
關於C++中四位元組對齊的坑
最近做一個工程,大體的意思是在程式中定義一個結構,執行中會將結構直接寫到檔案中,然後另一個程式會用同樣的結構讀出來。為了驗證是寫檔案的程式的問題還是讀檔案的程式的問題,用winhex來開啟檔案,仿照結構體定義寫tpl模板檔案讀取檔案
可是問題出現了,讀程式和寫程式都能正確的讀取某個變數,但是winhex檢視就不對。
結構體示意
typedef struct{
char[4] a;
short b;
char c;
int d;
};定義的tpl檔案片段:
char[4] "a" int16 "b" int8 "c" int32 "d"
使用winhex檢視d的值時,不對。
這就是因為四位元組對齊的原因。檢視記憶體,就會發現在c和d之間有兩個位元組的0值。
這是一個四位元組對齊的坑。
修改的方法一個是指定1位元組對齊,另一個是在winhex的tpl中增加一行move 2
轉載一篇寫的不錯的關於四位元組對齊的文章。
引言
考慮下面的結構體定義:
1 typedef struct{
2 char c1;
3 short s;
4 char c2;
5 int i;
6 }T_FOO;
假設這個結構體的成員在記憶體中是緊湊排列的,且c1的起始地址是0,則s的地址就是1,c2的地址是3,i的地址是4。
現在,我們編寫一個簡單的程式:

1 int main(void){
2 T_FOO a;
3 printf("c1 -> %d, s -> %d, c2 -> %d, i -> %d\n",
4 (unsigned int)(void*)&a.c1 - (unsigned int)(void*)&a,
5 (unsigned int)(void*)&a.s - (unsigned int)(void*)&a,
6 (unsigned int)(void*)&a.c2 - (unsigned int)(void*)&a,
7 (unsigned int)(void*)&a.i - (unsigned int)(void*)&a);
8 return 0;
9 }
執行後輸出:
1 c1 -> 0, s -> 2, c2 -> 4, i -> 8
為什麼會這樣?這就是位元組對齊導致的問題。
本文在參考諸多資料的基礎上,詳細介紹常見的位元組對齊問題。因成文較早,資料來源大多已不可考,敬請諒解。
一 什麼是位元組對齊
現代計算機中,記憶體空間按照位元組劃分,理論上可以從任何起始地址訪問任意型別的變數。但實際中在訪問特定型別變數時經常在特定的記憶體地址訪問,這就需要各種型別資料按照一定的規則在空間上排列,而不是順序一個接一個地存放,這就是對齊。
二 對齊的原因和作用
不同硬體平臺對儲存空間的處理上存在很大的不同。某些平臺對特定型別的資料只能從特定地址開始存取,而不允許其在記憶體中任意存放。例如Motorola 68000 處理器不允許16位的字存放在奇地址,否則會觸發異常,因此在這種架構下程式設計必須保證位元組對齊。
但最常見的情況是,如果不按照平臺要求對資料存放進行對齊,會帶來存取效率上的損失。比如32位的Intel處理器通過匯流排訪問(包括讀和寫)記憶體資料。每個匯流排週期從偶地址開始訪問32位記憶體資料,記憶體資料以位元組為單位存放。如果一個32位的資料沒有存放在4位元組整除的記憶體地址處,那麼處理器就需要2個匯流排週期對其進行訪問,顯然訪問效率下降很多。
因此,通過合理的記憶體對齊可以提高訪問效率。為使CPU能夠對資料進行快速訪問,資料的起始地址應具有“對齊”特性。比如4位元組資料的起始地址應位於4位元組邊界上,即起始地址能夠被4整除。
此外,合理利用位元組對齊還可以有效地節省儲存空間。但要注意,在32位機中使用1位元組或2位元組對齊,反而會降低變數訪問速度。因此需要考慮處理器型別。還應考慮編譯器的型別。在VC/C++和GNU GCC中都是預設是4位元組對齊。
三 對齊的分類和準則
主要基於Intel X86架構介紹結構體對齊和棧記憶體對齊,位域本質上為結構體型別。
對於Intel X86平臺,每次分配記憶體應該是從4的整數倍地址開始分配,無論是對結構體變數還是簡單型別的變數。
3.1 結構體對齊
在C語言中,結構體是種複合資料型別,其構成元素既可以是基本資料型別(如int、long、float等)的變數,也可以是一些複合資料型別(如陣列、結構體、聯合等)的資料單元。編譯器為結構體的每個成員按照其自然邊界(alignment)分配空間。各成員按照它們被宣告的順序在記憶體中順序儲存,第一個成員的地址和整個結構的地址相同。
位元組對齊的問題主要就是針對結構體。
3.1.1 簡單示例
先看個簡單的例子(32位,X86處理器,GCC編譯器):
【例1】設結構體如下定義:
1 struct A{
2 int a;
3 char b;
4 short c;
5 };
6 struct B{
7 char b;
8 int a;
9 short c;
10 };
已知32位機器上各資料型別的長度為:char為1位元組、short為2位元組、int為4位元組、long為4位元組、float為4位元組、double為8位元組。那麼上面兩個結構體大小如何呢?
