
Python小專案四:實現簡單的web伺服器
本部落格是整理在學習實驗樓的課程過程中記錄下的筆記形成的,參考:https://www.shiyanlou.com/courses/552。不同之處在於實驗樓使用python2.7,而博主這裡使用的是python3.6。在學習中也因為python版本不同遇到了一些坑,這裡寫成部落格一作記錄,二來可以幫助像博主這樣的入門者少踩一些坑。
要想實現web伺服器,首先要明白web伺服器應該具備怎樣的功能:比如說瀏覽器傳送了http請求(GET或POST),伺服器要首先接收客戶端傳送的TCP請求,與之建立連結,然後接收http請求,解析並響應。 之後就是客戶端的事情了,客戶端接受響應並解析,顯示,之後伺服器斷開連結。
為了能很好地理解上面這個過程,我分別查詢了以下概念:
1. HTTP協議
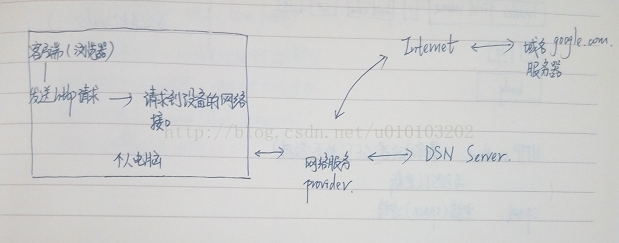
對於 http://www.google.com 這個網址,我們叫url,而http則是服務於url的協議。另外,url和ip地址兩者的一一對應是通過DNS(域名解析系統)來完成的。
瀏覽器的頁面中包含CSS,html,JavaScript,視訊檔案、圖片檔案等等。我的理解就是html協議規定了網頁元素的表達,一個html檔案可以視為用程式語言寫出來的網頁內容。而html本身也指這個規定本身。
而網際網路的概念是:所有裝置都提供獨特的標籤(總稱網際網路協議地址或IP地址),有網際網路服務供應商(ISP)提供的公網IP地址,通過這些地址,可以進行通訊。
如下圖:
2. web伺服器的基本概念,包括連結建立後的傳輸過程
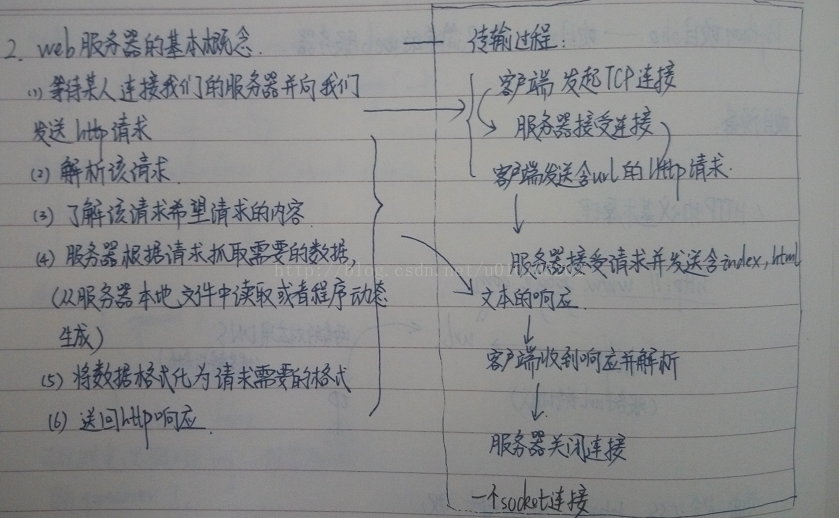
這時候,我們對整個過程有了大致的瞭解,要對其進行實現我們需要做瑞星啊幾件事:
* 接受TCP請求可使用http.server庫來自動完成(注意,python3使用這個庫,但是實驗樓裡用python2.7用的是另一個庫)。
虛擬碼如下:
from http.server import HTTPServer, 某個handler類
httpd = HTTPServer( url地址, handler類)其中HTTPServer作用是建立並監聽HTTP socket,解析請求給handler類。url地址即伺服器url,handler類在http.server中有三種,這裡用BaseHTTPRequestHandler,該類本身不能響應任何實際的HTTP請求,因此需要定義子類來處理每個請求方法(GET/POST),實際上就是空的handler類,允許使用者自定義處理方法。
在本次實驗中值處理GET請求——相應的在子類中定義(給出)do_GET()函式即可。
上面內容中也提到了socket,為了更好地理解我也查詢了相關內容。注意python中的大部分網路程式設計模組都隱藏了socket模組的細節,不直接和套接字互動。所以這裡我們只需要理解即可,具體程式設計不需要考慮其中內容。
socket套接字是做什麼用的?-->兩個端點的程式之間的“資訊通道”。即計算機1中的程式與計算機2中的程式通過socket傳送資訊。套接字是一個類,一個套接字是socket模組中的socket類中的一個例項。一個套接字處理一次通訊(伺服器和客戶機),各自進行設定,對應有不同的方法,比如說,s.connect就是客戶機,s.listen(5)就是伺服器。
