):
* -1:表示初始化;-|n|表示n-1個執行緒正在執行resize。
*
* 正數或0:
* 0:表示hash buckets表還沒有被初始化;
* 正數:初始化hash buckets之前,表示hash buckets的陣列size(capacity).
* 初始化之後,表示下一次擴容的閾值,
* 它的值始終是當前ConcurrentHashMap容量的0.75倍
* (使用位運算提高效率:n - (n >>> 2)==n*0.75),
* 這與loadfactor是對應的.
*
* 可以看到,與之前版本實現比較,一個volatile int sizeCtl變數充當了多種身份.
*/ /**
* @param initialCapacity 初始化的容量,通過位運算根據這個值計算出一個2的N次冪的值,來作為 hash buckets陣列的size.
* 預設16
* @param loadFactor hash buckets的密度,根據這個值來確定是否需要擴容.預設0.75
* @param concurrencyLevel 併發更新執行緒的預估數量.預設1.
*/
public ConcurrentHashMap8(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long) (1.0 + (long) initialCapacity / loadFactor);
int cap = (size >= (long) MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int) size);
this.sizeCtl = cap;//初始化為cap
} /**
* 根據預期的capacity引數,返回一個2的N次冪
*/
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}關於這個talbeSizeFor(int c)所用的演算法,詳情參考:
tableSizeFor取數演算法
ConcurrentHashMap底層資料結構
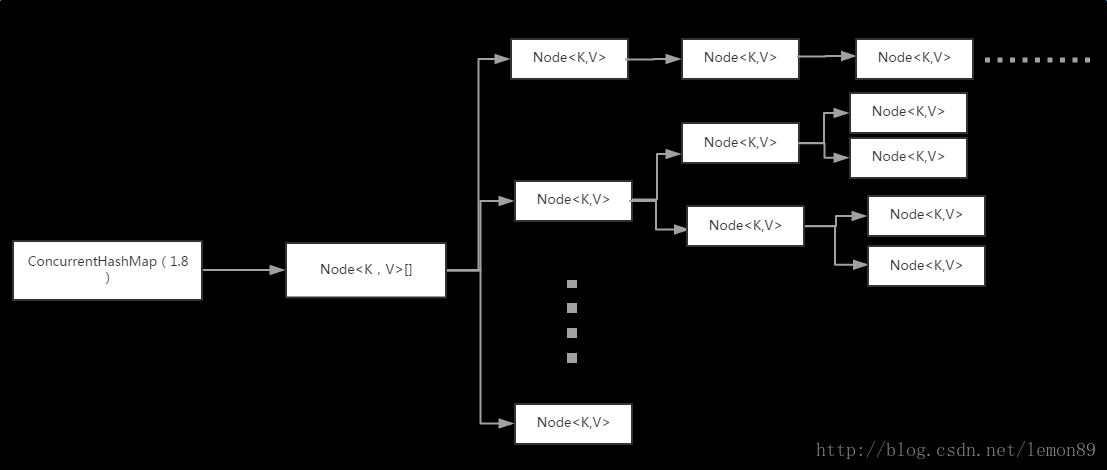
ConcurrentHashMap通過組合一個 Node<K, V>[] table陣列+Node單向連結串列,來作為底層資料儲存的結構。
static class Node<K, V> implements Map.Entry<K, V> {
final int hash;//key的hashcode執行了hash函式後的值
final K key;
volatile V val;//volatile保證其可見性,下同
volatile Node<K, V> next;
Node(int hash, K key, V val, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.val = val;
this.next = next;
}
....Put
與HashMap不同(允許key、value為null),ConcurrentHashMap中key、value都不允許為null,否則會報NPE。
put
public V put(K key, V value) {
return putVal(key, value, false);
}putVal
// onlyIfAbsent預設為false,允許key相同的value被覆蓋
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null)
throw new NullPointerException();
// hash=(h ^(h >>>16))& HASH_BITS:移位運算使高位參與運算,儘可能分佈以便減少雜湊衝突
//這個int hash將作為key對應的結點Node中的成員變數hash使用
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K, V>[] tab = table;;) {
Node<K, V> f;
int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();//1.陣列桶初始化(延遲初始化hash桶,第一次put操作),並計算下一次rehash的閾值
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//i = (n -1) & hash:hash陣列桶的index,非常類似hashMap的key計算方法
//2.如果這個key對應的陣列f位置沒有元素,則CAS初始化這個f陣列元素(單向連結串列Node物件)
if (casTabAt(tab, i, null, new Node<K, V>(hash, key, value, null)))
break;
} else if ((fh = f.hash) == MOVED)//3.f結點已經轉換為ForwardingNode,表示有其他執行緒正在擴容
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) {//4.鎖住連結串列f(或者紅黑樹)
if (tabAt(tab, i) == f) {//再次判斷,如果失敗則釋放鎖
if (fh >= 0) {
binCount = 1;//記錄當前陣列桶中的連結串列Node個數.