結果是:sizeof(strcut A)值為8;sizeof(struct B)的值卻是12。
結構體A中包含一個4位元組的int資料,一個1位元組char資料和一個2位元組short資料;B也一樣。按理說A和B大小應該都是7位元組。之所以出現上述結果,就是因為編譯器要對資料成員在空間上進行對齊。
3.1.2 對齊準則
先來看四個重要的基本概念:
1) 資料型別自身的對齊值:char型資料自身對齊值為1位元組,short型資料為2位元組,int/float型為4位元組,double型為8位元組。
2) 結構體或類的自身對齊值:其成員中自身對齊值最大的那個值。
3) 指定對齊值:#pragma pack (value)時的指定對齊值value。
4) 資料成員、結構體和類的有效對齊值:自身對齊值和指定對齊值中較小者,即有效對齊值=min{自身對齊值,當前指定的pack值}。
基於上面這些值,就可以方便地討論具體資料結構的成員和其自身的對齊方式。
其中,有效對齊值N是最終用來決定資料存放地址方式的值。有效對齊N表示“對齊在N上”,即該資料的“存放起始地址%N=0”。而資料結構中的資料變數都是按定義的先後順序存放。第一個資料變數的起始地址就是資料結構的起始地址。結構體的成員變數要對齊存放,結構體本身也要根據自身的有效對齊值圓整(即結構體成員變數佔用總長度為結構體有效對齊值的整數倍)。
以此分析3.1.1節中的結構體B:
假設B從地址空間0x0000開始存放,且指定對齊值預設為4(4位元組對齊)。成員變數b的自身對齊值是1,比預設指定對齊值4小,所以其有效對齊值為1,其存放地址0x0000符合0x0000%1=0。成員變數a自身對齊值為4,所以有效對齊值也為4,只能存放在起始地址為0x0004~0x0007四個連續的位元組空間中,符合0x0004%4=0且緊靠第一個變數。變數c自身對齊值為 2,所以有效對齊值也是2,可存放在0x0008~0x0009兩個位元組空間中,符合0x0008%2=0。所以從0x0000~0x0009存放的都是B內容。
再看資料結構B的自身對齊值為其變數中最大對齊值(這裡是b)所以就是4,所以結構體的有效對齊值也是4。根據結構體圓整的要求, 0x0000~0x0009=10位元組,(10+2)%4=0。所以0x0000A~0x000B也為結構體B所佔用。故B從0x0000到0x000B 共有12個位元組,sizeof(struct B)=12。
之所以編譯器在後面補充2個位元組,是為了實現結構陣列的存取效率。試想如果定義一個結構B的陣列,那麼第一個結構起始地址是0沒有問題,但是第二個結構呢?按照陣列的定義,陣列中所有元素都緊挨著。如果我們不把結構體大小補充為4的整數倍,那麼下一個結構的起始地址將是0x0000A,這顯然不能滿足結構的地址對齊。因此要把結構體補充成有效對齊大小的整數倍。其實對於char/short/int/float/double等已有型別的自身對齊值也是基於陣列考慮的,只是因為這些型別的長度已知,所以他們的自身對齊值也就已知。
上面的概念非常便於理解,不過個人還是更喜歡下面的對齊準則。
結構體位元組對齊的細節和具體編譯器實現相關,但一般而言滿足三個準則:
1) 結構體變數的首地址能夠被其最寬基本型別成員的大小所整除;
2) 結構體每個成員相對結構體首地址的偏移量(offset)都是成員大小的整數倍,如有需要編譯器會在成員之間加上填充位元組(internal adding);
3) 結構體的總大小為結構體最寬基本型別成員大小的整數倍,如有需要編譯器會在最末一個成員之後加上填充位元組{trailing padding}。
對於以上規則的說明如下:
第一條:編譯器在給結構體開闢空間時,首先找到結構體中最寬的基本資料型別,然後尋找記憶體地址能被該基本資料型別所整除的位置,作為結構體的首地址。將這個最寬的基本資料型別的大小作為上面介紹的對齊模數。
第二條:為結構體的一個成員開闢空間之前,編譯器首先檢查預開闢空間的首地址相對於結構體首地址的偏移是否是本成員大小的整數倍,若是,則存放本成員,反之,則在本成員和上一個成員之間填充一定的位元組,以達到整數倍的要求,也就是將預開闢空間的首地址後移幾個位元組。
第三條:結構體總大小是包括填充位元組,最後一個成員滿足上面兩條以外,還必須滿足第三條,否則就必須在最後填充幾個位元組以達到本條要求。
【例2】假設4位元組對齊,以下程式的輸出結果是多少?
1 /* OFFSET巨集定義可取得指定結構體某成員在結構體內部的偏移 */
2 #define OFFSET(st, field) (size_t)&(((st*)0)->field)
3 typedef struct{
4 char a;
5 short b;
6 char c;
7 int d;
8 char e[3];
9 }T_Test;
10
11 int main(void){
12 printf("Size = %d\n a-%d, b-%d, c-%d, d-%d\n e[0]-%d, e[1]-%d, e[2]-%d\n",
13 sizeof(T_Test), OFFSET(T_Test, a), OFFSET(T_Test, b),
14 OFFSET(T_Test, c), OFFSET(T_Test, d), OFFSET(T_Test, e[0]),
15 OFFSET(T_Test, e[1]),OFFSET(T_Test, e[2]));
16 return 0;
17 }
執行後輸出如下:
1 Size = 16 2 a-0, b-2, c-4, d-8 3 e[0]-12, e[1]-13, e[2]-14
下面來具體分析:
首先char a佔用1個位元組,沒問題。
short b本身佔用2個位元組,根據上面準則2,需要在b和a之間填充1個位元組。
char c佔用1個位元組,沒問題。
int d本身佔用4個位元組,根據準則2,需要在d和c之間填充3個位元組。
char e[3];本身佔用3個位元組,根據原則3,需要在其後補充1個位元組。
因此,sizeof(T_Test) = 1 + 1 + 2 + 1 + 3 + 4 + 3 + 1 = 16位元組。
3.1.3 對齊的隱患
3.1.3.1 資料型別轉換
程式碼中關於對齊的隱患,很多是隱式的。例如,在強制型別轉換的時候:
1 int main(void){
2 unsigned int i = 0x12345678;
3
4 unsigned char *p = (unsigned char *)&i;
5 *p = 0x00;
6 unsigned short *p1 = (unsigned short *)(p+1);
7 *p1 = 0x0000;
8
9 return 0;
10 }
最後兩句程式碼,從奇數邊界去訪問unsigned short型變數,顯然不符合對齊的規定。在X86上,類似的操作只會影響效率;但在MIPS或者SPARC上可能導致error,因為它們要求必須位元組對齊。
又如對於3.1.1節的結構體struct B,定義如下函式:
1 void Func(struct B *p){
2 //Code
3 }
在函式體內如果直接訪問p->a,則很可能會異常。因為MIPS認為a是int,其地址應該是4的倍數,但p->a的地址很可能不是4的倍數。
如果p的地址不在對齊邊界上就可能出問題,比如p來自一個跨CPU的資料包(多種資料型別的資料被按順序放置在一個數據包中傳輸),或p是經過指標移位算出來的。因此要特別注意跨CPU資料的介面函式對介面輸入資料的處理,以及指標移位再強制轉換為結構指標進行訪問時的安全性。
解決方式如下:
1) 定義一個此結構的區域性變數,用memmove方式將資料拷貝進來。
1 void Func(struct B *p){
2 struct B tData;
3 memmove(&tData, p, sizeof(struct B));
