
Python 與 Tensorflow 簡介
一. Python 的安裝
1. Window 平臺安裝 Python
- 在下載列表中選擇Window平臺安裝包,包格式為:
python-XYZ.msi檔案 , XYZ 為你要安裝的版本號。 - 下載後,雙擊下載包,進入Python安裝嚮導,安裝非常簡單,你只需要使用預設的設定一直點選”下一步”直到安裝完成即可。
- 環境變數設定:在命令列框中 (cmd) 輸入:
path=%path%;C:\Python,按下enter
2. Linux 建立多版本 Python 環境
- 安裝 Anaconda: 在shell命令列輸入
bash Anaconda2-5.0.0.1-Linux-x86_64.sh,一直按enter 和 yes直至結束 - 建立linux python 3環境:
conda create -n py35(環境名稱) python=3.5 (python版本) - 新增路徑到
.bashrc檔案:
export PATH="/home/hansry/anaconda2/bin:$PATH" #其中 /home/hansry/anaconda2 為安裝包的路徑
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-8.0/bin:$PATH- 1
- 2
- 3
5.啟用環境: source activate py35 ,直至出現使用者名稱前面有 (py35) 字樣則安裝成功。如下圖所示:

二.Python 的使用
1. 互動式直譯器
$ python # Unix/Linux
或者
C:>python # Windows/DOS- 1
- 2
- 3
2. 命令列指令碼
$ python script.py # Unix/Linux
或者
C:>python script.py # Windows/DOS - 1
- 2
- 3
3. 整合開發環境(IDE: Integrated Development Environment): PyCharm , Spyder

三. Python 的基本語法
1. 行和縮排
學習 Python 與其他語言最大的區別就是,Python 的程式碼塊不使用大括號 {} 來控制類,函式以及其他邏輯判斷。python 最具特色的就是用縮排來寫模組。
縮排的空白數量是可變的,但是所有程式碼塊語句必須包含相同的縮排空白數量,這個必須嚴格執行。如下所示:
if True: if(true){
print "True" cout<<"True"<<endl;}
else: else{
print "False" cout<<"False"<<endl;}- 1
- 2
- 3
- 4
以下程式碼將會執行錯誤:
if True:
print "Answer"
print "True"
else:
print "Answer"
# 沒有嚴格縮排,在執行時會報錯
print "False"- 1
- 2
- 3
- 4
- 5
- 6
- 7
如果出現IndentationError: unexpected indent 則說明沒有對齊,格式出錯,python 對格式要求非常嚴格
2.常見的迴圈條件語句
1) while 迴圈語句:
count = 0 count=0
while (count < 9): while(count<9){
print('The count is:', count) cout<<'The count is:'<<count<<endl;
count = count + 1 count=count+1
}
print "Good bye!" cout<<"Good bye"<<endl;- 1
- 2
- 3
- 4
- 5
- 6
2) 條件語句:
flag = False
name = 'luren'
if name == 'python': # 判斷變數否為'python'
flag = True # 條件成立時設定標誌為真
print 'welcome boss' # 並輸出歡迎資訊
else:
print name # 條件不成立時輸出變數名稱- 1
- 2
- 3
- 4
- 5
- 6
- 7
3) for 迴圈語句
for i in range(10):
print(i)- 1
- 2
0
1
2
3
4
5
6
7
8
9- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3. Python 識別符號
在python 裡,識別符號由字母、數字、下劃線組成。
在 python中,所有識別符號可以包括英文、數字以及下劃線(_),但是不能以數字開頭。
Python 中的識別符號是區分大小寫的。
以下劃線開頭的識別符號是有特殊意義的。以單下劃線開頭 _foo 的代表不能直接訪問的類屬性,需通過類提供的介面進行訪問,不能用 from xxx import * 而匯入;
以雙下劃線開頭的 _foo 代表類的私有成員;以雙下劃線開頭和結尾的 __foo_ 代表 Python 裡特殊方法專用的標識,如 init() 代表類的建構函式。
4.Python 模組的使用
Test1.py
class hello_world: #類
def __init(self):pass
def f(self):print('Hello, World!')
