基於大資料的房價分析
阿新 • • 發佈:2019-01-26
大二自學的是python和java,大三卻找了個和前端相關的實習工作,好在不是很忙,工作之餘做一些自己以前想做懶得做的東西,複習一下python和java,也能增強自己的工作技能,第一個專案就是基於房價的大資料分析
1.前置準備
1.工具
使用的是python2.7下的scrapy爬蟲框架,用到的包還有lxml,BeautifulSoup,requests等等
2.爬取目標
目前網路上釋出房屋買賣資訊的網站不少,我選擇了資訊量比較大的五八同城網站,當然,由於是比較大的網站,反扒的措施自然也不會少,爬取的資訊主要有,房屋地址,房屋大小,房間數量,房屋朝向,房屋層數,每平米售價,總售價,詳情頁面等等
3.後端
使用mongodb儲存房屋資料,使用百度地圖API將地址資訊解析為座標資訊,使用springmvc框架搭建專案,使用阿里雲伺服器釋出專案
4.前端
使用echarts圖表工具進行資料視覺化.jquery進行元素選擇
2.結果
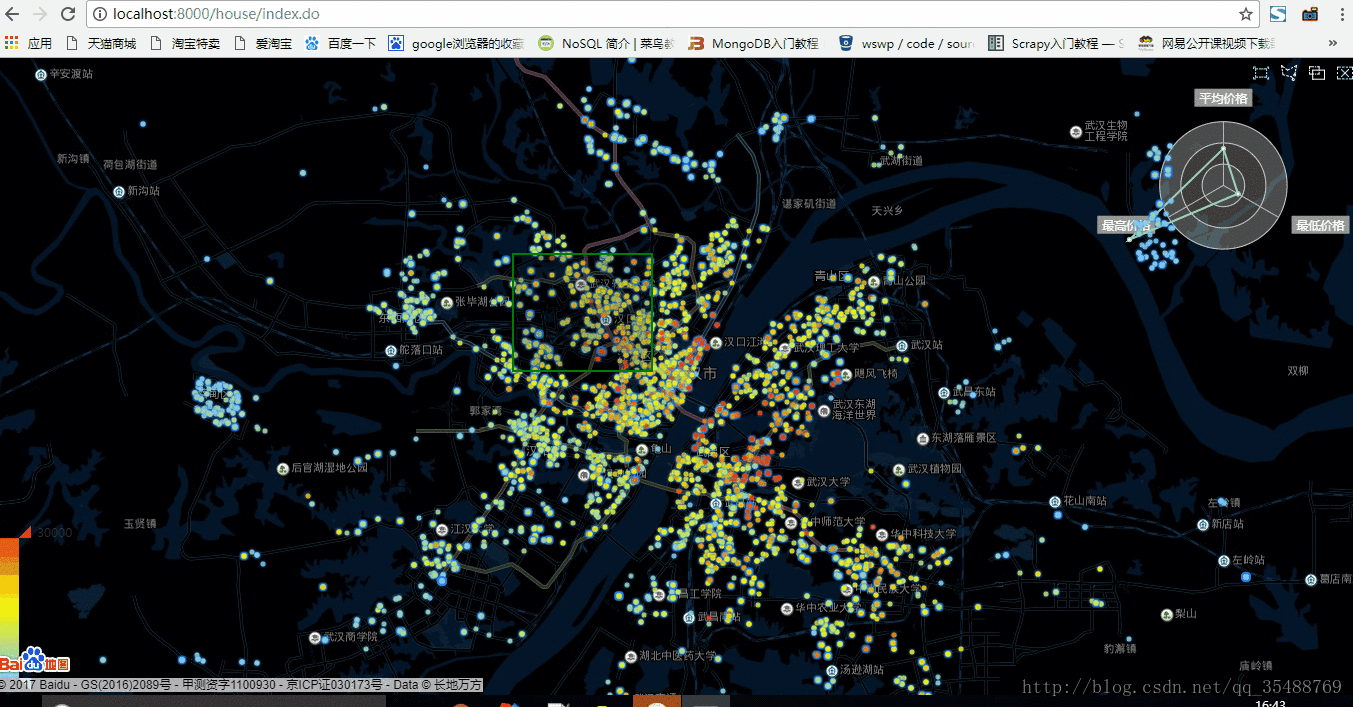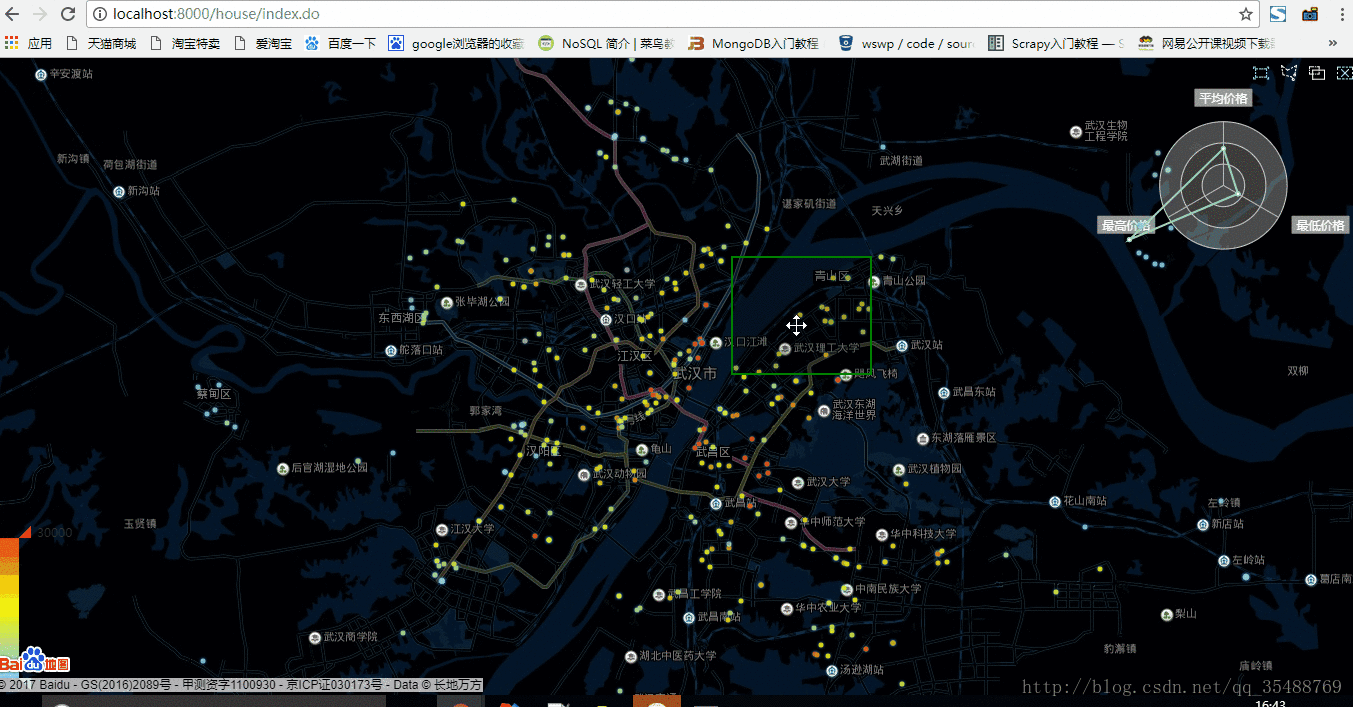