
DQN 模型訓練 OpenAI CartPole-v0
阿新 • • 發佈:2019-02-04
前言:
最近學習了DQN這個可以玩遊戲的機器學習模型,其實,我們最終的目的是將強化運用到實體機器人上,讓其具有自我學習的能力,道路雖長,始於足下!在這裡給大家一個我們工作室網站連結,歡迎大家參觀指點學習:點選開啟連結
最初接觸到DQN,還是在莫煩老師的學習視訊下,在此表達對所以分享奉獻者表示感謝。
DQN就是Deep QLearning Network ,實質上就是基於QLearning 在加上神經網路的模型,本質超級簡單,是基於值的,實時更新的學習方法。
我的測試環境是VS2017 + TensorFlow + OpenAI gym,現在Tensflow 和OpenAIimport pandas as pd
import tensorflow as tfclass DQN(object): #首先建立一個模型類 def __init__(self,
n_actions,
n_features,
learning_rate = 0.01, #學習效率
reward_decay = 0.9, #獎勵衰減
e_greedy = 0.9,
replace_target_iter = 300, #跟新預測神經網路的週期
memory_size = 500, #記憶庫的大小
batch_size = 32, #神經網路的batch大小
e_greedy_increment = 0, #選擇行為時的概率增加因子
output_graph = False, #是否輸出Tensorboard
q_double = True, #是否使Double DQN
layer1_elmts = 20, #神經元個數
use_e_greedy_increment = 1000 #這裡為閾值, 1000次後減少行為隨機概率
): self.n_actions = n_actions
self.n_features = n_features
self.lr = learning_rate
self.gamma = reward_decay
self.epsilon_max = e_greedy
self.replace_target_iter =replace_target_iter
self.memory_size = memory_size
self.batch_size = batch_size
self.epsilon_increment = e_greedy_increment
self.epsilon = e_greedy self.q_double = q_double
self.layer1_elmts = layer1_elmts self.use_e_greedy_increment = use_e_greedy_increment
self.learn_step_counter = 0 self.memory = np.zeros((self.memory_size,self.n_features * 2 +2))
self.build_net()#這裡獲取eval_net的神經網路引數 e_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope = 'eval_net')#這裡獲取target_net的神經網路引數
t_params = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope = 'target_net') with tf.variable_scope('soft_replacement'): #這裡跟新預測神經網路的引數
self.target_replace_op = [tf.assign(t,e) for t ,e in zip(t_params,e_params)] self.sess = tf.Session() self.sess.run(tf.global_variables_initializer())
self.cost_his = [] #這裡建立cost陣列,影象現實cost def build_net(self): #********************* build evaluate_net ********************
self.state = tf.placeholder(tf.float32,[None,self.n_features],name = 'state') self.q_target = tf.placeholder(tf.float32,[None,self.n_actions],name = 'QTarget') w_initializer,b_initializer=tf.random_normal_initializer(0.,0.3),tf.constant_initializer(0.1) with tf.variable_scope('eval_net'): #建立現實神經網路 e_layer1 = tf.layers.dense( self.state,self.layer1_elmts,tf.nn.relu,kernel_initializer = w_initializer,\
bias_initializer = b_initializer,name = 'e_layer1' )
self.q_eval = tf.layers.dense(e_layer1,self.n_actions,kernel_initializer = w_initializer,\
bias_initializer =b_initializer,name = 'q_eval') with tf.variable_scope('loss'):
self.loss = tf.reduce_mean(tf.squared_difference( self.q_target,self.q_eval))