def vision(): #函式
print('machine vision')
if __name__=='__main__':
hello_world().f()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1). 若在shell視窗直接執行 python Test1,得到:
Hello, World!- 1
因為此時__name__== '__main__' 成立,所以直接執行 hello_world().f()
2). 若是直接在 shell 視窗直接執行 import Test1,則此時 Test1 會被當做一個物件來使用,而不會執行到hello_world().f()
>>> import Test1
>>> Test1.__name__
'Test1'- 1
- 2
- 3
- 4
若寫另一檔案 Test2.py:
import Test1
Test1.vision()- 1
- 2
執行 Test2.py 檔案,可得:
>>> python Test2.py
machine vision- 1
- 2
- 3
因此,python檔案既可以當做執行檔案來使用,也可以當做物件來使用,這一點和 MALATB 十分相似。
5.Python 的類和例項
1). 在面向物件中,最重要的概念就是類(class)和例項(instance),類是抽象的模板,而例項是根據類創建出來的一個個具體的 “物件”。
學生是個較為抽象的概念,同時擁有很多屬性,可以用一個 Student 類來描述,類中可定義學生的分數、身高等屬性,但是沒有具體的數值。
而例項是類建立的一個個具體的物件, 每一個物件都從類中繼承有相同的方法,但是屬性值可能不同,如建立一個例項叫 hansry 的學生,其分數為 93,身高為 174,則這個例項擁有具體的數值。
class Student(object):
def __init__(self,name,score):
self.name=name
self.score=score- 1
- 2
- 3
- 4
a.(object)表示的是該類從哪個類繼承下來的,而object類是每個類都會繼承的一個類。
b. __init__ 方法的第一引數永遠是 self,用來表示類建立的例項本身,因此,在 __init__ 方法內部,就可以把各種屬性繫結到self,因為self 本身就是指向建立的例項本身。(C++ this 指標)
c. 有了 __init__ 方法後,在建立例項的時候,就不能傳入空引數,必須傳入與 __init__ 方法匹配的引數,但self本身不需要傳入引數,只需要傳入 self 後面的引數即可。
2). 例項: 定義好了類後,就可以通過Student類創建出 Student 的例項,建立例項是通過 類名 + ()實現:
student = Student('hansry', 93)
>>> student.name
'hansry'
>>> student.score
93- 1
- 2
- 3
- 4
- 5
- 6
a. 其中 Student 是類名稱,(’name’,93)為要傳入的引數
b. self.name 就是 Student類的屬性變數,為 Student 類所有。同時, name 是外部傳來的引數,不是 Student 類所自帶的。故 self.name = name 的意思就是把外部傳來的引數 name 的值賦值給 Student類自己的屬性變數 self.name .
c. 和普通函式相比,在類中定義函式只有一點不同,就是第一引數永遠是類的本身例項變數 self, 並且呼叫時,不用傳遞該引數。 除此之外,類的方法(函式)和普通函式沒有啥區別。既可以用 預設引數、可變引數或者關鍵字引數等。
3). 限制外部對類例項屬性的訪問
如果不想讓例項中的內部屬性被外部屬性訪問,則把 name 和 score 變成 __name 和 __score 即可,如下程式碼所示:
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_property(self):
print "%s: %d" %(self.__name,self.__score)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
>>> student= Student("hansry",99)
>>> student.print_property()
>>> student.__name()
hansry:99
