
詳解Attention機制及Tensorflow之attention_wrapper
0 - 前言
近期想基於tensorflow開發一套翻譯模型,無奈網上關於tensorflow及其attention相關介面更多的是使用,對其內部的具體實現機理卻較少提及,故寫此部落格一探attention_wrapper之究竟,希望對同樣需要的朋友有些幫助,如有錯誤,煩請指正。
Google的工程師們為了讓程式碼結構更安全、準確、完整、通用,在原始碼中加入了較多的判斷等相關輔助程式碼,這在一定程度上增加了理解難度,但程式碼質量很高,閱讀原始碼,受益良多!
1 - Attention mechanism
基本的seq2seq模型由encoder、decoder組成,由encoder將輸入編碼為固定大小的final state,再由decoder將final state解碼。其缺點顯而易見,即在編碼過程中,存在資訊損失,這在解決長序列問題時尤為突出。Attention機制應運而生,並得到迅速推廣應用。2014年,Bahdanau等人在論文《Neural Machine Translation by Jointly Learning to Align and Translate》中,詳述了attention 機制,並應用到機器翻譯中。
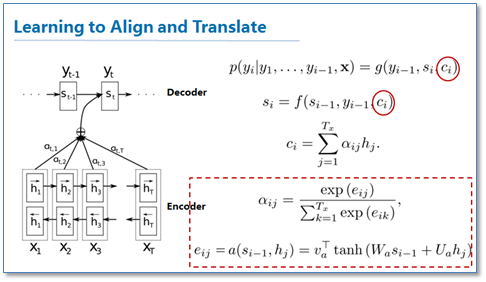
圖1: Attention model 1
來源: https://www.cnblogs.com/robert-dlut/p/5952032.html
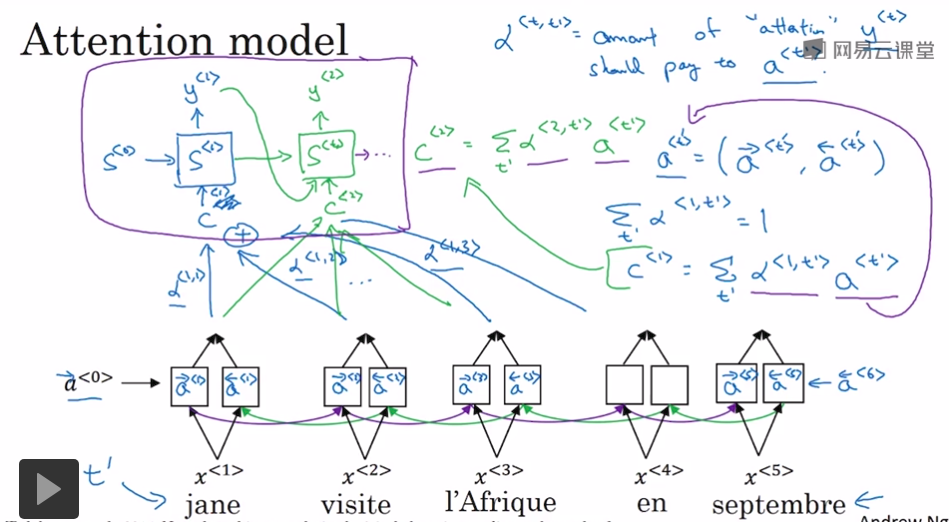
圖2: Attention model 2
來源:吳恩達老師deeplearning.ai課程
如圖1圖2描述,解碼器在解碼過程中不使用資訊損失較大的final state,而是把encoder每個編碼單元的輸出都“看”一遍,讓模型自己學習如何分配“注意力”,即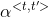
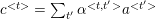
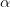
2 - attention_wrapper.py
講解程式碼前,先將容易引起誤解的變數含義說明一下:
- memory: “記憶”,指encoder的outputs
- query: decoder當前cell的輸入隱藏狀態,決定讀取memory的哪些部分
1) Attention mechanism: 用來實現計算不同型別的attention vector(即context加權和後的向量),包括:
a. class _BaseAttentionMechanism: 所有attention的基類
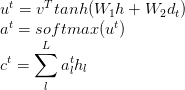
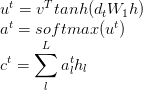
d._BaseMonotonicAttentionMechanism,BahdanauMonotonicAttention,
3) AttentionWrapper: 將rnn cell與上述attention mechanism封裝在一起,從而構建一個帶有attention機制的Decoder
4) 公用方法
3 - class AttentionWrapper
接下來,以BahdanauAttention為例,採用順敘與插敘方式,以class AttentionWrapper為起點進行詳述:
def __init__(self, cell, attention_mechanism, attention_layer_size=None, alignment_history=False, cell_input_fn=None, output_attention=True, initial_cell_state=None, name=None):
- cell: rnn cell例項,可以是單個cell,也可以是多個cell stack後的mutli layer rnn
- attention_mechanism: 上述的attention mechanism的例項,此處以BahdanauAttention為例
- attention_layer_size: 用來控制我們最後生成的attention是怎麼得來的,如果是None,則直接返回對應attention mechanism計算得到的加權和向量;如果不是None,則在呼叫_compute_attention方法時,得到的加權和向量還會與output進行concat,然後再經過一個線性對映,變成維度為attention_layer_size的向量
- alignment_history: 主要用於後期的視覺化,如果為真,則輸出state中alignment_history為TensorArray,記錄每個時刻的alignment
- cell_input_fn: input送入decoder cell的方式,預設是會將input和上一步計算得到的attention拼接起來送入decoder cell
- output_attention: 是否返回attention,如果為False則直接返回rnn cell的輸出,注意,無論是否為True,每一個時間步的attention都會儲存在AttentionWrapperState的一個例項中
- initial_cell_state: 初始狀態,此時如果傳入,需確保其batch_size與成員函式zero_state所需的引數一致
def __init__(self, cell, attention_mechanism, attention_layer_size=None, alignment_history=False, cell_input_fn=None, output_attention=True, initial_cell_state=None, name=None): super(AttentionWrapper, self).__init__(name=name) if not rnn_cell_impl._like_rnncell(cell): # pylint: disable=protected-access raise TypeError( "cell must be an RNNCell, saw type: %s" % type(cell).__name__) if isinstance(attention_mechanism, (list, tuple)): self._is_multi = True attention_mechanisms = attention_mechanism for attention_mechanism in attention_mechanisms: if not isinstance(attention_mechanism, AttentionMechanism): raise TypeError( "attention_mechanism must contain only instances of " "AttentionMechanism, saw type: %s" % type(attention_mechanism).