連線方式在於一個connect(),一個listen(),使用accept()方法來完成。(accept()是伺服器端開始監聽後,可以接受客戶端的連線。)accept返回(client,address)元祖,client是客戶端套接字,而address是地址。處理完與該客戶端的連線後,再次呼叫accept方法開始等待下一個連線。
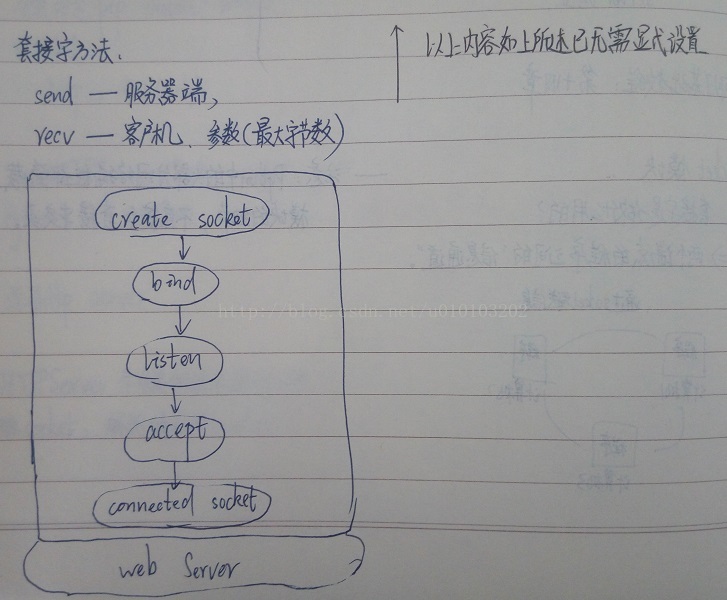
總結來說,在這個實驗裡,我們要實現的功能只是根據使用者的請求,生成http響應。所以我們也應該知道http請求和響應的格式:

--------------------------------------------------------------------------------------------------------------------------------------------------------------
一. 實現靜態頁面
接下來按照我實驗時的步驟來分別記錄。
步驟1. 首先建立一個簡單web伺服器, 能夠響應靜態頁面
首先在主函式中,固定的使用以下語句即可:
if __name__ == '__main__':
httpAddress = ('', 8030)
httpd = hs.HTTPServer(httpAddress, RequestHandler)
httpd.serve_forever()這裡url地址空缺則代表本機地址127.0.0.1,埠可以改動(有些埠系統佔用著)。
所以為了讓上述程式碼執行起來,我們的主要內容在於實現RequestHandler。
之前提到過,使用BaseHTTPRequestHandler,則需要定義一個子類,並在子類中給出do_GET(),頁面設計等內容。如下程式碼所示,我們在該類中給出依照http響應的格式寫出的內容,再在do_GET()函式中將該內容作為響應返回。相當於我們在RequestHandler類中給出了http的響應。
class RequestHandler(hs.BaseHTTPRequestHandler):
def send_content(self, page, status = 200):
self.send_response(status)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(page)))
self.end_headers()
self.wfile.write(bytes(page, encoding = 'utf-8'))
#print(page)
def do_GET(self):
獲取路徑,
執行操作(send_content)因此接下來我們要寫do_GET()的具體邏輯和程式碼,假設靜態頁面存在了plain.html中,那麼合理的url是127.0.0.1:8030/plain.html,而其對於他的請求伺服器是不能做出反應的。所以do_GET()的重點在於判斷輸入合理與否:我們將輸入分為三種情況:路徑不存在、路徑不是一個檔案、路徑是一個檔案。