Traceback (most recent call last):
AttributeError: 'Student' object has no attribute '__name'- 1
- 2
- 3
- 4
- 5
- 6
- 7
4). 開 API 使得外部程式碼能夠訪問到裡面的屬性,並且對其進行修改
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_property(self):
print "%s: %d" %(self.__name,self.__score)
def reset_name(self,change_name):
self.__name = change_name
def reset_score(self, change_score):
self.__score = change_score - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
student= Student("hansry",99)
student.print_property()
hansry:99
student.reset_name("simona")
student.reset_score(91)
student.print_property()
simona:91- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5). self 的仔細用法
A. self代表類的例項,而非類。
class Student(object):
def print_self(self):
print(self)
print(self.__class__)- 1
- 2
- 3
- 4
student=Student()
student.print_self()
<__main__.Student object at 0x7fd9095aed90>
<class '__main__.Student'>- 1
- 2
- 3
- 4
- 5
從上面例子可得,self代表的只是類的例項,而 self.class 才是類。
B. 定義類的時候,self最好寫上,因為它代表了類的例項。
四. Tensorflow 的安裝
1. Tensorflow 在 windows 的安裝和執行
1) 安裝docker: 首先要安裝 docker,就是類似於給你提供一個類似於linux的視窗,具體見官網的文件或者百度。到 docker 官網下載 Docker Toolbox,下載的版本可以為 DockerToolbox-1.10.2(備註:如果在window7 下安裝沒成功的就換 window 8或者 window 10), 然後安裝方法參照docker官網或者百度,這個比較簡單。
2) 安裝 tensorflow,進入tensorflow官網,版本選擇 0.6.0。DockerToolbox (即上面的軟體) 裝好之後,桌面會有個Docker Quickstart Terminal 的快捷鍵 
docker run -it b.gcr.io/tensorflow/tensorflow- 1
回車後就會自動下載,保持網速良好,可能會等比較長時間,下載完成後會有:
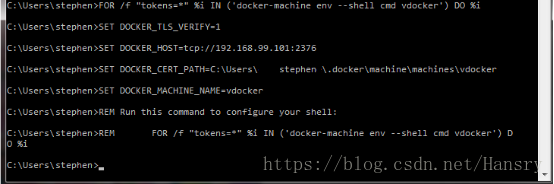
3) 等上述下載結束後,開啟windows命令提示符 (cmd),輸入以下命令:
FOR /f "tokens=*" %i IN ('docker-machine env --shell cmd default') DO %i- 1
執行成功後如下圖所示:
4) 回到 Docker Quickstart Terminal,輸入以下命令:
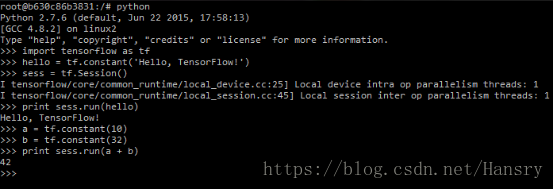
docker run -it b.gcr.io/tensorflow/tensorflow-full- 1
待下載完成後,系統會自動進入linux shell,輸入python,開始你的tensorflow之旅吧,如下圖:
2. Tensorflow 在 linux 下 的安裝和執行
在上述中已經提到如何安裝anaconda,當安裝成功後,安裝tensorflow就顯得容易很多:
1) source activate py35 啟用anaconda環境
2) conda install tensorflow 直接安裝tensorflow- 1
- 2
五. Tensorflow 的基本介紹
1. 為什麼要學 Tensorflow ?
