
BI學習筆記之二- BI的體系架構與相關技術
BI的體系架構與相關技術
|
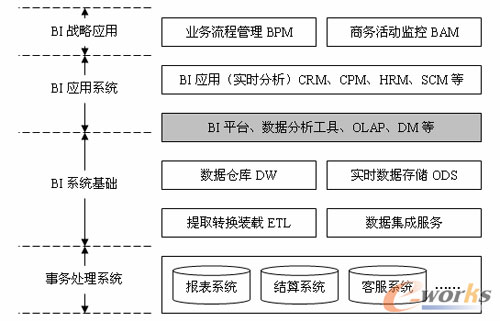
一個BI系統為了滿足企業管理者的要求,從浩如煙海的資料中找出其關心的資料,必須要做到以下幾步: 1)為了整合各種格式的資料,清除原有資料中的錯誤記錄——資料預處理的要求。 2)對預處理過資料,應該統一集中起來——元資料(Meta Data)、資料倉庫(Data Warehouse)的要求; 3)最後,對於集中起來的龐大的資料集,還應進行相應的專業統計,從中發掘出對企業決策有價值的新的機會——OLAP(聯機事務分析)和資料探勘(Data Mining)的要求。 所以,一個典型的BI體系架構應該包含這3步所涉及的相關要求。 |
|
| 圖 3 BI的體系架構 |
|
整個體系架構中包括:終端使用者查詢和報告工具、OLAP工具、 1)、終端使用者查詢和報告工具。 專門用來支援初級使用者的原始資料訪問,不包括適應於專業人士的成品報告生成工具。 2)、資料預處理(STL-資料抽取、轉換、裝載) 從許多來自不同的企業運作系統的資料中提取出有用的資料並進行清理,以保證資料的正確性,然後經過抽取(Extraction)、轉換(Transformation)和裝載(Load),即ETL過程,合併到一個企業級的資料倉庫裡,從而得到企業資料的一個全域性檢視。 3)、OLAP工具。 提供多維資料管理環境,其典型的應用是對商業問題的建模與商業資料分析。OLAP也被稱為多維分析。 4)、資料探勘(Data Mining)軟體。 使用諸如神經網路、規則歸納等技術,用來發現資料之間的關係,做出基於資料的推斷。 5)、資料倉庫(Data Warehouse)和資料集市(Data Mart)產品。 包括資料轉換、管理和存取等方面的預配置軟體,通常還包括一些業務模型,如財務分析模型。 6)、聯機分析處理 (OLAP) 。 OLAP是使分析人員、管理人員或執行人員能夠從多角度對資訊進行快速、一致、互動地存取,從而獲得對資料的更深入瞭解的一類軟體技術。 其中核心技術在於資料預處理、資料倉庫的建立(DW)、 資料預處理: 當早期大型的線上事務處理系統(OLTP)問世後不久,就出現了一種用於“抽取”處理的簡單程式,其作用是搜尋整個檔案和資料庫,使用某些標準選擇合乎要求的資料,將其複製拷貝出來,用於總體分析。因為這樣做不會影響正在使用的線上事務處理系統,降低其效能,同時,使用者可以自行控制抽取出來的資料。但是,現在情況發生了巨大的變化,企業同時採用了多個線上事務處理系統,而這些系統之間的資料定義格式不盡相同,即使採用同一軟體廠商提供的不同軟體產品,或者僅僅是產品版本不同,之間的資料定義格式也有少許差距。由此,我們必須先定義一個統一的資料格式,然後把各個來源的資料按新的統一的格式進行轉換,然後集中裝載入資料倉庫中。 其中,尤其要注意的一點時,並不是各個來源的不同格式的所有資料都能被新的統一格式包容,我們也不應強求非要把所有資料來源的資料全部集中起來。Why?原因很多。有可能原來錄入的資料中,少量的記錄使用了錯誤的資料,這類資料如果無法校正,應該被捨去。某些資料記錄是非結構化的,很難將其轉化成新定義的統一格式,而且從中抽取資訊必須讀取整個檔案,效率極低,如大容量的二進位制資料檔案,多媒體檔案等,這類資料如果對企業決策不大,可以捨去。 目前已有一部分軟體廠商開發出專門的ETL工具,其中包括: Ardent DataStage Evolutionary Technologies,Inc. (ETI) Extract Information Powermart Sagent Solution SAS Institute Oracle Warehouse Builder MSSQL Server2000 DTS 資料倉庫: 資料倉庫概念是由號稱“資料倉庫之父”William H.Inmon在上世紀80年代中期撰寫的《建立資料倉庫》一書中首次提出,“資料倉庫是一個面向主題的、整合的、非易失性的,隨時間變化的用來支援管理人員決策的資料集合”。 