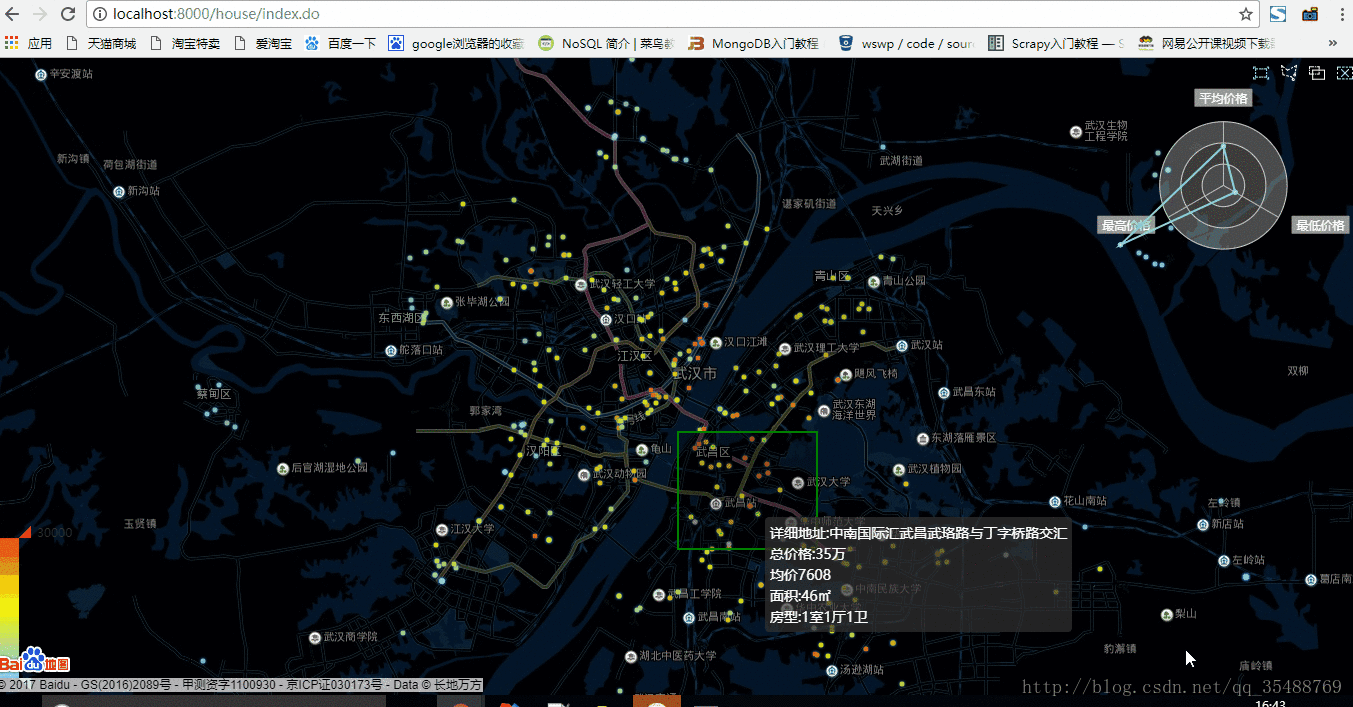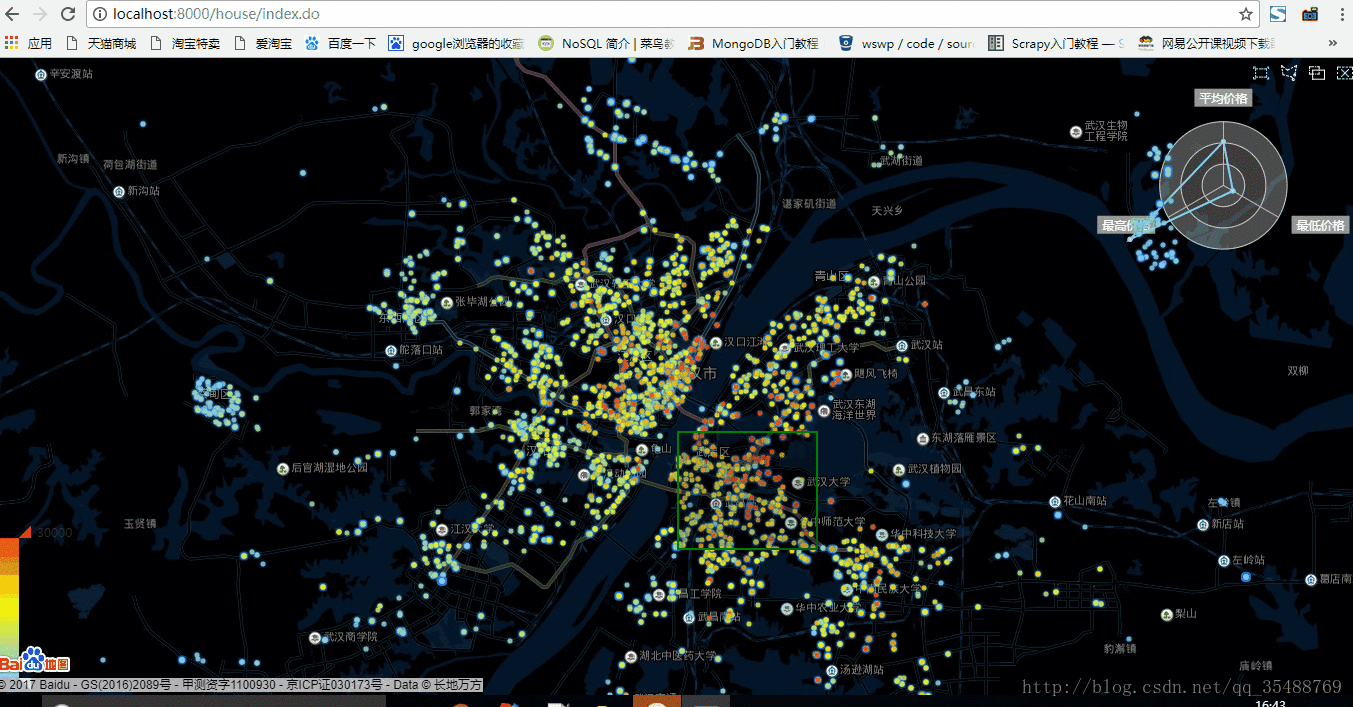
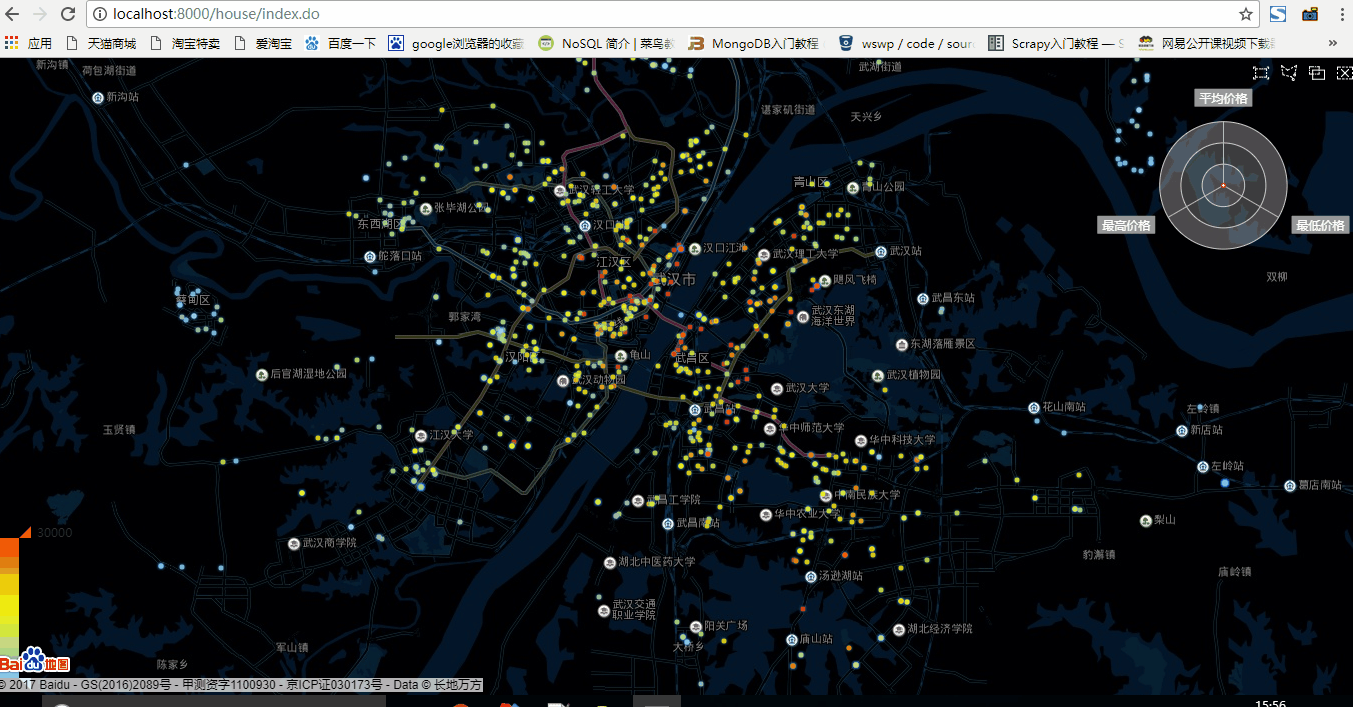