Tensorflow 支援異構裝置分散式計算。
異構裝置: 指CPU、GPU 等核心進行有效地協同合作。與只依靠CPU相比,效能更高,功耗更低。
分散式: 分散式架構的目的在於幫助我們排程和分配計算資源, 使得上千萬、上億資料量的模型能夠有效地利用機器資源進行計算。
2.Tensorflow 的基本概念
1) TensorFlow的資料中央控制單元是tensor(張量),一個tensor由一系列的原始值組成,這些值被形成一個任意維數的陣列。
import tensorflow as tf - 1
上面的是TensorFlow 程式典型的匯入語句,作用是:賦予Python訪問TensorFlow類(classes),方法(methods),符號(symbols)
3.The Computational Graph
TensorFlow 核心程式由2個獨立部分組成:
a.Building the computational graph 構建計算圖
b.Running the computational graph 執行計算圖
一個 computational graph(計算圖) 是一系列的 TensorFlow 操作排列成一個節點圖:
node1 = tf.constant(3.0, dtype=tf.float32) #定義浮點精度型別的張量
node2 = tf.constant(4.0) # also tf.float32 implicitly
print(node1, node2) - 1
- 2
- 3
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0",shape=(), dtype=float32) - 1
上面 print 出來的結果只是告訴我們這張圖裡面有什麼東西,並沒有真正執行這個張量圖,執行張量圖需要經過 Running the computational graph :
sess = tf.Session()
print(sess.run([node1, node2])) - 1
- 2
[3.0, 4.0]- 1
因為這張圖沒有新增計算,所以只是簡單的離散的張量,直接把他們輸出來而已。
4.Tensorflow 的節點操作
我們可以組合Tensor節點操作(操作仍然是一個節點)來構造更加複雜的計算:
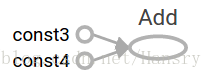
node3 = tf.add(node1, node2)
print("node3:", node3)
print("sess.run(node3):", sess.run(node3)) - 1
- 2
- 3
node3:Tensor("Add:0", shape=(), dtype=float32)
sess.run(node3):7.0 - 1
- 2
5.Placeholders 和 feed_dict 的使用
一個計算圖可以引數化的接收外部的輸入,作為一個placeholders(佔位符),一個佔位符是允許後面提供一個值的。
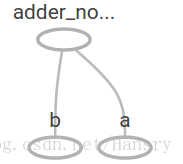
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + provides a shortcut for tf.add(a, b) - 1
- 2
- 3
我們定義了2個輸入引數a和b,然後提供一個在它們之上的操作,但是我們並沒有提供給他們具體的值,即沒有具體的張量提供計算,但是圖是已經建好的。
feed_dict(傳遞字典)引數傳遞具體的值到run方法的佔位符來進行多個輸入,從而來計算這個圖。
sess = tf.Session()
print(sess.run(adder_node, {a:3, b:4.5}))
print(sess.run(adder_node, {a: [1,3], b: [2,4]})) - 1
- 2
- 3
7.5
[ 3. 7.]- 1
- 2
增加另外的操作來讓計算圖更加複雜,比如
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
adder_node = a + b # + provides a shortcut for tf.add(a, b)
add_and_triple = adder_node *3.
sess = tf.Session()
print(sess.run(add_and_triple, {a:3, b:4.5})) - 1
- 2
- 3
- 4
- 5
- 6
- 7
22.5- 1
6. tf.Variable( ) 的使用, 並構造線性模型
在訓練模型中,我們通常想讓一個模型可以接收任意多個輸入,比如大於1個,好讓這個模型可以被訓練,在不改變輸入的情況下,
我們需要改變這個計算圖去獲得一個新的輸出。變數允許我們增加可訓練的引數到這個計算圖中,它們被構造成有一個型別和初始值:
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b - 1
- 2
- 3
- 4
當你呼叫tf.constant ()時常量被初始化,它們的值是不可以改變的,而變數當你呼叫tf.Variable()時沒有被初始化,
在TensorFlow程式中要想初始化這些變數,你必須明確呼叫一個特定的操作,如下:
init = tf.global_variables_initializer()
sess.run(init) - 1
- 2