//5.遍歷連結串列,新增或者覆蓋
for (Node<K, V> e = f;; ++binCount) {
K ek;
//5.1:查詢是否有重複的key,嘗試覆蓋(預設覆蓋)
if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) {//當前節點,key.hash&&key匹配
oldVal = e.val;//記錄原有value
if (!onlyIfAbsent)//是否允許覆蓋 預設允許
e.val = value;//覆蓋
break;
}
//5.2:連結串列末端上新增一個結點
Node<K, V> pred = e;
if ((e = e.next) == null) {//移動到下個結點,直到尾部
pred.next = new Node<K, V>(hash, key, value, null);//為null表示到達連結串列尾部,此時在尾部插入新的結點。否則繼續遍歷這個連結串列
break;
}
}
} else if (f instanceof TreeBin) {//6.紅黑樹則使用紅黑樹插入
Node<K, V> p;
binCount = 2;
if ((p = ((TreeBin<K, V>) f).putTreeVal(hash, key, value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//7.通過binCount判斷連結串列上結點個數,是否需要連結串列轉紅黑樹
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;//當同一個key覆蓋value的情況下,直接返回oldVal,無需執行後續計數程式碼
break;
}
}
}
addCount(1L, binCount);//8
return null;
}接著對put方法中用到的幾個方法做進一步解析:
initTable
/**
* 1.初始化陣列桶
* 2.確認下次擴容閾值(sizeCtl使用CAS設定)
*/
private final Node<K, V>[] initTable() {
Node<K, V>[] tab;
int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)//當sizeCtl<0表示當前物件正在初始化,嘗試yield cpu時間以避免不必要的競爭
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {// CAS設定為-1表示正在初始化
try {
if ((tab = table) == null || tab.length == 0) {//再次判斷
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;//設定初始陣列桶的size.預設陣列個數16
@SuppressWarnings("unchecked")
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n];// 陣列桶生成
table = tab = nt;
sc = n - (n >>> 2);//計算下一次擴容閾值,等價於sc=n*0.75
}
} finally {
sizeCtl = sc;// resize 閾值
}
break;
}
}
return tab;
}addCount
private final void addCount(long x, int check) {//put方法呼叫:x預設為1;binCount表示連結串列遍歷的當前個數
CounterCell[] as;
long b, s;
if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {//當前k\v元素總數,加1
CounterCell a;
long v;
int m;
boolean uncontended = true;//預設假設不存在競爭
if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null
|| !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {//下邊這段邏輯,會在數量達到閾值時做resize:
Node<K, V>[] tab, nt;
int n, sc;
//當前總數(+1後)>=閾值(sc) && table陣列不為null && 陣列個數不超標
while (s >= (long) (sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {//-1:表示初始化;-|n|表示n-1個執行緒正在執行resize.
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS
|| (nt = nextTable) == null || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
} else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))//將sizectl設定為一個很大的負數,然後進行transfer擴容,結束transfer後設置為下一次擴容的閾值
transfer(tab, null);//首次執行
s = sumCount();
}
}
}待續