def do_GET(self):
#這裡要處理兩個異常,一個是讀入路徑時可能出現的異常,一個是讀入路徑後若不是檔案,要作為異常處理
try:
#獲取檔案路徑
full_path = os.getcwd() + self.path
# 如果路徑不存在
if not os.path.exists(full_path):
raise ServerException("'{0}' not found".format(self.path))
#如果該路徑是一個檔案
elif os.path.isfile(full_path):
self.handle_file(full_path)
#如果該路徑不是一個檔案
else:
raise ServerException("Unknown object '{0}'".format(self.path))
except Exception as msg:
self.handle_error(msg)class ServerException(Exception):
'''伺服器內部錯誤'''
pass/* 這裡
"Unknown object '{0}'".format(self.path)用到了字串的format方法,format是格式化輸出的方法,即最終顯示的是format括號內的內容代替{0}中的內容後的字串內容。當然format的用法還有更為複雜的形式,如後面會見到的“”.format(**字典),這個語句中有另外一個知識點,**dict。**dict作為函式的引數時,是用鍵值對應函式中的引數名,而用值作為函式的輸入值。而在字串.format中,用字典的鍵匹配字串中{}裡的內容,而用值去依次替換,如
d = {'x':1, 'y':2}
str = “Pages show {x} and {y}”
print(str.format(**d))
#將顯示Pages show 1 and 2有關檔案路徑:
#獲取檔案路徑 fullpath = os.getcwd() + self.path (+號前得到當前路徑,後面是得到handler得到的路徑,如/plain.html
#判斷路徑是否存在 os.path.exist(fullpath)
#判斷路徑是否是檔案 os.path.isfile(fullpath)
處理並顯示內容
#從檔案中得到內容 content = file.read() (注意content此處需要字串,所以open('r')以r方式而非rb,rb讀入是byte型別。
/* 這裡需要說明下,python3.6對於字串還是byte有明確區分,所以讀入時要用'r' 還是‘rb’要注意。之前有關python專案中也提到過這個問題。*/
以上內容都瞭解後,我們就可以實現出一個響應靜態頁面的伺服器,當然,你需要有plain.html檔案放在和你python程式碼的相同目錄下。你可以在https://drive.google.com/file/d/0By68FgZpORkFOWZKS1dzeHpfTlk/view?usp=sharing下載得到。
下載httpserver_plain.py檔案和plain.html檔案即可測試以上介紹的內容。(csdn上傳以後不能刪除不能修改,這裡必須瘋狂吐槽)
/* 如何測試?