4 //此後可安全訪問tData.a,因為編譯器已將tData分配在正確的起始地址上
5 }
注意:如果能確定p的起始地址沒問題,則不需要這麼處理;如果不能確定(比如跨CPU輸入資料、或指標移位運算出來的資料要特別小心),則需要這樣處理。
2) 用#pragma pack (1)將STRUCT_T定義為1位元組對齊方式。
3.1.3.2 處理器間資料通訊
處理器間通過訊息(對於C/C++而言就是結構體)進行通訊時,需要注意位元組對齊以及位元組序的問題。
大多數編譯器提供記憶體對其的選項供使用者使用。這樣使用者可以根據處理器的情況選擇不同的位元組對齊方式。例如C/C++編譯器提供的#pragma pack(n) n=1,2,4等,讓編譯器在生成目標檔案時,使記憶體資料按照指定的方式排布在1,2,4等位元組整除的記憶體地址處。
然而在不同編譯平臺或處理器上,位元組對齊會造成訊息結構長度的變化。編譯器為了使位元組對齊可能會對訊息結構體進行填充,不同編譯平臺可能填充為不同的形式,大大增加處理器間資料通訊的風險。
下面以32位處理器為例,提出一種記憶體對齊方法以解決上述問題。
對於本地使用的資料結構,為提高記憶體訪問效率,採用四位元組對齊方式;同時為了減少記憶體的開銷,合理安排結構體成員的位置,減少四位元組對齊導致的成員之間的空隙,降低記憶體開銷。
對於處理器之間的資料結構,需要保證訊息長度不會因不同編譯平臺或處理器而導致訊息結構體長度發生變化,使用一位元組對齊方式對訊息結構進行緊縮;為保證處理器之間的訊息資料結構的記憶體訪問效率,採用位元組填充的方式自己對訊息中成員進行四位元組對齊。
資料結構的成員位置要兼顧成員之間的關係、資料訪問效率和空間利用率。順序安排原則是:四位元組的放在最前面,兩位元組的緊接最後一個四位元組成員,一位元組緊接最後一個兩位元組成員,填充位元組放在最後。
舉例如下:
1 typedef struct tag_T_MSG{
2 long ParaA;
3 long ParaB;
4 short ParaC;
5 char ParaD;
6 char Pad; //填充位元組
7 }T_MSG;
3.1.3.3 排查對齊問題
如果出現對齊或者賦值問題可檢視:
1) 編譯器的位元組序大小端設定;
2) 處理器架構本身是否支援非對齊訪問;
3) 如果支援看設定對齊與否,如果沒有則看訪問時需要加某些特殊的修飾來標誌其特殊訪問操作。
3.1.4 更改對齊方式
主要是更改C編譯器的預設位元組對齊方式。
在預設情況下,C編譯器為每一個變數或是資料單元按其自然對界條件分配空間。一般地,可以通過下面的方法來改變預設的對界條件:
- 使用偽指令#pragma pack(n):C編譯器將按照n個位元組對齊;
- 使用偽指令#pragma pack(): 取消自定義位元組對齊方式。
另外,還有如下的一種方式(GCC特有語法):
- __attribute((aligned (n))): 讓所作用的結構成員對齊在n位元組自然邊界上。如果結構體中有成員的長度大於n,則按照最大成員的長度來對齊。
- __attribute__ ((packed)): 取消結構在編譯過程中的優化對齊,按照實際佔用位元組數進行對齊。
【注】__attribute__機制是GCC的一大特色,可以設定函式屬性(Function Attribute)、變數屬性(Variable Attribute)和型別屬性(Type Attribute)。詳細介紹請參考:
下面具體針對MS VC/C++ 6.0編譯器介紹下如何修改編譯器預設對齊值。
1) VC/C++ IDE環境中,可在[Project]|[Settings],C/C++選項卡Category的Code Generation選項的Struct Member Alignment中修改,預設是8位元組。

VC/C++中的編譯選項有/Zp[1|2|4|8|16],/Zpn表示以n位元組邊界對齊。n位元組邊界對齊是指一個成員的地址必須安排在成員的尺寸的整數倍地址上或者是n的整數倍地址上,取它們中的最小值。亦即:min(sizeof(member), n)。
實際上,1位元組邊界對齊也就表示結構成員之間沒有空洞。
/Zpn選項應用於整個工程,影響所有參與編譯的結構體。在Struct member alignment中可選擇不同的對齊值來改變編譯選項。
2) 在編碼時,可用#pragma pack動態修改對齊值。具體語法說明見附錄5.3節。
自定義對齊值後要用#pragma pack()來還原,否則會對後面的結構造成影響。
【例3】分析如下結構體C:
1 #pragma pack(2) //指定按2位元組對齊
2 struct C{
3 char b;
4 int a;
5 short c;
6 };
7 #pragma pack() //取消指定對齊,恢復預設對齊
變數b自身對齊值為1,指定對齊值為2,所以有效對齊值為1,假設C從0x0000開始,則b存放在0x0000,符合0x0000%1= 0;變數a自身對齊值為4,指定對齊值為2,所以有效對齊值為2,順序存放在0x0002~0x0005四個連續位元組中,符合0x0002%2=0。變數c的自身對齊值為2,所以有效對齊值為2,順序存放在0x0006~0x0007中,符合 0x0006%2=0。所以從0x0000到0x00007共八位元組存放的是C的變數。C的自身對齊值為4,所以其有效對齊值為2。又8%2=0,C只佔用0x0000~0x0007的八個位元組。所以sizeof(struct C) = 8。
注意,結構體對齊到的位元組數並非完全取決於當前指定的pack值,如下:
1 #pragma pack(8)
2 struct D{
3 char b;
4 short a;
5 char c;
6 };
7 #pragma pack()
雖然#pragma pack(8),但依然按照兩位元組對齊,所以sizeof(struct D)的值為6。因為:對齊到的位元組數 = min{當前指定的pack值,最大成員大小}。
另外,GNU GCC編譯器中按1位元組對齊可寫為以下形式:
1 #define GNUC_PACKED __attribute__((packed))
2 struct C{
3 char b;
4 int a;
5 short c;
6 }GNUC_PACKED;
此時sizeof(struct C)的值為7。
3.2 棧記憶體對齊
在VC/C++中,棧的對齊方式不受結構體成員對齊選項的影響。總是保持對齊且對齊在4位元組邊界上。
【例4】
1 #pragma pack(push, 1) //後面可改為1, 2, 4, 8
2 struct StrtE{
3 char m1;
4 long m2;
5 };
6 #pragma pack(pop)
7
8 int main(void){
9 char a;
10 short b;
11 int c;
12 double d[2];
13 struct StrtE s;
14
15 printf("a address: %p\n", &a);
16 printf("b address: %p\n", &b);
17 printf("c address: %p\n", &c);
18 printf("d[0] address: %p\n", &(d[0]));
19 printf("d[1] address: %p\n", &(d[1]));
20 printf("s address: %p\n", &s);
21 printf("s.m2 address: %p\n", &(s.m2));
22 return 0;
23 }
結果如下:
1 a address: 0xbfc4cfff 2 b address: 0xbfc4cffc 3 c address: 0xbfc4cff8 4 d[0] address: 0xbfc4cfe8 5 d[1] address: 0xbfc4cff0 6 s address: 0xbfc4cfe3 7 s.m2 address: 0xbfc4cfe4