面向主題是資料倉庫第一個顯著特點,就是指在資料倉庫中,資料按照不同的主題進行組織,每一個主題中的資料都是從各操作資料庫中抽取出來彙集而成,這些與該主題相關的所有歷史資料就形成了相應的主題域。 資料倉庫的第二個顯著特點是整合。資料來源於不同的資料來源,通過相應的規則進行一致性轉換,最終整合為一體。 資料倉庫的第三個特點是非易失性。一旦資料被載入到資料倉庫中,資料的值不會再發生變化,儘管執行系統中對資料進行增、刪、改等操作,但對這些資料的操作將會作為新的快照記錄到資料倉庫中,從而不會影響到已經進入到資料倉庫的資料。 資料倉庫最後一個特點是它隨時間變化。資料倉庫中每一個數據都是在特定時間的記錄,每個記錄都有著相應的時間戳。 |
|
| 圖 4 資料倉庫體系架構 |
|
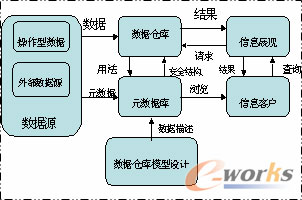
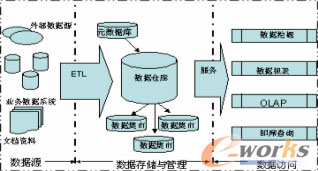
資料倉庫對外部資料來源和操作型資料來源的元資料,按照資料倉庫模式設計要求進行歸類,並建成元資料庫,相對應的資料經過ETL後加載到資料倉庫中;當資訊客戶需要查詢資料時先通過資訊展現系統瞭解元資料或者直接瀏覽元資料庫,再發起資料查詢請求得到所需資料。 一個典型的企業資料倉庫系統,通常包含資料來源、資料儲存與管理、資料的訪問三個部分。 |
|
| 圖 5 資料倉庫系統 |
|
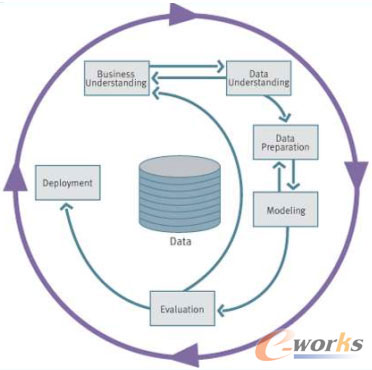
資料來源:是指企業操作型資料庫中的各種生產運營資料、辦公管理資料等內部資料和一些調查資料、市場資訊等來自外環境的資料總稱。這些資料是構建資料倉庫系統的基礎是整個系統的資料來源泉。 資料的儲存與管理:資料倉庫的儲存主要由元資料的儲存及資料的儲存兩部分組成。元資料是關於資料的資料,其內容主要包括資料倉庫的資料字典、資料的定義、資料的抽取規則、資料的轉換規則、資料載入頻率等資訊。各操作資料庫中的資料按照元資料庫中定義的規則,經過抽取、清理、轉換、整合,按照主題重新組織,依照相應的儲存結構進行儲存。也可以面向應用建立一些資料集市,資料集市可以看作是資料倉庫的一個子集,它含有較少的主題域且歷史時間更短資料量更少,一般只能為某個區域性範圍內的管理人員服務,因此也稱之為部門級資料倉庫。 資料的訪問:由OLAP(聯機分析處理)、資料探勘、統計報表、即席查詢等幾部分組成。例如OLAP:針對特定的分析主題,設計多種可能的觀察形式,設計相應的分析主題結構(即進行事實表和維表的設計),使管理決策人員在多維資料模型的基礎上進行快速、穩定和互動性的訪問,並進行各種複雜的分析和預測工作。按照儲存方式來分,OLAP可以分成MOLAP以及ROLAP等方式,MOLAP (Multi-Dimension OLAP)將OLAP分析所需的資料存放在多維資料庫中。分析主題的資料可以形成一個或多個多維立方體。ROLAP (Relational OLAP)將OLAP分析所需的資料存放在關係型資料庫中。分析主題的資料以“事實表-維表”的星型模式組織。 資料探勘: 資料探勘的定義非常模糊,對它的定義取決於定義者的觀點和背景。如下是一些DM文獻中的定義: 資料探勘是一個確定資料中有效的,新的,可能有用的並且最終能被理解的模式的重要過程。 資料探勘是一個從大型資料庫中提取以前未知的,可理解的,可執行的資訊並用它來進行關鍵的商業決策的過程。 資料探勘是用在知識發現過程,來辯識存在於資料中的未知關係和模式的一些方法。資料探勘是發現數據中有益模式的過程。 資料探勘是我們為那些未知的資訊模式而研究大型資料集的一個決策支援過程。 雖然資料探勘的這些定義有點不可觸控,但在目前它已經成為一種商業事業。如同在過去的歷次淘金熱中一樣,目標是`開發礦工`。利潤最大的是賣工具給礦工,而不是幹實際的開發。 目前業內已有很多成熟的資料探勘方法論,為實際應用提供了理想的指導模型。其中,標準化的主要有三個:CRISP-DM;PMML;OLE DB for DM。 