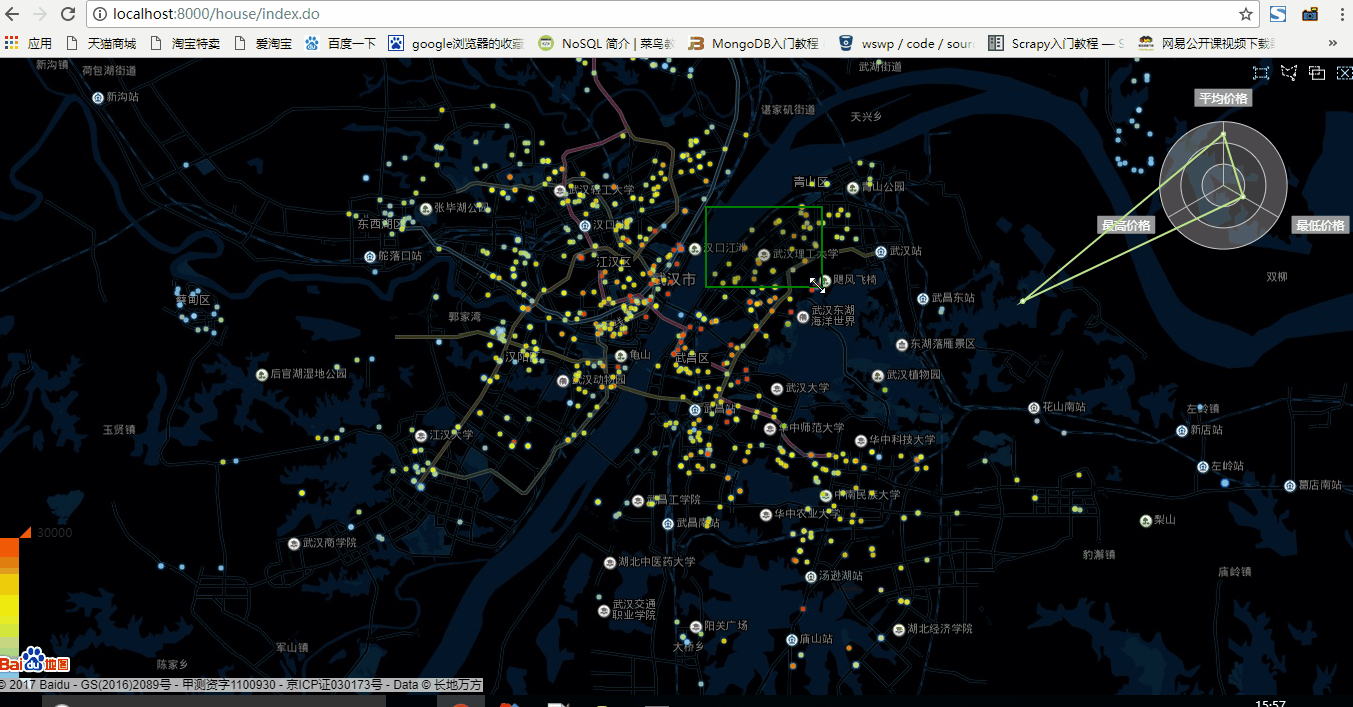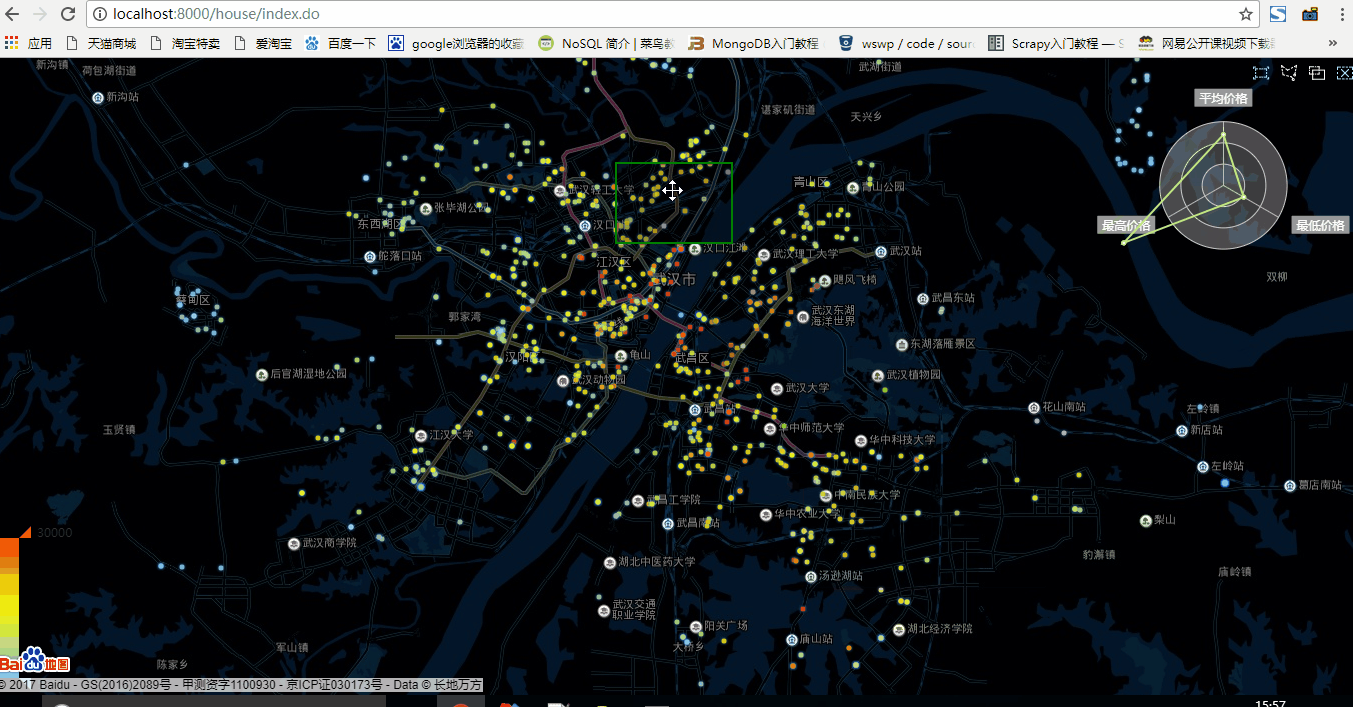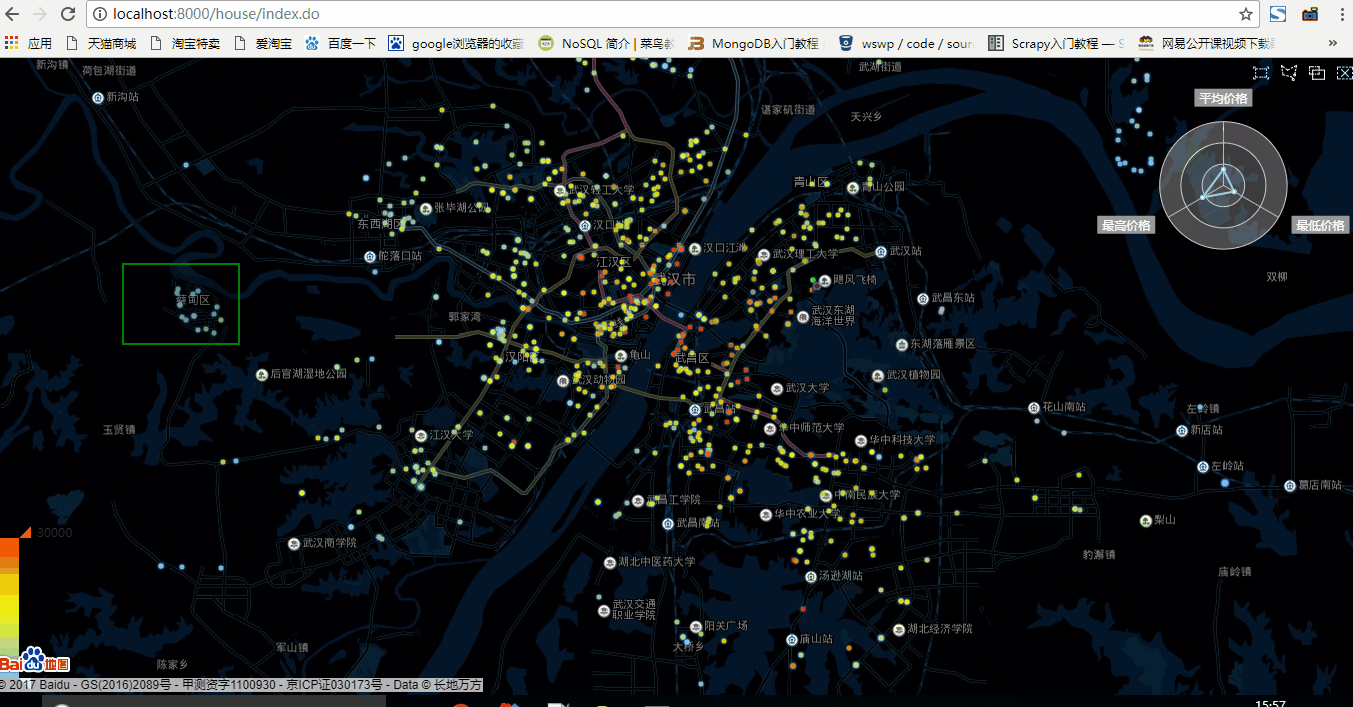
發現echarts的散點圖型別在資料量比較大的時候會非常卡,用武漢市舉例子如下