可以看出都是對齊到4位元組。並且前面的char和short並沒有被湊在一起(成4位元組),這和結構體內的處理是不同的。
至於為什麼輸出的地址值是變小的,這是因為該平臺下的棧是倒著“生長”的。
3.3 位域對齊
3.3.1 位域定義
有些資訊在儲存時,並不需要佔用一個完整的位元組,而只需佔幾個或一個二進位制位。例如在存放一個開關量時,只有0和1兩種狀態,用一位二進位即可。為了節省儲存空間和處理簡便,C語言提供了一種資料結構,稱為“位域”或“位段”。
位域是一種特殊的結構成員或聯合成員(即只能用在結構或聯合中),用於指定該成員在記憶體儲存時所佔用的位數,從而在機器內更緊湊地表示資料。每個位域有一個域名,允許在程式中按域名操作對應的位。這樣就可用一個位元組的二進位制位域來表示幾個不同的物件。
位域定義與結構定義類似,其形式為:
|
struct 位域結構名 { 位域列表 }; |
其中位域列表的形式為:
|
型別說明符位域名:位域長度 |
位域的使用和結構成員的使用相同,其一般形式為:
|
位域變數名.位域名 |
位域允許用各種格式輸出。
位域在本質上就是一種結構型別,不過其成員是按二進位分配的。位域變數的說明與結構變數說明的方式相同,可先定義後說明、同時定義說明或直接說明。
位域的使用主要為下面兩種情況:
1) 當機器可用記憶體空間較少而使用位域可大量節省記憶體時。如把結構作為大陣列的元素時。
2) 當需要把一結構體或聯合對映成某預定的組織結構時。如需要訪問位元組內的特定位時。
3.3.2 對齊準則
位域成員不能單獨被取sizeof值。下面主要討論含有位域的結構體的sizeof。
C99規定int、unsigned int和bool可以作為位域型別,但編譯器幾乎都對此作了擴充套件,允許其它型別的存在。位域作為嵌入式系統中非常常見的一種程式設計工具,優點在於壓縮程式的儲存空間。
其對齊規則大致為:
1) 如果相鄰位域欄位的型別相同,且其位寬之和小於型別的sizeof大小,則後面的欄位將緊鄰前一個欄位儲存,直到不能容納為止;
2) 如果相鄰位域欄位的型別相同,但其位寬之和大於型別的sizeof大小,則後面的欄位將從新的儲存單元開始,其偏移量為其型別大小的整數倍;
3) 如果相鄰的位域欄位的型別不同,則各編譯器的具體實現有差異,VC6採取不壓縮方式,Dev-C++和GCC採取壓縮方式;
4) 如果位域欄位之間穿插著非位域欄位,則不進行壓縮;
5) 整個結構體的總大小為最寬基本型別成員大小的整數倍,而位域則按照其最寬型別位元組數對齊。
【例5】
1 struct BitField{
2 char element1 : 1;
3 char element2 : 4;
4 char element3 : 5;
5 };
位域型別為char,第1個位元組僅能容納下element1和element2,所以element1和element2被壓縮到第1個位元組中,而element3只能從下一個位元組開始。因此sizeof(BitField)的結果為2。
【例6】
1 struct BitField1{
2 char element1 : 1;
3 short element2 : 5;
4 char element3 : 7;
5 };
由於相鄰位域型別不同,在VC6中其sizeof為6,在Dev-C++中為2。
【例7】
1 struct BitField2{
2 char element1 : 3;
3 char element2 ;
4 char element3 : 5;
5 };
非位域欄位穿插在其中,不會產生壓縮,在VC6和Dev-C++中得到的大小均為3。
【例8】
1 struct StructBitField{
2 int element1 : 1;
3 int element2 : 5;
4 int element3 : 29;
5 int element4 : 6;
6 char element5 :2;
7 char stelement; //在含位域的結構或聯合中也可同時說明普通成員
8 };
位域中最寬型別int的位元組數為4,因此結構體按4位元組對齊,在VC6中其sizeof為16。
3.3.3 注意事項
關於位域操作有幾點需要注意:
1) 位域的地址不能訪問,因此不允許將&運算子用於位域。不能使用指向位域的指標也不能使用位域的陣列(陣列是種特殊指標)。
例如,scanf函式無法直接向位域中儲存資料:
1 int main(void){
2 struct BitField1 tBit;
3 scanf("%d", &tBit.element2); //error: cannot take address of bit-field 'element2'
4 return 0;
5 }
可用scanf函式將輸入讀入到一個普通的整型變數中,然後再賦值給tBit.element2。
2) 位域不能作為函式返回的結果。
3) 位域以定義的型別為單位,且位域的長度不能夠超過所定義型別的長度。例如定義int a:33是不允許的。
4) 位域可以不指定位域名,但不能訪問無名的位域。
位域可以無位域名,只用作填充或調整位置,佔位大小取決於該型別。例如,char :0表示整個位域向後推一個位元組,即該無名位域後的下一個位域從下一個位元組開始存放,同理short :0和int :0分別表示整個位域向後推兩個和四個位元組。
當空位域的長度為具體數值N時(如int :2),該變數僅用來佔位N位。
【例9】
1 struct BitField3{
2 char element1 : 3;
3 char :6;
4 char element3 : 5;
5 };
結構體大小為3。因為element1佔3位,後面要保留6位而char為8位,所以保留的6位只能放到第2個位元組。同樣element3只能放到第3位元組。
1 struct BitField4{
2 char element1 : 3;
3 char :0;
4 char element3 : 5;
5 };
長度為0的位域告訴編譯器將下一個位域放在一個儲存單元的起始位置。如上,編譯器會給成員element1分配3位,接著跳過餘下的4位到下一個儲存單元,然後給成員element3分配5位。故上面的結構體大小為2。
5) 位域的表示範圍。
- 位域的賦值不能超過其可以表示的範圍;
- 位域的型別決定該編碼能表示的值的結果。
對於第二點,若位域為unsigned型別,則直接轉化為正數;若非unsigned型別,則先判斷最高位是否為1,若為1表示補碼,則對其除符號位外的所有位取反再加一得到最後的結果資料(原碼)。如:
1 unsigned int p:3 = 111; //p表示7 2 int p:3 = 111; //p 表示-1,對除符號位之外的所有位取反再加一
6) 帶位域的結構在記憶體中各個位域的儲存方式取決於編譯器,既可從左到右也可從右到左儲存。
【例10】在VC6下執行下面的程式碼:
int main(void){
union{
int i;
struct{
char a : 1;
char b : 1;
char c : 2;
}bits;
}num;
printf("Input an integer for i(0~15): ");
scanf("%d", &num.i);
printf("i = %d, cba = %d %d %d\n", num.i, num.bits.c, num.bits.b, num.bits.a);
return 0;
}
輸入i值為11,則輸出為i = 11, cba = -2 -1 -1。
Intel x86處理器按小位元組序儲存資料,所以bits中的位域在記憶體中放置順序為ccba。當num.i置為11時,bits的最低有效位(即位域a)的值為1,a、b、c按低地址到高地址分別儲存為10、1、1(二進位制)。
但為什麼最後的列印結果是a=-1而不是1?