你可以用cmd開啟終端,執行以上python程式碼(命令為python httpserver_plain.html),之後在瀏覽器中輸入127.0.0.1:你設定的埠號/plain.html.檢視效果。
或者pip安裝httpie,終端輸入http 127.0.0.1:你設定的埠號/plain.html來檢視呼叫效果。
*/
示意程式碼如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 23 08:13:43 2017
@author: dc
"""
import http.server as hs
import sys, os
class ServerException(Exception):
'''伺服器內部錯誤'''
pass
class RequestHandler(hs.BaseHTTPRequestHandler):
def send_content(self, page, status = 200):
self.send_response(status)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(page)))
self.end_headers()
self.wfile.write(bytes(page, encoding = 'utf-8'))
#print(page)
def do_GET(self):
#這裡要處理兩個異常,一個是讀入路徑時可能出現的異常,一個是讀入路徑後若不是檔案,要作為異常處理
try:
#獲取檔案路徑
full_path = os.getcwd() + self.path
# 如果路徑不存在
if not os.path.exists(full_path):
raise ServerException("'{0}' not found".format(self.path))
#如果該路徑是一個檔案
elif os.path.isfile(full_path):
self.handle_file(full_path)
#如果該路徑不是一個檔案
else:
raise ServerException("Unknown object '{0}'".format(self.path))
except Exception as msg:
self.handle_error(msg)
def handle_file(self, full_path):
try:
with open(full_path, 'r') as file:
content = file.read()
self.send_content(content,200)
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(self.path, msg)
self.handle_error(msg)
Error_Page = """\
<html>
<body>
<h1>Error accessing {path}</h1>
<p>{msg}</p>
</body>
</html>
"""
def handle_error(self, msg):
content = self.Error_Page.format(path= self.path,msg= msg)
self.send_content(content, 404)
if __name__ == '__main__':
httpAddress = ('', 8030)
httpd = hs.HTTPServer(httpAddress, RequestHandler)
httpd.serve_forever()-------------------------------------------------------------------------------------------------------------------
二. 當可以響應靜態頁面之後,我們接著實現CGI協議與指令碼。
某些請求可以用另外編寫指令碼來處理(給出響應),這樣對於新增的一些請求,就不用每次都修改伺服器指令碼了。為了更好地理解CGI,我們需要知道以下基本概念。

與之前實現靜態頁面相對比,這裡實現cgi指令碼有何不同?
--> 我們在訪問靜態頁面時,輸入127.0.0.1:8030/plain.html,伺服器會為我們返回plain.html檔案的內容;而cgi指令碼我們訪問的是一個指令碼,即127.0.0.1:8030/time.py,返回的是執行外部命令並獲得的輸出。
1. 第一個內容就是如何實現執行外部命令獲得該輸出
我們使用subprocess庫,具體程式碼是:
subprocess.check_output(['cmd', 'arg1', 'arg2'])
本例中為data = subprocess.check_output(['python', fullpath])可用字串方法endswith()判斷是否以".py"結尾。(該方法以".py"作為引數,輸出bool值)
當實現了以上兩個功能後,我們只需在類似靜態頁面的實現那樣填補程式碼邏輯即可,示意程式碼如下:
# -*- coding: utf-8 -*-
"""
Created on Sun Jun 25 03:38:11 2017
@author: dc
"""
import http.server as hs
import sys, os
import subprocess
class ServerException(Exception):
'''伺服器內部錯誤'''
pass
# 如果路徑不存在
class case_no_path(object):
'''如果路徑不存在'''
def test(self, handler):
return not os.path.exists(handler.full_path)
def act(self, handler):
raise ServerException("{0} not found".format(handler.path))
#所有情況都不符合時的預設處理類
class case_allother_fail(object):
'''所有情況都不符合時的預設處理類'''
def test(self, handler):
return True
def act(self, handler):
raise ServerException("Unknown object {0}".format(handler.full_path))
class case_is_file(object):
''' 輸入的路徑是一個檔案'''
def test(self, handler):
return os.path.isfile(handler.full_path)
def act(self, handler):
handler.handle_file(handler.full_path)
class case_CGI_file(object):
def test(self, handler):
print(os.path.isfile(handler.full_path) and handler.full_path.endswith('.py'))
return os.path.isfile(handler.full_path) and \
handler.full_path.endswith('.py')
def act(self, handler):
handler.run_cgi(handler.full_path)
class case_index_file(object):
'''輸入跟url時顯示index.html'''
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
#判斷目標路徑是否是目錄,且需要判斷目錄下是否包含index.html
def test(self, handler):
return os.path.isdir(handler.full_path) and \
