基於大資料的房價分析--1.資料爬取
阿新 • • 發佈:2019-02-03
爬取資料用的是python2.6+scrapy爬蟲框架,一開始我寫的是一個全站爬蟲,可以根據一個種子url爬取58同城所有房價資訊,但有個問題就是必須使用代理IP,否則爬蟲很快就會被封禁,於是我想了個辦法就是在linux中每五分鐘執行一次爬蟲程式,每次只爬取一個城市的房價資訊,程式碼如下
1.spiders
#encoding=utf-8
import sys
sys.path.append("..")
from scrapy.spiders import Spider
from lxml import html
import plug
from plug.utils import 2.items
class HouseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
roomNum = scrapy.Field()
size = scrapy.Field()
orient = scrapy.Field()
floor = scrapy.Field()
address = scrapy.Field()
sumPrice = scrapy.Field()
unitPrice = scrapy.Field()
_id = scrapy.Field()
imageurl = scrapy.Field()
fromUrl = scrapy.Field()
city = scrapy.Field()
nowTime = scrapy.Field()
status = scrapy.Field()3.pipelines
#coding: utf-8
import codecs
import json
import pymongo
from scrapy.utils.project import get_project_settings
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
from ershoufang.items import ProxyItem
class ErshoufangPipeline(object):
def __init__(self):
self.settings = get_project_settings()
self.client = pymongo.MongoClient(
host=self.settings['MONGO_IP'],
port=self.settings['MONGO_PORT'])
self.db = self.client[self.settings['MONGO_DB']]
self.proxyclient = self.proxy = self.client[self.settings['PROXY_DB']][self.settings['POOL_NAME']]
self.itemNumber = 0
def process_proxy(self,item):
self.proxyclient.insert(dict(item))
def process_item(self, item, spider):
if isinstance (item,ProxyItem):
self.process_proxy(item)
return item
try:
if not item['address']:
print(item["fromUrl"+"網頁異常"])
return item
'''
if self.db.ershoufang.count({"_id":item["_id"],"city":item['city']})<= 0:
print("刪除")
self.db.ershoufang.remove({"_id":item["_id"]})
'''
coll = self.db[self.settings['ALL']]
coll.insert(dict(item))
self.itemNumber += 1
print("爬取到第%s個房屋,地址為%s"%(self.itemNumber,item['address']))
except Exception,e:
print("房屋已存在"+item['address'])
return item
def closed_spider(self,spider):
self.client.close()
self.db.close()
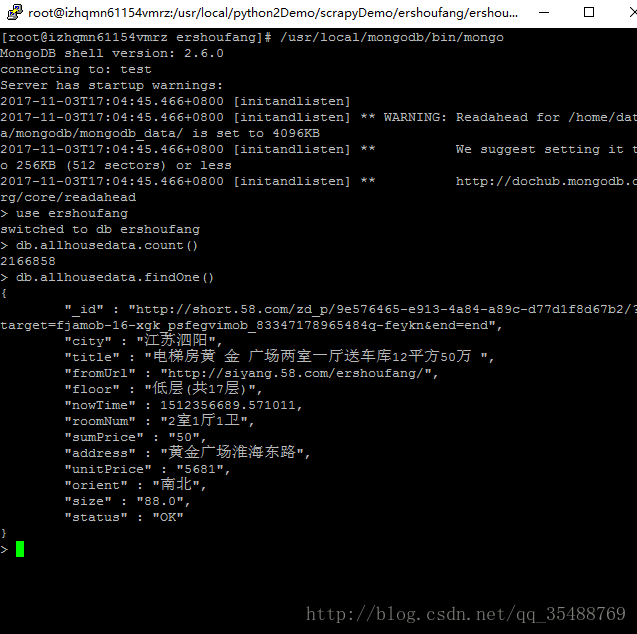
print("本次爬取共爬取到%s條房屋資料"%self.itemNumber)爬取了三天,爬取了兩百多萬的資料,結果如下