因為位域a定義的型別signed char是有符號數,所以儘管a只有1位,仍要進行符號擴充套件。1做為補碼存在,對應原碼-1。
如果將a、b、c的型別定義為unsigned char,即可得到cba = 2 1 1。1011即為11的二進位制數。
注:C語言中,不同的成員使用共同的儲存區域的資料構造型別稱為聯合(或共用體)。聯合佔用空間的大小取決於型別長度最大的成員。聯合在定義、說明和使用形式上與結構體相似。
7) 位域的實現會因編譯器的不同而不同,使用位域會影響程式可移植性。因此除非必要否則最好不要使用位域。
8) 儘管使用位域可以節省記憶體空間,但卻增加了處理時間。當訪問各個位域成員時,需要把位域從它所在的字中分解出來或反過來把一值壓縮存到位域所在的字位中。
四 總結
讓我們回到引言部分的問題。
預設情況下,C/C++編譯器預設將結構、棧中的成員資料進行記憶體對齊。因此,引言程式輸出就變成"c1 -> 0, s -> 2, c2 -> 4, i -> 8"。
編譯器將未對齊的成員向後移,將每一個都成員對齊到自然邊界上,從而也導致整個結構的尺寸變大。儘管會犧牲一點空間(成員之間有空洞),但提高了效能。
也正是這個原因,引言例子中sizeof(T_ FOO)為12,而不是8。
總結說來,就是
|
在結構體中,綜合考慮變數本身和指定的對齊值; 在棧上,不考慮變數本身的大小,統一對齊到4位元組。 |
五 附錄
5.1 位元組序與網路序
5.1.1 位元組序
位元組序,顧名思義就是位元組的高低位存放順序。
對於單位元組,大部分處理器以相同的順序處理位元位,因此單位元組的存放和傳輸方式一般相同。
對於多位元組資料,如整型(32位機中一般佔4位元組),在不同的處理器的存放方式主要有兩種(以記憶體中0x0A0B0C0D的存放方式為例)。
1) 大位元組序(Big-Endian,又稱大端序或大尾序)
在計算機中,儲存介質以下面方式儲存整數0x0A0B0C0D則稱為大位元組序:
|
資料以8bit為單位 |
|||||
|
低地址方向 |
0x0A |
0x0B |
0x0C |
0x0D |
高地址方向 |
|
資料以16bit為單位 |
|||||
|
低地址方向 |
0x0A0B |
0x0C0D |
高地址方向 |
||
其中,最高有效位(MSB,Most Significant Byte)0x0A儲存在最低的記憶體地址處。下個位元組0x0B存在後面的地址處。同時,最高的16bit單元0x0A0B儲存在低位。
簡而言之,大位元組序就是“高位元組存入低地址,低位元組存入高地址”。
這裡講個詞源典故:“endian”一詞來源於喬納森·斯威夫特的小說《格列佛遊記》。小說中,小人國為水煮蛋該從大的一端(Big-End)剝開還是小的一端(Little-End)剝開而爭論,爭論的雙方分別被稱為Big-endians和Little-endians。
1980年,Danny Cohen在其著名的論文"On Holy Wars and a Plea for Peace"中為平息一場關於位元組該以什麼樣的順序傳送的爭論而引用了該詞。
借用上面的典故,想象一下要把熟雞蛋旋轉著穩立起來,大頭(高位元組)肯定在下面(低地址)^_^
2) 小位元組序(Little-Endian,又稱小端序或小尾序)
在計算機中,儲存介質以下面方式儲存整數0x0A0B0C0D則稱為小位元組序:
|
資料以8bit為單位 |
|||||
|
高地址方向 |
0x0A |
0x0B |
0x0C |
0x0D |
低地址方向 |
|
資料以16bit為單位 |
|||||
|
高地址方向 |
0x0A0B |
0x0C0D |
低地址方向 |
||
其中,最低有效位(LSB,Least Significant Byte)0x0D儲存在最低的記憶體地址處。後面位元組依次存在後面的地址處。同時,最低的16bit單元0x0A0B儲存在低位。
可見,小位元組序就是“高位元組存入高地址,低位元組存入低地址”。
C語言中的位域結構也要遵循位元序(類似位元組序)。例如:
1 struct bitfield{
2 unsigned char a: 2;
3 unsigned char b: 6;
4 }
該位域結構佔1個位元組,假設賦值a = 0x01和b=0x02,則大位元組機器上該位元組為(01)(000010),小位元組機器上該位元組為(000010)(01)。因此在編寫可移植程式碼時,需要加條件編譯。
注意,在包含位域的C結構中,若位域A在位域B之前定義,則位域A所佔用的記憶體空間地址低於位域B所佔用的記憶體空間。
另見以下聯合體,在小位元組機器上若low=0x01,high=0x02,則hex=0x21:
1 int main(void){
2 union{
3 unsigned char hex;
4 struct{
5 unsigned char low : 4;
6 unsigned char high : 4;
7 };
8 }convert;
9 convert.low = 0x01;
10 convert.high = 0x02;
11 printf("hex = 0x%0x\n", convert.hex);
12 return 0;
13 }
5.1.2 網路序
網路傳輸一般採用大位元組序,也稱為網路位元組序或網路序。IP協議中定義大位元組序為網路位元組序。
對於可移植的程式碼來說,將接收的網路資料轉換成主機的位元組序是必須的,一般會有成對的函式用於把網路資料轉換成相應的主機位元組序或反之(若主機位元組序與網路位元組序相同,通常將函式定義為空巨集)。
伯克利socket API定義了一組轉換函式,用於16和32位整數在網路序和主機位元組序之間的轉換。Htonl、htons用於主機序轉換到網路序;ntohl、ntohs用於網路序轉換到本機序。
注意:在大小位元組序轉換時,必須考慮待轉換資料的長度(如5.1.1節的資料單元)。另外對於單字元或小於單字元的幾個bit資料,是不必轉換的,因為在機器儲存和網路傳送的一個字元內的bit位儲存順序是一致的。
5.1.3 位序
用於描述序列裝置的傳輸順序。一般硬體傳輸採用小位元組序(先傳低位),但I2C協議採用大位元組序。網路協議中只有資料鏈路層的底端會涉及到。
5.1.4 處理器位元組序
不同處理器體系的位元組序如下所示:
- X86、MOS Technology 6502、Z80、VAX、PDP-11等處理器為Little endian;
- Motorola 6800、Motorola 68000、PowerPC 970、System/370、SPARC(除V9外)等處理器為Big endian;
- ARM、PowerPC (除PowerPC 970外)、DEC Alpha,SPARC V9,MIPS,PA-RISC and IA64等的位元組序是可配置的。
5.1.5 位元組序程式設計
請看下面的語句:
1 printf("%c\n", *((short*)"AB") >> 8);
在大位元組序下輸出為'A',小位元組序下輸出為'B'。
下面的程式碼可用來判斷本地機器位元組序:
1 //位元組序列舉型別
2 typedef enum{
3 ENDIAN_LITTLE = (INT8U)0X00,
4 ENDIAN_BIG = (INT8U)0X01
5 }E_ENDIAN_TYPE;
6
7 E_ENDIAN_TYPE GetEndianType(VOID)
8 {
9 INT32U dwData = 0x12345678;
10
