
tf.flags與tf.app.flags
在看了眾多關於flags與app.flags的文獻後,理解程度還是有點迷茫。
1. import tensorflow as tf
2. FLAGS=tf.app.flags.FLAGS
3. tf.app.flags.DEFINE_float(
4. 'flag_float', 0.01, 'input a float')
5. tf.app.flags.DEFINE_integer(
6. 'flag_int', 400, 'input a int')
7. tf.app.flags.DEFINE_boolean(
8. 'flag_bool', True, 'input a bool'
9. tf.app.flags.DEFINE_string(
10. 'flag_string', 'yes', 'input a string')
11.Â
12. print(FLAGS.flag_float)
13. print(FLAGS.flag_int)
14. print(FLAGS.flag_bool)
15. print(FLAGS.flag_string)
1.在命令列中檢視幫助資訊,在命令列輸入 python test.py -h
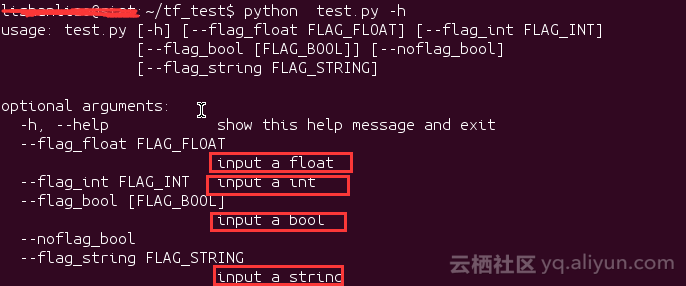
注意紅色框中的資訊,這個就是我們用DEFINE_XXX新增命令列引數時的第三個引數
2.直接執行test.py
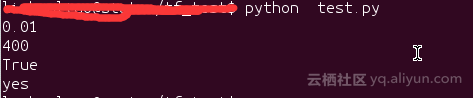
因為沒有給對應的命令列引數賦值,所以輸出的是命令列引數的預設值。
3.帶命令列引數的執行test.py檔案

這裡輸出了我們賦給命令列引數的值
tf.app.flags.DEFINE_xxx()就是新增命令列的optional argument(可選引數),
而tf.app.flags.FLAGS可以從對應的命令列引數取出引數。
DEFINE_string()限定了可選引數輸入必須是string,這也就是為什麼這個函式定義為DEFINE_string(),同理,DEFINE_int()限定可選引數必須是int,DEFINE_float()限定可選引數必須是float,DEFINE_boolean()限定可選引數必須是bool。
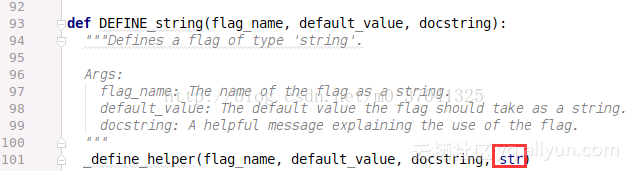
最關鍵的一步,這裡定義了_FlagValues這個類的一個例項,這樣的這樣當要訪問命令列輸入的命令時,就能使用像tf.app.flag.Flags這樣的操作。

從:使用CNN做英文文字任務例項來看flags用法
import tensorflow as tfimport numpy as npimport osimport timeimport datetimeimport data_helpersfrom text_cnn import TextCNNfrom tensorflow.contrib import learn
# Parameters# ==================================================
# Data loading params# 語料檔案路徑定義
tf.flags.DEFINE_float("dev_sample_percentage", .1, "Percentage of the training data to use for validation")
tf.flags.DEFINE_string("positive_data_file", "./data/rt-polaritydata/rt-polarity.pos", "Data source for the positive data.")
tf.flags.DEFINE_string("negative_data_file", "./data/rt-polaritydata/rt-polarity.neg", "Data source for the negative data.")