要實現初始化所有全域性變數的TensorFlow子圖的的處理是很重要的,直到我們呼叫sess.run,這些變數都是未被初始化的。
既然x是一個佔位符,我們就可以同時地對多個x的值進行求值linear_model,例如:
print(sess.run(linear_model, {x: [1,2,3,4,5]}))- 1
[ 0. 0.30000001 0.60000002 0.90000004 1.20000005]- 1
7. 構造損失函式(loss function)
雖然已經建立了一個線性模型,如何在訓練資料上對這個模型進行評估,我們需要一個y佔位符來提供一個期望的值,並且我們需要寫一個loss function(損失函式),一個損失函式度量當前的模型和提供的資料差距有多大。
我們將會使用一個標準的損失模式來線性迴歸,它的增量平方和(最小二乘)就是當前模型與提供的資料之間的損失,linear_model - y 建立一個向量,其中每個元素都是對應的示例錯誤增量。這個錯誤的方差我們稱為tf.square。然後
,我們合計所有的錯誤方差用以建立一個標量,用tf.reduce_sum 計算出所有示例的錯誤。
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b
y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y) #||liner_model - y||^2_{2}
loss = tf.reduce_sum(squared_deltas) #sum
init = tf.global_variables_initializer()
sess=tf.Session()
sess.run(init)
print(sess.run(loss, {x: [1,2,3,4, 5], y: [0, -1, -2, -3, 2]})) - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
24.3- 1
8. optimizers(優化器)
Tensorflow提供optimizers(優化器),它能慢慢改變每一個變數以最小化損失函式,最簡單的優化器是gradient descent(梯度下降),它根據變數派生出損失的大小, 來修改每個變數。通常手工計算變數符號是乏味且容易出錯的,因此,TensorFlow使用函式tf.gradients 來進行迭代優化w 和 b:
argminw,bf(w,b)argminw,bf(w,b)
wheref(w,b)=∑ni=1(w∗xi+b−yi)2wheref(w,b)=∑i=1n(w∗xi+b−yi)2
import tensorflow as tf
W = tf.Variable([.3], dtype=tf.float32)
b = tf.Variable([-.3], dtype=tf.float32)
x = tf.placeholder(tf.float32)
linear_model = W*x + b
y = tf.placeholder(tf.float32)
squared_deltas = tf.square(linear_model - y) #||liner_model - y||^2_{2}
loss = tf.reduce_sum(squared_deltas) #sum
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
init = tf
相關推薦
Python 與 Tensorflow 簡介
一. Python 的安裝1. Window 平臺安裝 Python 在下載列表中選擇Window平臺安裝包,包格式為:python-XYZ.msi檔案 , XYZ 為你要安裝的版本號。下載後,雙擊下載包,進入Python安裝嚮導,安裝非常簡單,你只需要使用預設的設定一直點選
看了多遍博文采取幾遍結合,記錄一下Win7下Python與Tensorflow-CPU版開發環境的安裝與配置過程
以此文記錄Python與Tensorflow及其開發環境的安裝與配置過程,以備以後參考。
1 硬體與系統條件
Win7 64位系統,顯示卡為NVIDIA GeforeGT 635M
2 安裝策略
a.由於以上原因,選擇在win7下安裝cpu版的tensorflow
【TensorFlow】01 TensorFlow簡介與Python基礎
編譯器 n) The 腳本語言 ble rem 時間 完整 快的 TensorFlow簡介與Python基礎
2018.9.10
一、概述
TF使用數據數據流圖進行數值計算,亮點是支持異構設備分布式計算機
常用的ML庫有MXNet Torch/Pytorch Theano
python 虛擬環境安裝與命令簡介
python1. 更新Pip版本
#安裝
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
python3 setup.py install
pip install -U pip
2. 使用Pip安裝virtualenv虛擬環境工具,創建
python學習之簡介與環境安裝
strong 關系 ins 開發 install window 互聯 all 高級 【轉自】http://www.cnblogs.com/wupeiqi/articles/5433925.html
--Python可以應用於眾多領域
如:數據分析、組件集成、網絡服務、圖