11 if(0x78 == *((INT8U*)&dwData))
12 return ENDIAN_LITTLE;
13 else
14 return ENDIAN_BIG;
15 }
16
17 //Start of GetEndianTypeTest//
18 #include <endian.h>
19 VOID GetEndianTypeTest(VOID)
20 {
21 #if _BYTE_ORDER == _LITTLE_ENDIAN
22 printf("[%s]<Test Case> Result: %s, EndianType = %s!\n", __FUNCTION__,
23 (ENDIAN_LITTLE != GetEndianType()) ? "ERROR" : "OK", "Little");
24 #elif _BYTE_ORDER == _BIG_ENDIAN
25 printf("[%s]<Test Case> Result: %s, EndianType = %s!\n", __FUNCTION__,
26 (ENDIAN_BIG != GetEndianType()) ? "ERROR" : "OK", "Big");
27 #endif
28 }
29 //End of GetEndianTypeTest//
在位元組序不同的平臺間的交換資料時,必須進行轉換。比如對於int型別,大位元組序寫入檔案:
1 int i = 100; 2 write(fd, &i, sizeof(int));
小位元組序讀出後:
1 int i;
2 read(fd, &i, sizeof(int));
3 char buf[sizeof(int)];
4 memcpy(buf, &i, sizeof(int));
5 for(i = 0; i < sizeof(int); i++)
6 {
7 int v = buf[sizeof(int) - i - 1];
8 buf[sizeof(int) - 1] = buf[i];
9 buf[i] = v;
10 }
11 memcpy(&i, buf, sizeof(int));
上面僅僅是個例子。在不同平臺間即使不存在位元組序的問題,也儘量不要直接傳遞二進位制資料。作為可選的方式就是使用文字來交換資料,這樣至少可以避免位元組序的問題。
很多的加密演算法為了追求速度,都會採取字串和數字之間的轉換,在計算完畢後,必須注意位元組序的問題,在某些實現中可以見到使用預編譯的方式來完成,這樣很不方便,如果使用前面的語句來判斷,就可以自動適應。
位元組序問題不僅影響異種平臺間傳遞資料,還影響諸如讀寫一些特殊格式檔案之類程式的可移植性。此時使用預編譯的方式來完成也是一個好辦法。
5.2 對齊時的填充位元組
程式碼如下:
1 struct A{
2 char c;
3 int i;
4 short s;
5 };
6 int main(void){
7 struct A a;
8 a.c = 1; a.i = 2; a.s = 3;
9 printf("sizeof(A)=%d\n", sizeof(struct A));
10 return 0;
11 }
執行後輸出為sizeof(A)=12。
VC6.0環境中,在main函式列印語句前設定斷點,執行到斷點處時根據結構體a的地址檢視變數儲存如下:

可見填充位元組為0xCC,即int3中斷。
5.3 pragma pack語法說明
|
#pragma pack(n) #pragma pack(push, 1) #pragma pack(pop) |
1) #pragma pack(n)
該指令指定結構和聯合成員的緊湊對齊。而一個完整的轉換單元的結構和聯合的緊湊對齊由/ Z p選項設定。緊湊對齊用pack編譯指示在資料說明層設定。該編譯指示在其出現後的第一個結構或者聯合說明處生效。該編譯指示對定義無效。
當使用#pragma pack (n) 時,n 為1、2、4、8 或1 6 。第一個結構成員後的每個結構成員都被儲存在更小的成員型別或n位元組界限內。如果使用無參量的#pragma pack,結構成員被緊湊為以/ Z p指定的值。該預設/ Z p緊湊值為/ Z p 8。
2. 編譯器也支援以下增強型語法:
#pragma pack( [ [ { push | pop } , ] [identifier, ] ] [ n] )
若不同的元件使用pack編譯指示指定不同的緊湊對齊, 這個語法允許你把程式元件組合為一個單獨的轉換單元。
帶push參量的pack編譯指示的每次出現將當前的緊湊對齊儲存到一個內部編譯器堆疊中。編譯指示的參量表從左到右讀取。如果使用push,則當前緊湊值被儲存起來;如果給出一個n值,該值將成為新的緊湊值。若指定一個識別符號,即選定一個名稱,則該識別符號將和這個新的的緊湊值聯絡起來。
帶一個pop參量的pack編譯指示的每次出現都會檢索內部編譯器堆疊頂的值,並使該值為新的緊湊對齊值。如果使用pop參量且內部編譯器堆疊是空的,則緊湊值為命令列給定的值,並將產生一個警告資訊。若使用pop且指定一個n值,該值將成為新的緊湊值。
若使用pop且指定一個識別符號,所有儲存在堆疊中的值將從棧中刪除,直到找到一個匹配的識別符號。這個與識別符號相關的緊湊值也從棧中移出,並且這個僅在識別符號入棧之前存在的緊湊值成為新的緊湊值。如果未找到匹配的識別符號, 將使用命令列設定的緊湊值,並且將產生一個一級警告。預設緊湊對齊為8。
pack編譯指示的新的增強功能讓你在編寫標頭檔案時,確保在遇到該標頭檔案的前後的緊湊值是一樣的。
5.4 Intel關於記憶體對齊的說明
以下內容節選自《Intel Architecture 32 Manual》。
字、雙字和四字在自然邊界上不需要在記憶體中對齊。(對於字、雙字和四字來說,自然邊界分別是偶數地址,可以被4整除的地址,和可以被8整除的地址。)
無論如何,為了提高程式的效能,資料結構(尤其是棧)應該儘可能地在自然邊界上對齊。原因在於,為了訪問未對齊的記憶體,處理器需要作兩次記憶體訪問;然而,對齊的記憶體訪問僅需要一次訪問。
一個字或雙字運算元跨越了4位元組邊界,或者一個四字運算元跨越了8位元組邊界,被認為是未對齊的,從而需要兩次匯流排週期來訪問記憶體。一個字起始地址是奇數但卻沒有跨越字邊界被認為是對齊的,能夠在一個匯流排週期中被訪問。
某些操作雙四字的指令需要記憶體運算元在自然邊界上對齊。如果運算元沒有對齊,這些指令將會產生一個通用保護異常(#GP)。雙四字的自然邊界是能夠被16 整除的地址。其他操作雙四字的指令允許未對齊的訪問(不會產生通用保護異常),然而,需要額外的記憶體匯流排週期來訪問記憶體中未對齊的資料。
5.5 不同架構處理器的對齊要求
RISC指令集處理器(MIPS/ARM):這種處理器的設計以效率為先,要求所訪問的多位元組資料(short/int/ long)的地址必須是為此資料大小的倍數,如short資料地址應為2的倍數,long資料地址應為4的倍數,也就是說是對齊的。
CISC指令集處理器(X86):沒有上述限制。
對齊處理策略
訪問非對齊多位元組資料時(pack資料),編譯器會將指令拆成多條(因為非對齊多位元組資料可能跨越地址對齊邊界),保證每條指令都從正確的起始地址上獲取資料,但也因此效率比較低。
訪問對齊資料時則只用一條指令獲取資料,因此對齊資料必須確保其起始地址是在對齊邊界上。如果不是在對齊的邊界,對X86 CPU是安全的,但對MIPS/ARM這種RISC CPU會出現“匯流排訪問異常”。
為什麼X86是安全的呢?