with tf.variable_scope('train'):
self.train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
self.state_next = tf.placeholder(tf.float32,[None,self.n_features],name = 'state_next')#建立預測神經網路 with tf.variable_scope('target_net'):
t_layer1 = tf.layers.dense(self.state_next,self.layer1_elmts,tf.nn.relu,kernel_initializer = w_initializer,\
bias_initializer = b_initializer,name = 't_layer1')
self.q_next = tf.layers.dense(t_layer1,self.n_actions,kernel_initializer = w_initializer,\
bias_initializer =b_initializer,name = 'q_next')#這裡儲存到記憶庫,採用迴圈儲存的方式,新值替換舊值
def store_transition(self,state,action,reward,state_next): if not hasattr(self,'memory_counter'):
self.memory_counter = 0 transition = np.hstack((state,[action,reward],state_next))
tmp_index = self.memory_counter % self.memory_size self.memory[tmp_index ,:] = transition self.memory_counter += 1 #以一定機率選擇行為,隨訓練的進行,逐漸減小隨機的可能性,選擇最大的值 def choose_action(self,observation): observation = observation[np.newaxis,:] if np.random.uniform() < self.epsilon: action_val = self.sess.run(self.q_eval,feed_dict={self.state :observation })
action = np.argmax(action_val)
else:
action = np.random.randint(0,self.n_actions) return action
def learn(self): if self.learn_step_counter % self.replace_target_iter == 0: #以一定週期更新預測神經網路
self.sess.run( self.target_replace_op) print('\target_params_replaced\n') if self.memory_counter > self.memory_size: #從記憶庫中取出batch
sample_index = np.random.choice(self.memory_size,size = self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter,size =self.batch_size) batch_memory = self.memory[sample_index,:]
q_next, q_eval4next,q_eval = self.sess.run( #訓練預測,和現實神經網路,這裡的Q_eval4next是 double DQN的要求
[self.q_next,self.q_eval,self.q_eval],
feed_dict = {
self.state_next: batch_memory[:,-self.n_features:], #放入的是未來狀態引數
self.state: batch_memory[:,-self.n_features:], #放入的是未來狀態引數
self.state: batch_memory[:,:self.n_features] #放入的是現在狀態引數
}
)
q_target = q_eval.copy() #這裡是為了使預測值的格式和 現實值的格式 一樣 batch_index = np.arange(self.batch_size,dtype = np.int32)
eval_act_index = batch_memory[:,self.n_features].astype(int)
reward = batch_memory[:,self.n_features+1] #double DQN 實質上就是 未來狀態放入 現實神經網路 獲取最大值的index,在預測的行為中對應,就是不選擇最大的,選擇對應的,這樣可以防止過估計。這樣的操作有點Sarsa-lambda的味道。
if(self.q_double):
max_act4next = np.argmax(q_eval4next,axis =1)
# print('***********: ',q_eval4next.shape[0],'#####:',q_eval4next.shape[1])
select_q_next = q_next[batch_index,max_act4next]
else:
select_q_next = np.max(q_next,axis =1) #這裡就是一般的預設選擇最大的 q_target[batch_index,eval_act_index] = reward + self.gamma * select_q_next #這裡重新整理q_target _,self.cost = self.sess.run([self.train_op,self.loss],feed_dict = {