__name__)else: # 此處只考慮self._is_multi為False的情況,即單個attention_mechanismself._is_multi = False if not isinstance(attention_mechanism, AttentionMechanism): raise TypeError( "attention_mechanism must be an AttentionMechanism or list of " "multiple AttentionMechanism instances, saw type: %s" % type(attention_mechanism).__name__) attention_mechanisms = (attention_mechanism,) # cell_input_fn預設將attention與input沿最後一維聯結,返回當前cell的輸入,此處可根據需要對 # lambda函式進行修改,如lambda inputs, attention: attentionif cell_input_fn is None: cell_input_fn = ( lambda inputs, attention: array_ops.concat([inputs, attention], -1)) else: if not callable(cell_input_fn): raise TypeError( "cell_input_fn must be callable, saw type: %s" % type(cell_input_fn).__name__)# attention_layer_size不為None時,以該值為引數定義Dense layer,並作為函式_compute_attention # 的引數,詳見_compute_attention函式if attention_layer_size is not None: attention_layer_sizes = tuple( attention_layer_size if isinstance(attention_layer_size, (list, tuple)) else (attention_layer_size,)) if len(attention_layer_sizes) != len(attention_mechanisms): raise ValueError( "If provided, attention_layer_size must contain exactly one " "integer per attention_mechanism, saw: %d vs %d" % (len(attention_layer_sizes), len(attention_mechanisms)))self._attention_layers = tuple( layers_core.Dense( attention_layer_size, name="attention_layer", use_bias=False) for attention_layer_size in attention_layer_sizes) self._attention_layer_size = sum(attention_layer_sizes) else: self._attention_layers = None self._attention_layer_size = sum( attention_mechanism.values.get_shape()[-1].value for attention_mechanism in attention_mechanisms) self._cell = cell self._attention_mechanisms = attention_mechanisms self._cell_input_fn = cell_input_fn self._output_attention = output_attention self._alignment_history = alignment_history # 如果initial_cell_state為None,則在呼叫成員函式zero_state時進行初始化,如果不為None, # 需確保與zero_state的引數batch_size匹配with ops.name_scope(name, "AttentionWrapperInit"): if initial_cell_state is None: self._initial_cell_state = None else: final_state_tensor = nest.flatten(initial_cell_state)[-1] state_batch_size = ( final_state_tensor.shape[0].value or array_ops.shape(final_state_tensor)[0]) error_message = ( "When constructing AttentionWrapper %s: " % self._base_name + "Non-matching batch sizes between the memory " "(encoder output) and initial_cell_state. Are you using " "the BeamSearchDecoder? You may need to tile your initial state " "via the tf.contrib.seq2seq.tile_batch function with argument " "multiple=beam_width.") with ops.control_dependencies( self._batch_size_checks(state_batch_size, error_message)): self._initial_cell_state = nest.map_structure( lambda s: array_ops.identity(s, name="check_initial_cell_state"), initial_cell_state)