X86 CPU是如何進行資料對齊的。X86 CPU的EFLAGS暫存器中包含一個特殊的位標誌,稱為AC(對齊檢查的英文縮寫)標誌。按照預設設定,當CPU首次加電時,該標誌被設定為0。當該標誌是0時,CPU能夠自動執行它應該執行的操作,以便成功地訪問未對齊的資料值。然而,如果該標誌被設定為1,每當系統試圖訪問未對齊的資料時,CPU就會發出一個INT 17H中斷。X86的Windows 2000和Windows 98版本從來不改變這個CPU標誌位。因此,當應用程式在X86處理器上執行時,你根本看不到應用程式中出現數據未對齊的異常條件。
為什麼MIPS/ARM不安全呢?
因為MIPS/ARM CPU不能自動處理對未對齊資料的訪問。當未對齊的資料訪問發生時,CPU就會將這一情況通知作業系統。這時,作業系統將會確定它是否應該引發一個數據未對齊異常條件,對vxworks是會觸發這個異常的。
5.6 ARM下的對齊處理
有部分摘自ARM編譯器文件對齊部分。
對齊的使用:
1) __align(num)
用於修改最高級別物件的位元組邊界。在彙編中使用LDRD或STRD時就要用到此命令__align(8)進行修飾限制。來保證資料物件是相應對齊。
這個修飾物件的命令最大是8個位元組限制,可以讓2位元組的物件進行4位元組對齊,但不能讓4位元組的物件2位元組對齊。
__align是儲存類修改,只修飾最高階型別物件,不能用於結構或者函式物件。
2) __packed
進行一位元組對齊。需注意:
- 不能對packed的物件進行對齊;
- 所有物件的讀寫訪問都進行非對齊訪問;
- float及包含float的結構聯合及未用__packed的物件將不能位元組對齊;
- __packed對區域性整型變數無影響。
- 強制由unpacked物件向packed物件轉化時未定義。整型指標可以合法定義為packed,如__packed int* p(__packed int 則沒有意義)
對齊或非對齊讀寫訪問可能存在的問題:
1 //定義如下結構,b的起始地址不對齊。在棧中訪問b可能有問題,因為棧上資料對齊訪問
2 __packed struct STRUCT_TEST{
3 char a;
4 int b;
5 char c;
6 };
7 //將下面的變數定義成全域性靜態(不在棧上)
8 static char *p;
9 static struct STRUCT_TEST a;
10 void Main(){
11 __packed int *q; //定義成__packed來修飾當前q指向為非對齊的資料地址下面的訪問則可以
12
13 p = (char*)&a;
14 q = (int*)(p + 1);
15 *q = 0x87654321;
16 /* 得到賦值的彙編指令很清楚
17 ldr r5,0x20001590 ; = #0x12345678
18 [0xe1a00005] mov r0,r5
19 [0xeb0000b0] bl __rt_uwrite4 //在此處呼叫一個寫4位元組的操作函式
20
21 [0xe5c10000] strb r0,[r1,#0] //函式進行4次strb操作然後返回,正確訪問資料
22 [0xe1a02420] mov r2,r0,lsr #8
23 [0xe5c12001] strb r2,[r1,#1]
24 [0xe1a02820] mov r2,r0,lsr #16
25 [0xe5c12002] strb r2,[r1,#2]
26 [0xe1a02c20] mov r2,r0,lsr #24
27 [0xe5c12003] strb r2,[r1,#3]
28 [0xe1a0f00e] mov pc,r14
29
30 若q未加__packed修飾則彙編出來指令如下(會導致奇地址處訪問失敗):
31 [0xe59f2018] ldr r2,0x20001594 ; = #0x87654321
32 [0xe5812000] str r2,[r1,#0]
33 */
34 //這樣很清楚地看到非對齊訪問如何產生錯誤,以及如何消除非對齊訪問帶來的問題
35 //也可看到非對齊訪問和對齊訪問的指令差異會導致效率問題
36 }
5.7 《The C Book》之位域篇
While we're on the subject of structures, we might as well look at bitfields. They can only be declared inside a structure or a union, and allow you to specify some very small objects of a given number of bits in length. Their usefulness is limited and they aren't seen in many programs, but we'll deal with them anyway. This example should help to make things clear:
1 struct{
2 unsigned field1 :4; //field 4 bits wide
3 unsigned :3; //unnamed 3 bit field(allow for padding)
4 signed field2 :1; //one-bit field(can only be 0 or -1 in two's complement)
5 unsigned :0; //align next field on a storage unit
6 unsigned field3 :6;
7 }full_of_fields;
Each field is accessed and manipulated as if it were an ordinary member of a structure. The keywords signed and unsigned mean what you would expect, except that it is interesting to note that a 1-bit signed field on a two's complement machine can only take the values 0 or -1. The declarations are permitted to include the const and volatile qualifiers.
The main use of bitfields is either to allow tight packing of data or to be able to specify the fields within some externally produced data files. C gives no guarantee of the ordering of fields within machine words, so if you do use them for the latter reason, you program will not only be non-portable, it will be compiler-dependent too. The Standard says that fields are packed into ‘storage units’, which are typically machine words. The packing order, and whether or not a bitfield may cross a storage unit boundary, are implementation defined. To force alignment to a storage unit boundary, a zero width field is used before the one that you want to have aligned.
Be careful using them. It can require a surprising amount of run-time code to manipulate these things and you can end up using more space than they save.
Bit fields do not have addresses—you can't have pointers to them or arrays of them.
5.8 C語言位元組相關面試題
5.8.1 Intel/微軟C語言面試題
請看下面的問題:
1 #pragma pack(8)
2 struct s1{
3 short a;
4 long b;
5 };
6 struct s2{
7 char c;
8 s1 d;
9 long long e; //VC6.0下可能要用__int64代替雙long
10 };
11 #pragma pack()
問:1. sizeof(s2) = ? 2. s2的s1中的a後面空了幾個位元組接著是b?