1.五百資料量狀態
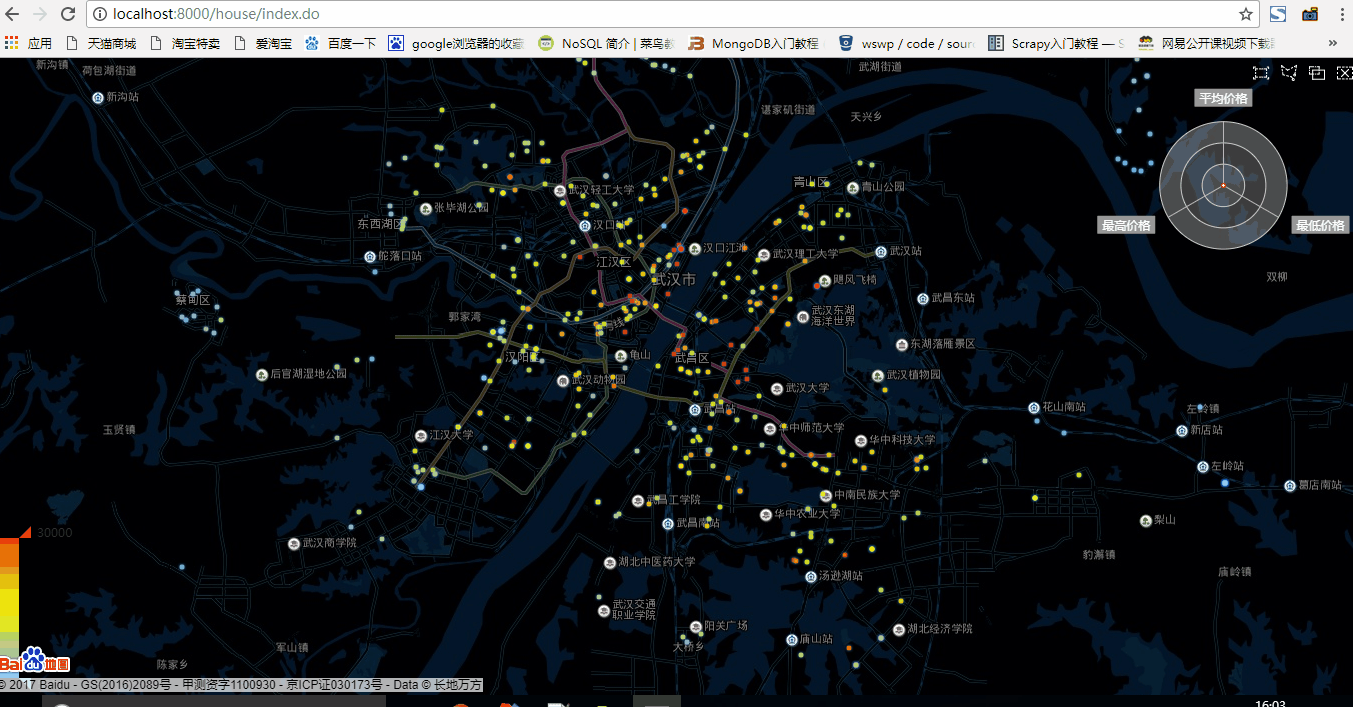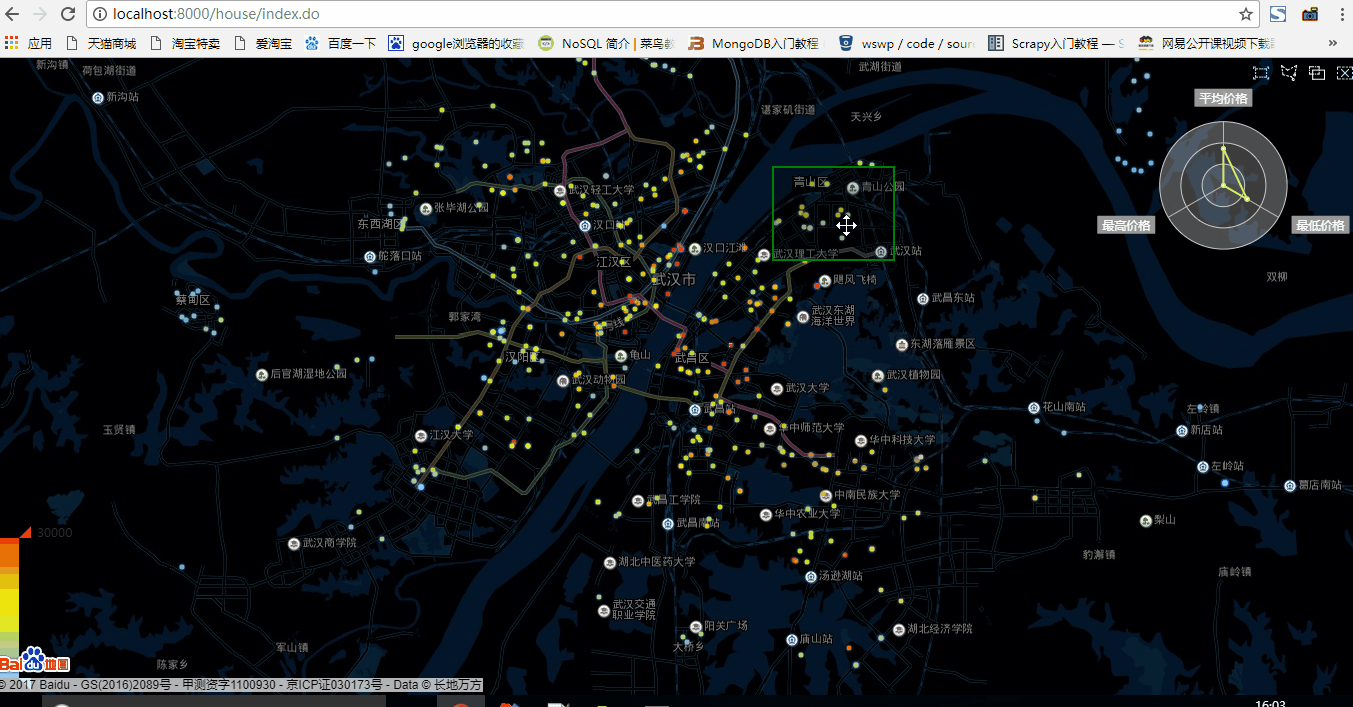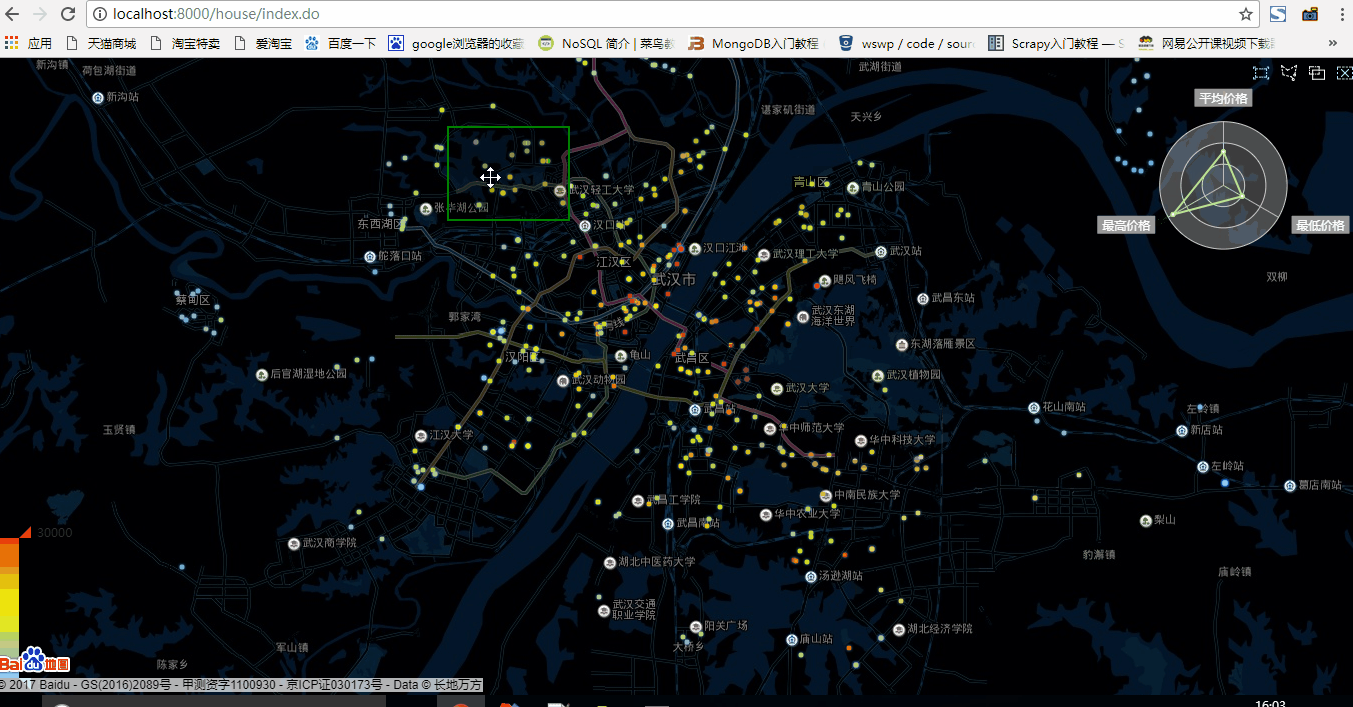