def zero_state(self, batch_size, dtype): with ops.name_scope(type(self).__name__ + "ZeroState", values=[batch_size]): if self._initial_cell_state is not None: cell_state = self._initial_cell_state else: cell_state = self._cell.zero_state(batch_size, dtype) error_message = ( "When calling zero_state of AttentionWrapper %s: " % self._base_name + "Non-matching batch sizes between the memory " "(encoder output) and the requested batch size. Are you using " "the BeamSearchDecoder? If so, make sure your encoder output has " "been tiled to beam_width via tf.contrib.seq2seq.tile_batch, and " "the batch_size= argument passed to zero_state is " "batch_size * beam_width.") with ops.control_dependencies( self._batch_size_checks(batch_size, error_message)): cell_state = nest.map_structure( lambda s: array_ops.identity(s, name="checked_cell_state"), cell_state) return AttentionWrapperState( cell_state=cell_state, time=array_ops.zeros([], dtype=dtypes.int32), attention=_zero_state_tensors(self._attention_layer_size, batch_size, dtype), alignments=self._item_or_tuple( attention_mechanism.initial_alignments(batch_size, dtype) for attention_mechanism in self._attention_mechanisms), alignment_history=self._item_or_tuple( tensor_array_ops.TensorArray(dtype=dtype, size=0, dynamic_size=True) if self._alignment_history else () for _ in self._attention_mechanisms))
zero_state: 返回AttentionWrapperState例項,作為初始引數
def call(self, inputs, state): """Perform a step of attention-wrapped RNN. - Step 1: Mix the `inputs` and previous step's `attention` output via `cell_input_fn`. - Step 2: Call the wrapped `cell` with this input and its previous state. - Step 3: Score the cell's output with `attention_mechanism`. - Step 4: Calculate the alignments by passing the score through the `normalizer`. - Step 5: Calculate the context vector as the inner product between the alignments and the attention_mechanism's values (memory). - Step 6: Calculate the attention output by concatenating the cell output and context through the attention layer (a linear layer with `attention_layer_size` outputs). Args: inputs: (Possibly nested tuple of) Tensor, the input at this time step. state: An instance of `AttentionWrapperState` containing tensors from the previous time step. Returns: A tuple `(attention_or_cell_output, next_state)`, where: - `attention_or_cell_output` depending on `output_attention`. - `next_state` is an instance of `AttentionWrapperState` containing the state calculated at this time step. Raises: TypeError: If `state` is not an instance of `AttentionWrapperState`. """ if not isinstance(state, AttentionWrapperState): raise TypeError("Expected state to be instance of AttentionWrapperState. " "Received type %s instead." % type(state))# Step 1: 呼叫self._cell_input_fn函式,求取cell_inputscell_inputs = self._cell_input_fn(inputs, state.attention) cell_state = state.cell_state # Step 2: 呼叫self._cell,求取當前cell的cell_output, next_cell_statecell_output, next_cell_state = self._cell(cell_inputs, cell_state) cell_batch_size = ( cell_output.shape[0].value or array_ops.shape(cell_output)[0]) error_message = ( "When applying AttentionWrapper %s: " % self.name + "Non-matching batch sizes between the memory " "(encoder output) and the query (decoder output). Are you using " "the BeamSearchDecoder? You