【分析】
成員對齊有一個重要的條件,即每個成員分別按自己的方式對齊。
也就是說上面雖然指定了按8位元組對齊,但並不是所有的成員都是以8位元組對齊。其對齊的規則是:每個成員按其型別的對齊引數(通常是這個型別的大小)和指定對齊引數(這裡是8位元組)中較小的一個對齊,並且結構的長度必須為所用過的所有對齊引數的整數倍,不夠就補空位元組。
s1中成員a是1位元組,預設按1位元組對齊,而指定對齊引數為8,兩值中取1,即a按1位元組對齊;成員b是4個位元組,預設按4位元組對齊,這時就按4位元組對齊,所以sizeof(s1)應該為8;
s2中c和s1中a一樣,按1位元組對齊。而d 是個8位元組結構體,其預設對齊方式就是所有成員使用的對齊引數中最大的一個,s1的就是4。所以,成員d按4位元組對齊。成員e是8個位元組,預設按8位元組對齊,和指定的一樣,所以它對到8位元組的邊界上。這時,已經使用了12個位元組,所以又新增4個位元組的空,從第16個位元組開始放置成員e。此時長度為24,並可被8(成員e按8位元組對齊)整除。這樣,一共使用了24個位元組。
各個變數在記憶體中的佈局為:
c***aa**
bbbb****
dddddddd ——這種“矩陣寫法”很方便看出結構體實際大小!
因此,sizeof(S2)結果為24,a後面空了2個位元組接著是b。
這裡有三點很重要:
1) 每個成員分別按自己的方式對齊,並能最小化長度;
2) 複雜型別(如結構)的預設對齊方式是其最長的成員的對齊方式,這樣在成員是複雜型別時可以最小化長度;
3) 對齊後的長度必須是成員中最大對齊引數的整數倍,這樣在處理陣列時可保證每一項都邊界對齊。
還要注意,“空結構體”(不含資料成員)的大小為1,而不是0。試想如果不佔空間的話,一個空結構體變數如何取地址、兩個不同的空結構體變數又如何得以區分呢?
5.8.2 上海網宿科技面試題
假設硬體平臺是intel x86(little endian),以下程式輸出什麼:
1 //假設硬體平臺是intel x86(little endian)
2 typedef unsigned int uint32_t;
3 void inet_ntoa(uint32_t in){
4 char b[18];
5 register char *p;
6 p = (char *)∈
7 #define UC(b) (((int)b)&0xff) //byte轉換為無符號int型
8 sprintf(b, "%d.%d.%d.%d\n", UC(p[0]), UC(p[1]), UC(p[2]), UC(p[3]));
9 printf(b);
10 }
11 int main(void){
12 inet_ntoa(0x12345678);
13 inet_ntoa(0x87654321);
14 return 0;
15 }
先看如下程式:
1 int main(void){
2 int a = 0x12345678;
3 char *p = (char *)&a;
4 char str[20];
5 sprintf(str,"%d.%d.%d.%d\n", p[0], p[1], p[2], p[3]);
6 printf(str);
7 return 0;
8 }
按照小位元組序的規則,變數a在計算機中儲存方式為:
|
高地址方向 |
0x12 |
0x34 |
0x56 |
0x78 |
低地址方向 |
|
p[3] |
p[2] |
p[1] |
p[0] |
注意,p並不是指向0x12345678的開頭0x12,而是指向0x78。p[0]到p[1]的操作是&p[0]+1,因此p[1]地址比p[0]地址大。輸出結果為120.86.52.18。
反過來的話,令int a = 0x87654321,則輸出結果為33.67.101.-121。
為什麼有負值呢?因為系統預設的char是有符號的,本來是0x87也就是135,大於127因此就減去256得到-121。
想要得到正值的話只需將char *p = (char *)&a改為unsigned char *p = (unsigned char *)&a即可。
綜上不難得出,網宿面試題的答案為120.86.52.18和33.67.101.135。
再轉載一篇長度較短,但是寫的也比較好的。
首先我們先看看下面的C語言的結構體:
-
typedef struct MemAlign -
{ -
int a; -
char b[3]; -
int c; -
}MemAlign;
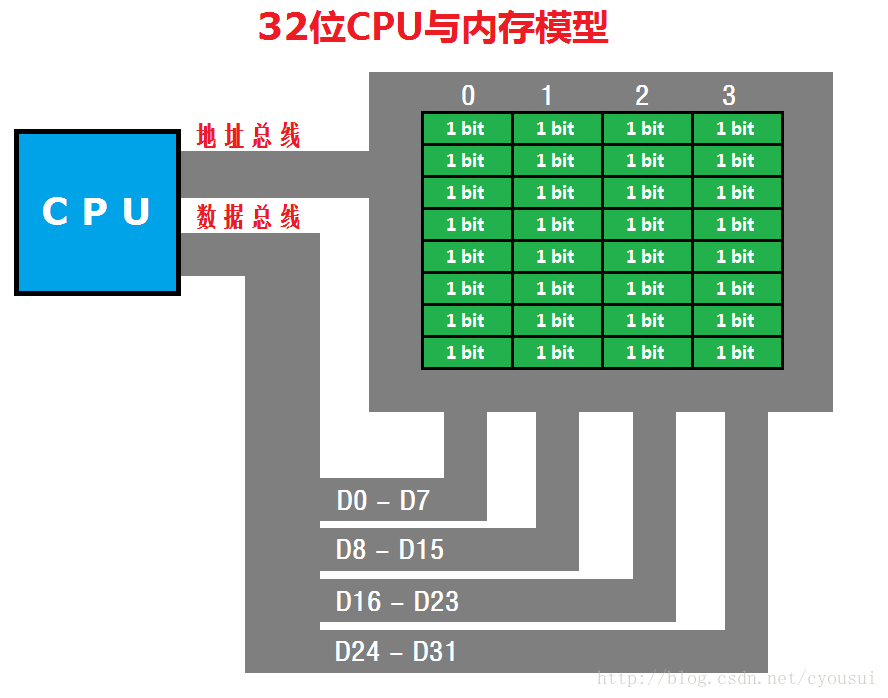
以上這個結構體佔用記憶體多少空間呢?也許你會說,這個簡單,計算每個型別的大小,將它們相加就行了,以32為平臺為例,int型別佔4字節,char佔用1字節,所以:4 + 3 + 4 = 11,那麼這個結構體一共佔用11字節空間。好吧,那麼我們就用實踐來證明是否正確,我們用sizeof運算子來求出這個結構體佔用記憶體空間大小,sizeof(MemAlign),出乎意料的是,結果居然為12?看來我們錯了?當然不是,而是這個結構體被優化了,這個優化有個另外一個名字叫“對齊”,那麼這個對齊到底做了什麼樣的優化呢,聽我慢慢解釋,再解釋之前我們先看一個圖,圖如下:
相信學過彙編的朋友都很熟悉這張圖,這張圖就是CPU與記憶體如何進行資料交換的模型,其中,左邊藍色的方框是CPU,右邊綠色的方框是記憶體,記憶體上面的0~3是記憶體地址。這裡我們這張圖是以32位C