os.path.isfile(self.index_path(handler))
def act(self, handler):
handler.handle_file(self.index_path(handler))
class RequestHandler(hs.BaseHTTPRequestHandler):
'''
請求路徑合法則返回相應處理,
否則返回錯誤頁面
'''
full_path = ""
#一定要注意條件類的優先順序不同,對於檔案的捕捉能力也不同,越是針對某種特例的條件類,
#越應該放在前面。
cases = [case_no_path(),
case_CGI_file(),
case_is_file(),
case_index_file(),
case_allother_fail()]
def run_cgi(self, fullpath):
#執行cgi指令碼並得到格式化的輸出,從而可以顯示到瀏覽器上
data = subprocess.check_output(["python", fullpath])
#self.wfile.write(bytes(fullpath, encoding = 'utf-8'))
self.send_content(page = str(data, encoding = 'utf-8'))
def send_content(self, page, status = 200):
self.send_response(status)
self.send_header("Content-type", "text/html")
self.send_header("Content-Length", str(len(page)))
self.end_headers()
self.wfile.write(bytes(page, encoding = 'utf-8'))
#print(page)
def do_GET(self):
#這裡要處理兩個異常,一個是讀入路徑時可能出現的異常,一個是讀入路徑後若不是檔案,要作為異常處理
try:
#獲取檔案路徑
self.full_path = os.getcwd() + self.path
# 如果路徑不存在
for case in self.cases:
if case.test(self):
case.act(self)
break
except Exception as msg:
self.handle_error(msg)
def handle_file(self, full_path):
try:
with open(full_path, 'r') as file:
content = file.read()
self.send_content(content,200)
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(self.path, msg)
self.handle_error(msg)
Error_Page = """\
<html>
<body>
<h1>Error accessing {path}</h1>
<p>{msg}</p>
</body>
</html>
"""
def handle_error(self, msg):
content = self.Error_Page.format(path= self.path,msg= msg)
self.send_content(content, 404)
if __name__ == '__main__':
httpAddress = ('', 8090)
httpd = hs.HTTPServer(httpAddress, RequestHandler)
httpd.serve_forever()注意到主要的區別在於我們在RequestHandler類中實現了run_cgi(self, fullpath),用來從外部執行請求的指令碼內容(如這裡的time.py);而條件中我們也加入了字尾的判斷。
整個程式碼執行效果是,當我們在終端輸入http 127.0.0.1:埠號/time.py,則伺服器會執行time.py的結果作為響應返回。該程式碼同樣包含在上述下載連結內,包含httpserver_CGI.py和time.py。
-----------------------------------------------------------------------------------------------------------------------------------------
三. 程式碼整理和重構
3.1 條件類
從上述plain和cgi的兩個示意程式碼中,大家可能已經發現:在對不同條件的判斷中,兩個程式碼分別使用了if-elif-else語句形式和條件類的形式。其中前者理解很容易,而後者條件類是指將條件放置在不同的類中,然後迴圈遍歷這些類,看哪個符合則對應執行相應條件。這樣處理的好處在於易於維護:對於新加入的條件,不對改動if-elif-else使其變得臃腫,而只需增加一個類作為條件,同時在handler中迴圈遍歷即可。
如我們要增加一個功能:在輸入127.0.0.1:埠號時,我們希望得到主頁的顯示(存為index.html),這時我們就新建一個條件類:
class case_index_file(object):
'''輸入跟url時顯示index.html'''
def index_path(self, handler):
return os.path.join(handler.full_path, 'index.html')
#判斷目標路徑是否是目錄,且需要判斷目錄下是否包含index.html
def test(self, handler):
return os.path.isdir(handler.full_path) and \
os.path.isfile(self.index_path(handler))
def act(self, handler):
handler.handle_file(self.index_path(handler))class RequestHandler(hs.BaseHTTPRequestHandler):
'''
請求路徑合法則返回相應處理,
否則返回錯誤頁面
'''
full_path = ""
cases = [case_no_path(),
case_index_file(),
case_is_file(),
case_allother_fail()] def do_GET(self):
#這裡要處理兩個異常,一個是讀入路徑時可能出現的異常,一個是讀入路徑後若不是檔案,要作為異常處理
try:
#獲取檔案路徑
self.full_path = os.getcwd() + self.path
# 如果路徑不存在
for case in self.cases:
if case.test(self):
case.act(self)
break
except Exception as msg:
self.handle_error(msg)
3.2 程式碼重構
這裡的重構主要針對每個條件類中重複過的程式碼,我們可以通過構建基類,然後生成條件類時作為基類的子類生成即可,從而更好地維護程式碼。具體實現如下:
class base_case(object):
'''定義基類,用來處理不同的條件類,條件類繼承該基類'''
def handle_file(self, handler, full_path):
try:
with open(full_path, 'r') as file:
content = file.read()
handler.send_content(content,200)
except IOError as msg:
msg = "'{0}' cannot be read: {1}".format(self.path, msg)
handler.handle_error(msg)
def test(self, handler):
assert False, "Not implemented."