may need to tile your memory input via " "the tf.contrib.seq2seq.tile_batch function with argument " "multiple=beam_width.") with ops.control_dependencies( self._batch_size_checks(cell_batch_size, error_message)): cell_output = array_ops.identity( cell_output, name="checked_cell_output")if self._is_multi: previous_alignments = state.alignments previous_alignment_history = state.alignment_history else: previous_alignments = [state.alignments] previous_alignment_history = [state.alignment_history] all_alignments = [] all_attentions = [] all_histories = [] # Step 3: 計算當前cell的attention、alignments,詳見下文for i, attention_mechanism in enumerate(self._attention_mechanisms): attention, alignments = _compute_attention( attention_mechanism, cell_output, previous_alignments[i], self._attention_layers[i] if self._attention_layers else None) alignment_history = previous_alignment_history[i].write( state.time, alignments) if self._alignment_history else () all_alignments.append(alignments) all_histories.append(alignment_history) all_attentions.append(attention) attention = array_ops.concat(all_attentions, 1) next_state = AttentionWrapperState( time=state.time + 1, cell_state=next_cell_state, attention=attention, alignments=self._item_or_tuple(all_alignments), alignment_history=self._item_or_tuple(all_histories)) # attention返回與否,都會儲存在next_state中if self._output_attention: return attention, next_state else: return cell_output, next_state
def _compute_attention(attention_mechanism, cell_output, previous_alignments, attention_layer): """Computes the attention and alignments for a given attention_mechanism.""" # Step 3.1: 計算normalized alignments,shape [batch_size, memory_time],詳見下文alignments = attention_mechanism( cell_output, previous_alignments=previous_alignments) # Step 3.2: 計算attention# Reshape from [batch_size, memory_time] to [batch_size, 1, memory_time]expanded_alignments = array_ops.expand_dims(alignments, 1) # Context is the inner product of alignments and values along the # memory time dimension. # alignments shape: [batch_size, 1, memory_time] # attention_mechanism.values shape is # [batch_size, memory_time, attention_mechanism.num_units] # the batched matmul is over memory_time, so the output shape is # [batch_size, 1, attention_mechanism.num_units]. # we then squeeze out the singleton dim.context = math_ops.matmul(expanded_alignments, attention_mechanism.values) context = array_ops.squeeze(context, [1]) # context為真正的attention,如果在構造AttentionWrapper時傳入attention_layer_size, # 內部以此構造attention_layer(Dense layer),將cell_output、context聯接作為輸入, # 則輸出attention的shape: [batch_size, attention_layer_size]if attention_layer is not None: attention = attention_layer(array_ops.concat([cell_output, context], 1)) else: attention相關推薦
詳解Attention機制及Tensorflow之attention_wrapper
0 - 前言 近期想基於tensorflow開發一套翻譯模型,無奈網上關於tensorflow及其attention相關介面更多的是使用,對其內部的具體實現機理卻較少提及,故寫此部落格一探attention_wrapper之究竟,希望對同樣需要的朋友有些幫助,如有
Android 學習之《第一行程式碼》第二版 筆記(十一)詳解廣播機制(一)
一、廣播機制簡介 1. 四大元件之一 2. Android 提供了一套完整的API,允許應用程式自由地傳送和接收廣播。 A. 傳送廣播藉助Intent B. 接收廣播藉助廣播接收器(Broadcast Receiver) 3. 廣播型別: A. 標準廣播: 完全非同步執行