CRISP-DM(Cross-Industry Standard Process for Data Mining)是目前公認的、較有影響的方法論之一。CRISP-DM強調,DM不單是資料的組織或者呈現,也不僅是資料分析和統計建模,而是一個從理解業務需求、尋求解決方案到接受實踐檢驗的完整過程。CRISP-DM將整個挖掘過程分為以下六個階段:商業理解(Business Understanding),資料理解(Data Understanding),資料準備(Data Preparation),建模(Modeling),評估(Evaluation)和釋出(Deployment)。其框架圖如下: |
|
| 圖 6 CRISP-DM模型框架圖 |
|
從技術層來看,資料探勘技術可分為描述型資料探勘和預測型資料探勘兩種。描述型資料探勘包括資料總結、聚類及關聯分析等。預測型資料探勘包括分類、迴歸及時間序列分析等。 1、資料總結:繼承於資料分析中的統計分析。資料總結目的是對資料進行濃縮,給出它的緊湊描述。傳統統計方法如求和值、平均值、方差值等都是有效方法。另外還可以用直方圖、餅狀圖等圖形方式表示這些值。廣義上講,多維分析也可以歸入這一類。 2、聚類:是把整個資料庫分成不同的群組。它的目的是使群與群之間差別很明顯,而同一個群之間的資料儘量相似。這種方法通常用於客戶細分。在開始細分之前不知道要把使用者分成幾類,因此通過聚類分析可以找出客戶特性相似的群體,如客戶消費特性相似或年齡特性相似等。在此基礎上可以制定一些針對不同客戶群體的營銷方案。 3、關聯分析:是尋找資料庫中值的相關性。兩種常用的技術是關聯規則和序列模式。關聯規則是尋找在同一個事件中出現的不同項的相關性;序列模式與此類似,尋找的是事件之間時間上的相關性,如對股票漲跌的分析等。 4、分類:目的是構造一個分類函式或分類模型(也常常稱作分類器),該模型能把資料庫中的資料項對映到給定類別中的某一個。要構造分類器,需要有一個訓練樣本資料集作為輸入。訓練集由一組資料庫記錄或元組構成,每個元組是一個由有關欄位(又稱屬性或特徵)值組成的特徵向量,此外,訓練樣本還有一個類別標記。一個具體樣本的形式可表示為:( v1, v2, ...,vn;c ),其中vi表示欄位值,c表示類別。 5、迴歸:是通過具有已知值的變數來預測其它變數的值。一般情況下,迴歸採用的是線性迴歸、非線性迴歸這樣的標準統計技術。一般同一個模型既可用於迴歸也可用於分類。常見的演算法有邏輯迴歸、決策樹、神經網路等。 6、時間序列:時間序列是用變數過去的值來預測未來的值。資料探勘(Data Mining)軟體。使用諸如神經網路、規則歸納等技術,用來發現資料之間的關係,做出基於資料的推斷。 |
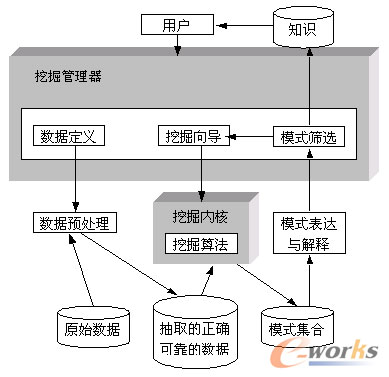
|
| 圖 7 資料探勘系統 |
|
以下是一些當前的資料探勘產品: IBM: Intelligent Miner 智慧礦工 Tandem: Relational Data Miner 關係資料礦工 AngossSoftware: KnowledgeSEEDER 知識搜尋者 Thinking Machines Corporation: DarwinTM NeoVista Software: ASIC ISL Decision Systems,Inc.: Clementine DataMind Corporation: DataMind Data Cruncher Silicon Graphics: MineSet California Scientific Software: BrainMaker WizSoft Corporation: WizWhy Lockheed Corporation: Recon SAS Corporation: SAS Enterprise Miner
聯機分析處理(OLAP):
OLAP有多種實現方法,根據儲存資料的方式不同可以分為ROLAP、MOLAP、HOLAP。
原文地址:http://www.e-works.net.cn/ztbd/bi/bi02.htm |