def act(self, handler):
assert False, "Not implemented."# 如果路徑不存在
class case_no_path(base_case):
'''如果路徑不存在'''
def test(self, handler):
return not os.path.exists(handler.full_path)
def act(self, handler):
raise ServerException("{0} not found".format(handler.path))----------------------------------------------------------------------------------------------------------
以上就是我做實驗樓實驗的整個筆記,從一開始BaseHTTPServer模組import出錯,找python3中的對應模組,到學習新模組,依次完成實驗內容,中間有一些py2、3的不同的小坑,但是學完之後還是有不少收穫。
這裡我在將學到的內容總結一下:
1.http協議
對於 http://www.google.com 這個網址,我們叫url,而http則是服務於url的協議。另外,url和ip地址兩者的一一對應是通過DNS(域名解析系統)來完成的。
瀏覽器的頁面中包含CSS,html,JavaScript,視訊檔案、圖片檔案等等。我的理解就是html協議規定了網頁元素的表達,一個html檔案可以視為用程式語言寫出來的網頁內容。而html本身也指這個規定本身。
而網際網路的概念是:所有裝置都提供獨特的標籤(總稱網際網路協議地址或IP地址),有網際網路服務供應商(ISP)提供的公網IP地址,通過這些地址,可以進行通訊。
如下圖:
2. web伺服器的基本概念,包括連結建立後的傳輸過程

4.http響應格式
5. httpie庫
可以使用httpie庫代替瀏覽器傳送請求
安裝命令是 pip install httpie,
使用命令是:http 網址(url)
6. http.server庫
整個web伺服器實現都是在使用這個庫,他替我們解決tcp連結,請求解析等很多內容,我們只需要實現RequestHandler類的處理邏輯編寫(這裡也只涉及到了do_GET).
7.socket模組
socket套接字是做什麼用的?-->兩個端點的程式之間的“資訊通道”。即計算機1中的程式與計算機2中的程式通過socket傳送資訊。套接字是一個類,一個套接字是socket模組中的socket類中的一個例項。一個套接字處理一次通訊(伺服器和客戶機),各自進行設定,對應有不同的方法,比如說,s.connect就是客戶機,s.listen(5)就是伺服器。
連線方式在於一個connect(),一個listen(),使用accept()方法來完成。(accept()是伺服器端開始監聽後,可以接受客戶端的連線。)accept返回(client,address)元祖,client是客戶端套接字,而address是地址。處理完與該客戶端的連線後,再次呼叫accept方法開始等待下一個連線。
(1)字串format方法
(2)**dict
(3)str/byte轉換
1. os庫
#獲取檔案路徑 fullpath = os.getcwd() + self.path (+號前得到當前路徑,後面是得到handler得到的路徑,如/plain.html
#判斷路徑是否存在 os.path.exist(fullpath)
#判斷路徑是否是檔案 os.path.isfile(fullpath)
2. subprocess庫如何實現執行外部命令獲得該輸出
我們使用subprocess庫,具體程式碼是:
subprocess.check_output(['cmd', 'arg1', 'arg2'])
本例中為data = subprocess.check_output(['python', fullpath])參考:
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/28/2612910.html
http://www.magicsite.cn/blog/web/other/other298023.html