python版本、anaconda版本與tensorflow版本對應問題
如果版本不對應往往會出現很多問題,需要各種方法才能解決,現記錄一下我工作中遇到的版本問題,以下版本一般情況下是可以直接安裝使用的。
目前一直在使用的版本:
Python 3.5.2 :: An
Scikit-Learn 與 TensorFlow 機器學習實用指南學習筆記1 — 機器學習基礎知識簡介
紅色石頭的個人網站:redstonewill.com
本章介紹的是每一個數據科學家都應該知道並聽說的機器學習許多基本的概念和術語。這將是一個高層次的概括(本書唯一沒有很多程式碼的一章)。內容很簡單,但是你要保證在進行下一章之前對本章每個概念都理解得很透徹。因此,端
Python與自然語言處理(三):Tensorflow基礎學習
看了一段時間的TensorFlow,然而一直沒有思路,偶然看到一個講解TensorFlow的系列 視訊,通俗易懂,學到了不少,在此分享一下,也記錄下自己的學習過程。
教學視訊連結:點這裡
在機器學習中,常見的就是分類問題, 郵件分類,電影分類 等等
我這裡使用iris的
Python整合開發環境Anaconda2及Pytorch與Tensorflow的安裝
1.安裝Anaconda
官方下載連結:[選擇匹配自己系統環境的版本](https://www.continuum.io/downloads)
個人百度雲盤下載連結:
開啟terminal,輸入如下命令,然後按 enter
閱讀提示,按 ente
冒泡排序-Python與PHP實現版
code 引用傳遞 true div bubble logs imp random and Python實現
import random
a=[random.randint(1,999) for x in range(0,33)]
# 冒泡排序,python中數組是按
Python 與 C/C++ 交互的幾種方式
pythonpython作為一門腳本語言,其好處是語法簡單,很多東西都已經封裝好了,直接拿過來用就行,所以實現同樣一個功能,用Python寫要比用C/C++代碼量會少得多。但是優點也必然也伴隨著缺點(這是肯定的,不然還要其他語言幹嘛),python最被人詬病的一個地方可能就是其運行速度了。這這是大部分腳本語言
選擇排序-Python與PHP實現版
blog 性能 null pytho int color += log 時間 選擇排序Python實現
import random
# 生成待排序數組
a=[random.randint(1,999) for x in range(0,36)]
# 選擇排序
def
python與編碼
brush 但是 sci 兩個 為我 編碼 全世界 編碼方式 decode 編碼的概念
編碼就是將信息從一種格式轉換為另一種格式。也就是說,將我們所認識的內容轉換為計算機所認識的二進制格式就是一種編碼的行為,而計算機將二進制格式的內容解碼成我們所認識的內容。
容器與Docker簡介(三)Docker相關術語——微軟微服務電子書翻譯系列
進程 數據 public 圖像 over 表示 -c ice ner 本節列出了在更加深入Docker之前應該熟悉的術語和定義。 有關詳細的定義,請參閱Docker提供的術語表。
容器鏡像(Container image):具有創建容器所需要的所有依賴和信息的包。 鏡像
python與mysql交互之虛擬環境搭建
packages 提示 pan 創建 項目 進行 出現 目錄 提示符 在使用命令 sudo pip install 包名稱 進行包的安裝時,會安裝到/usr/local/lib/python2.7/dist-packages下。接下來問題就出來了,如果在一臺機器上,想開
python 與 mongodb的交互---查找
小問題 文檔 問題 bsp fun -1 pri span div python與mongo數據庫交互時,在查找的時候註意的一些小問題:
代碼:
1 from pymongo import *
2 def find_func():
3 #創建連接對象
4
day32 Python與金融量化分析(二)
fill 最小 all copy data oat 模型 主板 解析 第一部分:金融與量化投資
股票:
股票是股份公司發給出資人的一種憑證,股票的持有者就是股份公司的股東。
股票的面值與市值
面值表示票面金額
市值表示市場價值
上市/IPO:
企業通過證券交易所公
Python 3 mysql 簡介安裝
-1 新浪 其他 軟件 epo centos 6 nal base 數據庫管理系統 Python 3 mysql 簡介安裝
一、數據庫是什麽
1、 什麽是數據庫(DataBase,簡稱DB)
數據庫(database,DB)是指長期存儲在計算機內的,有組織,可共享的數據的
Python*與**參數問題
正在 word 定義函數 return 需要 def div 調用 inf 本文非原創,摘自:http://www.cnblogs.com/paulwinflo/p/5764748.html
可變參數
在Python函數中,還可以定義可變參數。顧名思義,可變參數就是傳入的
文章匯總索引與內容簡介
索引所有文章索引與內容簡介,點擊文章名就可以跳到該文章頁面。索引描述Python練習(一)給一個不超過5位的正整數,判斷其有幾位,依次打印個、十、百、千、萬位的數字Python練習(二)打印n邊長的正方形Python練習(三)求100內的素數Python練習(四)求100內所有奇數和偶數的和Python練習(