Android 學習之《第一行程式碼》第二版 筆記(十二)詳解廣播機制(二)
廣播的最佳實踐——實現強制下線功能 思路:在介面上彈出一個對話方塊,讓使用者無法進行任何操作,必須點選對話方塊中的確定按鈕,然後回到登入介面即可。 一、效果圖 1. 登入介面並輸入賬號密碼 2. 登陸後的介面 3. 強制下線 4. 退回登陸的介面
JAVAWEB開發之Lucene詳解——Lucene入門及使用場景、全文檢索、索引CRUD、優化索引庫、分詞器、高亮、相關度排序、各種查詢
Lucene入門 應用場景 windows系統中的有搜尋功能:開啟“我的電腦”,按“F3”就可以使用查詢的功能,查詢指定的檔案或資料夾。搜尋的範圍是整個電腦中的檔案資源。 Eclipse中的幫助子系統:點選Help->Help Contents,可以查找出相關的幫助資
python子進程模塊subprocess詳解與應用實例 之三
app 命令執行 windows rom not tput 一個 網絡 shell命令 二、應用實例解析 2.1 subprocess模塊的使用 1. subprocess.call >>> subprocess.call(["ls", "-l"]) 0
EJB2.0教程 詳解EJB技術及實現原理
tee nsa 普通 事情 println 配置 ransac 教程 聲明 EJB是什麽呢?EJB是一個J2EE體系中的組件.再簡單的說它是一個能夠遠程調用的javaBean.它同普通的javaBean有兩點不同.第一點,就是遠程調用.第二點,就是事務的功能,我們在EJB中
JDBC詳解系列(二)之加載驅動
red mar mys ons try path 替換 host man ---[來自我的CSDN博客](http://blog.csdn.net/weixin_37139197/article/details/78838091)--- ??在JDBC詳解系列(一)之流程中
TCP/IP詳解V2(一)之UDP協議
listen point reflect con 協議 提取 高級數據結構 don size UDP UDP是一個面向數據報的簡單運輸層協議。 數據結構 struct udphdr { u_short uh_sport; //源端口 u_shor
詳解AMD規範及具體實現requireJS在工程中的使用
當前頁 eid 資源 自己 一個數 中比 ocs 網站 重定位 由CommonJS組織提出了許多新的JavaScript架構方案和標準,希望能為前端開發提供統一的指引。AMD規範就是其中比較著名一個,全稱是Asynchronous Module Definition
《第一行程式碼Android》學習總結第五章 詳解廣播機制
一、廣播機制簡介 Android提供了一系列API,允許程式自由的傳送和接收廣播,同時每個程式都可以對自己感興趣的廣播進行註冊,該程式便可以只接受來自於系統或其他應用程式的自己關心的廣播內容。 標準廣播:
Java併發(十八):阻塞佇列BlockingQueue BlockingQueue(阻塞佇列)詳解 二叉堆(一)之 圖文解析 和 C語言的實現 多執行緒程式設計:阻塞、併發佇列的使用總結 Java併發程式設計:阻塞佇列 java阻塞佇列 BlockingQueue(阻塞佇列)詳解
阻塞佇列(BlockingQueue)是一個支援兩個附加操作的佇列。 這兩個附加的操作是:在佇列為空時,獲取元素的執行緒會等待佇列變為非空。當佇列滿時,儲存元素的執行緒會等待佇列可用。 阻塞佇列常用於生產者和消費者的場景,生產者是往佇列裡新增元素的執行緒,消費者是從佇列裡拿元素的執行緒。阻塞佇列就是生產者
【python】詳解map函式的用法之函式並行作用解析
Python函式程式設計中的map(func, seq1[, seq2,…]) 函式是將func作用於seq中的每一個元素,其中seq須是可迭代物件,並將所有的呼叫的結果作為一個list返回。如果func為None,作用同zip()。 本文參考自:Python中map()函式淺析一文,感謝精彩分享。 下面
詳解廣播機制
廣播的型別 廣播型別分為有序廣播和標準廣播。標準廣播是一種完全非同步執行的廣播,在廣播發出之後,所有的廣播接收器幾乎在同一時間接收到這條廣播資訊,沒有先後順序可言,無法被截斷。有序廣播是同步執行的廣播,同一時間只有一個廣播接收器可以接收這條訊息,只有當廣播接收器中的邏輯執行完畢,廣播才能
Java-API-Class類詳解、用法及泛化
Java-API-Class類詳解、用法及泛化 轉載宣告: 本文系轉載自以下文章: Java中Class類詳解、用法及泛化 作者: 老白講網際網路 轉載僅為方便學習檢視,一切權利屬於原作者,本人只是做了整理和排版,如果帶來不便請聯絡我刪除。 0x01 摘要
【詳解JavaScript系列】JavaScript之流程語句
一 開篇概述 本講主要講解JavaScript流程語句,其大致內容包括如下: 其中,常用的if,while,do..while,for在本片文章就不論述,重點論述for..in..,label,break和continue,whth,switch等語句 二 內容區 (一)常用語句 由於如下
【詳解JavaScript系列】JavaScript之變數
一 概述 本篇文章將講解JavaScript中的變數,大致內容歸結為: 1.變數定義 包括變數宣告和變數初始化 2.變數種類 包括區域性變數和全域性變數 3.變數鏈式作用域及訪問 二 內容 (一)變數定義 在JavaScript程式語言中,變數的定義是通過
機器學習中L1L2規則化詳解(先驗及稀疏性解釋)
(作者:陳玓玏) 1、 為什麼要正則化? 知乎上有個兄弟說得對(https://www.zhihu.com/question/20924039 這個問題下Stark Einstein的回答),不應該說是正則化,應該說是規則化,也就是說,我們原來是在完全沒有任何先
ASP.NET Core微服務 on K8S(Jessetalk)(第一章:詳解基本物件及服務發現)(持續更新)
課程連結:http://video.jessetalk.cn/course/explore 良心課程,大家一起來學習哈! 任務1:課程介紹 任務2:Labels and Selectors 所有資源物件(包括Pod, Service, Namespace, Volume)都可以打
史上最簡單MySQL教程詳解(基礎篇)之多表聯合查詢
常用術語 內連線 外連線 左外連線 右外連線 注意事項: 自連線 子查詢 在上篇文章史上最簡單MySQL教程詳解(基礎篇)之資料庫設計正規化及應用舉例我們介紹過,在關係型資料庫中,我們通常為了減少資料的冗餘量將對資料表進行規範,將
z-index使用詳解元素重疊及position定位
z-index使用詳解,JavaScript教程網為您講解如何使用 CSS 的 z-index 屬性,淺析CSS——元素重疊及position定位的z-index順序。 2012040114074097.jpg (50.8 KB, 下載次數: 0) 下載附件 7