self.state: batch_memory[:,:self.n_features],self.q_target:q_target
}) self.cost_his.append(self.cost) if self.learn_step_counter>self.use_e_greedy_increment: #到後面就選則最大的action
self.epsilon = self.epsilon + self.epsilon_increment #if self.epsilon < self.epsilon_max else self.epsilon_increment
self.learn_step_counter +=1 def plot_cost(self): #顯示Cost import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)),self.cost_his) plt.ylabel('Cost')
plt.xlabel('training step')
plt.show()以上就是DQN得基礎模板了,順便還有點Double DQN的在裡面。接下來就是如何訓練CartPole-v0!from mMaze import Maze
from DQN import DQN
import gymif __name__ =="__main__": env = gym.make('CartPole-v0') #建立環境
env= env.unwrapped
#以下可以顯示這個環境的state 和 action
print(env.action_space)
print(env.observation_space.shape[0])
print(env.observation_space.high)
print(env.observation_space.low)#初始化DQN的模型 RL= DQN(n_actions = env.action_space.n,
n_features = env.observation_space.shape[0],
learning_rate = 0.01,
e_greedy = 0.9,
replace_target_iter = 100,
memory_size = 2000,
e_greedy_increment = 0.001,
use_e_greedy_increment = 1000) steps = 0 for episode in range(300): #訓練300個回合,這裡環境模型,結束回合的標誌是 傾斜程度和 X 的移動限度,你可以很容易從訓練效果中看出來,當然了,也可以去看gym的底層程式碼,還是比較清晰的。
observation = env.reset()
ep_r = 0
while True: #訓練沒有結束的時候迴圈
env.render() #重新整理環境 action = RL.choose_action(observation) #根據狀態選擇行為
observation_next,reward,done,info = env.step(action) #環境模型 採用行為,獲得下個狀態,和潛在的獎勵
x,x_dot,theta,theat_dot = observation_next #這裡拆分了 狀態值 ,裡面有四個引數#這裡用了,x 和theta的限度值 來判斷獎勵的幅度,當然也可以gym自帶的 ,但是這個效率據說比較高 reward1 = (env.x_threshold - abs(x))/env.x_threshold - 0.8
reward2 = (env.theta_threshold_radians - abs(theta))/env.theta_threshold_radians - 0.5
reward = reward1+reward2 #這裡將獎勵綜合 RL.store_transition(observation,action,reward,observation_next) #先儲存到記憶庫 ep_r+= reward #這裡只是為了觀察獎勵值是否依據實際情況變化,來方便判斷模型的正確性 if steps>1000: #這裡一開始先不學習,先積累獎勵
RL.learn() if done : #這裡判斷的是回合結束,顯示獎勵積累值,你可以看到每回合獎勵的變化,來判定這樣一連序列為的結果好不好
print('episode :',episode,
'ep_r:',round(ep_r,2),
"RL's epsilon",round(RL.epsilon,3))
break observation = observation_next #跟新狀態 steps+=1 RL.plot_cost() #訓練結束後來觀察我們的cost以上就是全部的程式碼,來看下我們的執行效果:
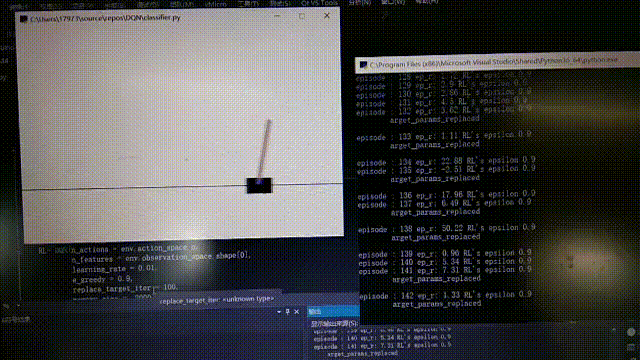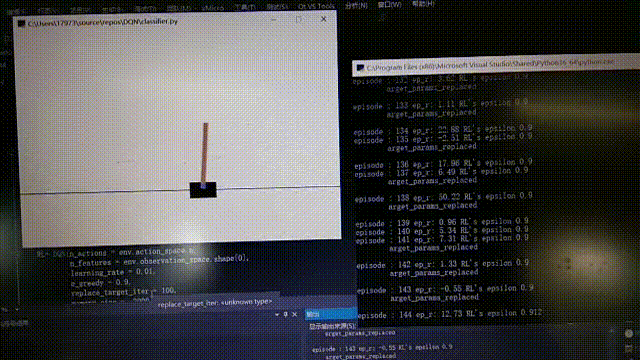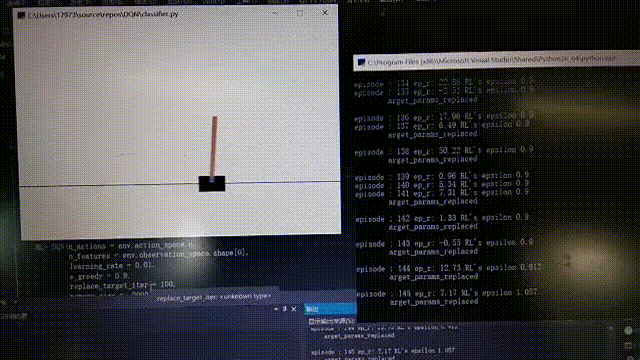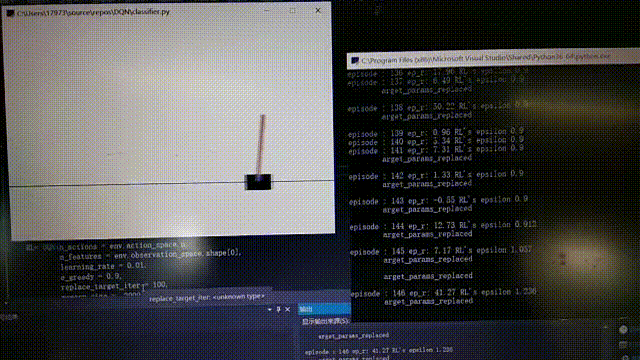
等待許久後。。。。。。
 176回合,後面就比較厲害了
176回合,後面就比較厲害了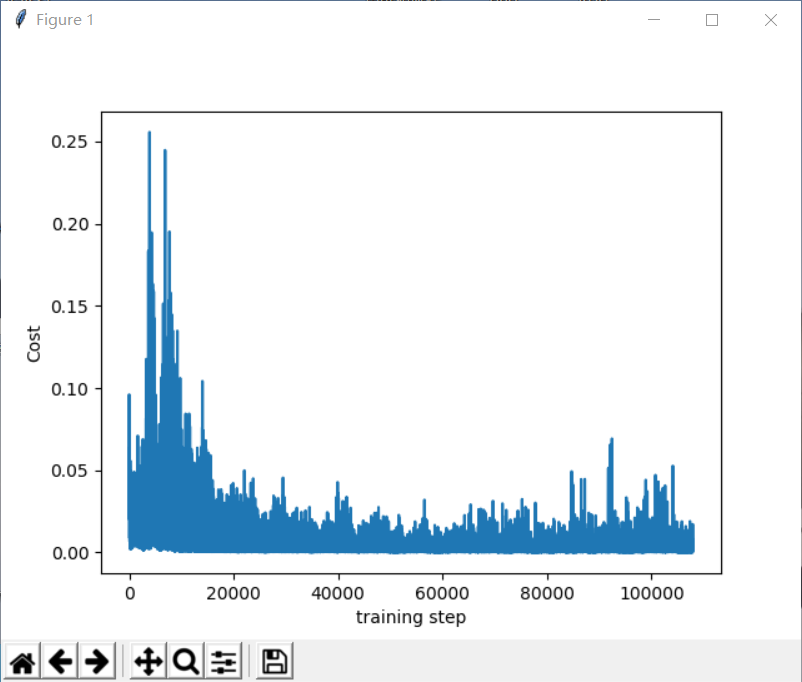 到後面的時候cost下降較為明顯,但還是有波動,這不是隨機選擇行為導致的結果,從模型中也可以看出有時候有不穩定的特徵,所以還有待改進。以上就是全部內容了。有誤希望指正。
到後面的時候cost下降較為明顯,但還是有波動,這不是隨機選擇行為導致的結果,從模型中也可以看出有時候有不穩定的特徵,所以還有待改進。以上就是全部內容了。有誤希望指正。