# Model Hyperparameters# 定義網路超引數
tf.flags.DEFINE_integer("embedding_dim", 128, "Dimensionality of character embedding (default: 128)")
tf.flags.DEFINE_string("filter_sizes", "3,4,5", "Comma-separated filter sizes (default: '3,4,5')")
tf.flags.DEFINE_integer("num_filters", 128, "Number of filters per filter size (default: 128)")
tf.flags.DEFINE_float("dropout_keep_prob", 0.5, "Dropout keep probability (default: 0.5)")
tf.flags.DEFINE_float("l2_reg_lambda", 0.0, "L2 regularization lambda (default: 0.0)")
# Training parameters# 訓練引數
tf.flags.DEFINE_integer("batch_size", 32, "Batch Size (default: 32)")
tf.flags.DEFINE_integer("num_epochs", 200, "Number of training epochs (default: 200)") # 總訓練次數
tf.flags.DEFINE_integer("evaluate_every", 100, "Evaluate model on dev set after this many steps (default: 100)") # 每訓練100次測試一下
tf.flags.DEFINE_integer("checkpoint_every", 100, "Save model after this many steps (default: 100)") # 儲存一次模型
tf.flags.DEFINE_integer("num_checkpoints", 5, "Number of checkpoints to store (default: 5)")# Misc Parameters
tf.flags.DEFINE_boolean("allow_soft_placement", True, "Allow device soft device placement") # 加上一個布林型別的引數,要不要自動分配
tf.flags.DEFINE_boolean("log_device_placement", False, "Log placement of ops on devices") # 加上一個布林型別的引數,要不要列印日誌
# 列印一下相關初始引數
FLAGS = tf.flags.FLAGS
FLAGS._parse_flags()
print("\nParameters:")for attr, value in sorted(FLAGS.__flags.items()):
print("{}={}".format(attr.upper(), value))
print("")
# Data Preparation# ==================================================
# Load data
print("Loading data...")
x_text, y = data_helpers.load_data_and_labels(FLAGS.positive_data_file, FLAGS.negative_data_file)
# Build vocabulary
max_document_length = max([len(x.split(" ")) for x in x_text]) # 計算最長郵件
vocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length) # tensorflow提供的工具,將資料填充為最大長度,預設0填充
x = np.array(list(vocab_processor.fit_transform(x_text)))
# Randomly shuffle data# 資料洗牌
np.random.seed(10)# np.arange生成隨機序列
shuffle_indices = np.random.permutation(np.arange(len(y)))
x_shuffled = x[shuffle_indices]
y_shuffled = y[shuffle_indices]
# 將資料按訓練train和測試dev分塊# Split train/test set# TODO: This is very crude, should use cross-validation
dev_sample_index = -1 * int(FLAGS.dev_sample_percentage * float(len(y)))
x_train, x_dev = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]
y_train, y_dev = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:]
print("Vocabulary Size: {:d}".format(len(vocab_processor.vocabulary_)))
print("Train/Dev split: {:d}/{:d}".format(len(y_train), len(y_dev))) # 列印切分的比例
# Training# ==================================================
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=FLAGS.allow_soft_placement,
log_device_placement=FLAGS.log_device_placement)
sess = tf.Session(config=session_conf)
with sess.as_default():
# 卷積池化網路匯入
cnn = TextCNN(
sequence_length=x_train.shape[1],
num_classes=y_train.shape[1], # 分幾類
vocab_size=len(vocab_processor.vocabulary_),
embedding_size=FLAGS.embedding_dim,
filter_sizes=list(map(int, FLAGS.filter_sizes.split(","))), # 上面定義的filter_sizes拿過來,"3,4,5"按","分割
num_filters=FLAGS.num_filters, # 一共有幾個filter
l2_reg_lambda=FLAGS.l2_reg_lambda) # l2正則化項
# Define Training procedure
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(1e-3) # 定義優化器
grads_and_vars = optimizer.compute_gradients(cnn.loss)
train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step)
# Keep track of gradient values and sparsity (optional)
grad_summaries = []
for g, v in grads_and_vars:
if g isnotNone:
grad_hist_summary = tf.summary.histogram("{}/grad/hist".format(v.name), g)
sparsity_summary = tf.summary.scalar("{}/grad/sparsity".format(v.name), tf.nn.zero_fraction(g))
grad_summaries.append(grad_hist_summary)
grad_summaries.append(sparsity_summary)
grad_summaries_merged = tf.summary.merge(grad_summaries)
# Output directory for models and summaries
timestamp = str(int(time.time()))
out_dir = os.path.abspath(os.path.join(os.path.curdir, "runs", timestamp))
print("Writing to {}\n".format(out_dir))
# Summaries for loss and accuracy
# 損失函式和準確率的引數儲存
loss_summary = tf.summary.scalar("loss", cnn.loss)
acc_summary = tf.summary.scalar("accuracy", cnn.accuracy)
# Train Summaries
# 訓練資料儲存
train_summary_op = tf.summary.merge([loss_summary, acc_summary, grad_summaries_merged])
train_summary_dir = os.path.join(out_dir, "summaries", "train")
train_summary_writer = tf.summary.FileWriter(train_summary_dir, sess.graph)
# Dev summaries
# 測試資料儲存