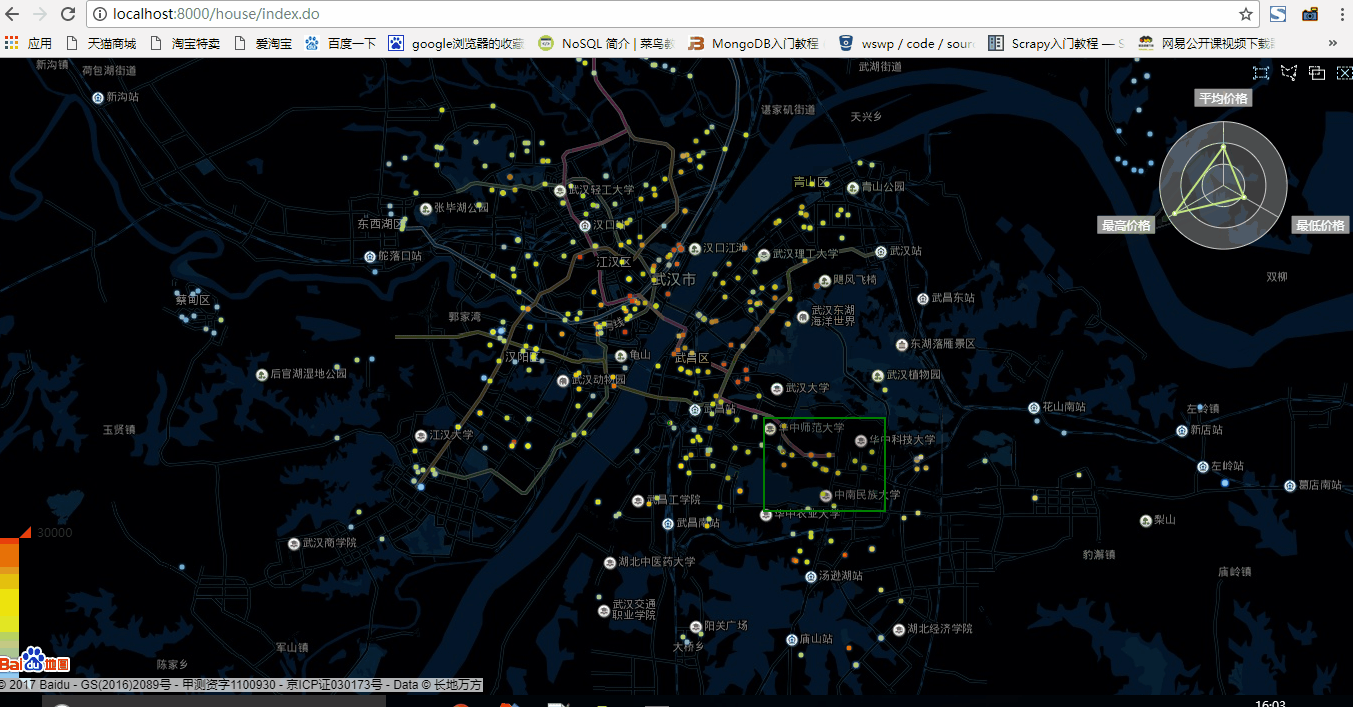
可以看出,在五百資料量的狀態下,資料重新整理非常快,用於顯示區域內房價總體資訊雷達圖也重新整理的很快
2.一千資料量狀態
在一千資料量狀態下略微有些卡頓