
基於SVM與人工神經網路的車牌識別系統
最近研究了支援向量機(Support Vector Machine,SVM)和人工神經網路(Artifical Neural Network,ANN)等模式識別理論,結合OpenCV的書:《Mastering OpenCV with Practical Computer Vision Projects》,將兩種思想運用到車輛的車牌識別演算法中。車輛識別結合了多種影象處理技術,如視訊監控、影象檢測、影象分割和光學字元識別(OCR)等,在道路交通監控中有著重要的作用。以下內容主要包含幾個方面:
車牌檢測
∙ 影象預處理(影象分割)
∙ SVM分類器(對分割影象的分類)
車牌識別
∙ OCR分割 ∙ 特徵提取 ∙ OCR分類(使用多層感知器Multi-Layer Perceptron,MLP)
一、實驗準備
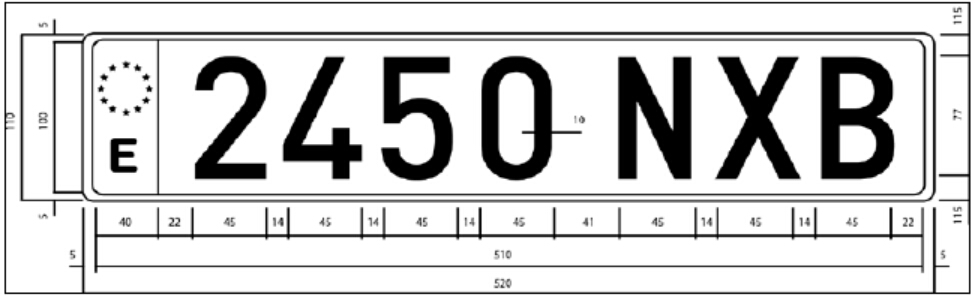
由於影象素材有限,且對於不同國家,車牌的規格與尺寸不盡相同,因此只能選擇資料中已有的西班牙車牌進行研究。這裡的素材來源於最常見的西班牙車牌(在西班牙,也有多種形狀的車牌)。如下圖所示,車牌的大小為520mm*110mm,其中左右兩組字元由41mm的空間分離,左邊包含四個數字,右邊包含三個字母,每個字元之間的距離為14mm。所有字元的大小均為45mm*77mm。
參考書籍中給出了一個已經定義好的車牌類Plate,後續的影象處理需要用到,直接使用即可,畢竟研究的重點是後續的處理和模式分類演算法:
#ifndef Plate_h
#define Plate_h
#include <string.h> #include "Plate.h"
Plate::Plate(){
}
Plate::Plate(Mat img, Rect pos){
plateImg = img;
position = pos;
}
string Plate::str(){
string result = "";
vector<int> orderIndex;
vector<int> xpositions;
for (int i = 0; i< charsPos.size(); i++){
orderIndex.push_back(i);
xpositions.push_back(charsPos[i].x);
}
float min = xpositions[0];
int minIdx = 0;
for (int i = 0; i< xpositions.size(); i++){
min = xpositions[i];
minIdx = i;
for (int j = i; j<xpositions.size(); j++){
if (xpositions[j]<min){
min = xpositions[j];
minIdx = j;
}
}
int aux_i = orderIndex[i];
int aux_min = orderIndex[minIdx];
orderIndex[i] = aux_min;
orderIndex[minIdx] = aux_i;
float aux_xi = xpositions[i];
float aux_xmin = xpositions[minIdx];
xpositions[i] = aux_xmin;
xpositions[minIdx] = aux_xi;
}
for (int i = 0; i<orderIndex.size(); i++){
result = result + chars[orderIndex[i]];
}
return result;
}二、演算法流程
正如上面敘述的,車牌識別有兩個主要步驟,即檢測與識別。其中車牌檢測的目標是在影象或視訊幀中檢測到車牌的位置。在完成這一步後,進行識別部分,這裡使用OCR演算法來識別車牌上的字元,其中有數字,也包含字母。
三、車牌檢測
- 影象分割
車牌識別的第一步自然是檢測影象或視訊幀中的車牌,並去除其他多餘的資訊,這一部分主要依靠影象分割來完成。而對於影象分割工作主要包含以下步驟:
1.Sobel濾波器;
2.閾值運算元;
3.閉形態學運算元;
4.一個填充區域掩碼;
5.用顏色標記影象中可能檢測到的車輛;
6.執行SVM分類器後檢測出車牌。
使用邊緣檢測的原因是一般情況下拍攝到的車牌有大量豎直的邊緣,且車牌沒有旋轉和透視扭曲,通過檢測豎直邊可以刪除影象中多餘的區域。在使用Sobel濾波器之前,需要確保影象為灰度影象,否則需要轉化;另一個預處理操作是進行適當的高斯濾波,從而消除可能由攝像機或其他環境產生的噪聲,這裡使用5*5的高斯濾波去噪。
以下是影象分割的原始碼,ImageEecognition.h和ImageEecognition.cpp,其中一些主要的函式呼叫方法已給出,如Sobel函式:
#ifndef ImageEecognition_h
#define ImageEecognition_h
#include <string.h>
#include <vector>
#include "Plate.h"
#include <opencv/cv.h>
#include <opencv/highgui.h>
#include <opencv/cvaux.h>
using namespace std;
using namespace cv;
class ImageRecognition{
public:
ImageRecognition();
string filename;
void setFilename(string f);
bool saveRecognition;
bool showSteps;
vector<Plate> run(Mat input);
vector<Plate> segment(Mat input);
bool verifySizes(RotatedRect mr);
Mat histeq(Mat in);
};
#endif
#include "ImageRecognition.h"
void ImageRecognition::setFilename(string name) {
filename = name;
}
ImageRecognition::ImageRecognition(){
showSteps = false;
saveRecognition = false;
}
bool ImageRecognition::verifySizes(RotatedRect ROI){
// 以下設定車牌預設引數,用於識別矩形區域內是否為目標車牌
float error = 0.4;
// 西班牙車牌寬高比: 520 / 110 = 4.7272
float aspect = 4.7272;
// 設定區域面積的最小/最大尺寸,不在此範圍內的不被視為車牌
int min = 15 * aspect * 15; // 15個畫素
int max = 125 * aspect * 125; // 125個畫素
float rmin = aspect - aspect*error;
float rmax = aspect + aspect*error;
int area = ROI.size.height * ROI.size.width;
float r = (float)ROI.size.width / (float)ROI.size.height;
if (r<1)
r = (float)ROI.size.height / (float)ROI.size.width;
// 判斷是否符合以上引數
if ((area < min || area > max) || (r < rmin || r > rmax))
return false;
else
return true;
}
// 對影象進行直方圖均衡處理,調整亮度
Mat ImageRecognition::histeq(Mat ima)
{
Mat imt(ima.size(), ima.type());
// 若輸入影象為彩色,需要在HSV空間中做直方圖均衡處理
// 再轉換回RGB格式
if (ima.channels() == 3)
{
Mat hsv;
vector<Mat> hsvSplit;
cvtColor(ima, hsv, CV_BGR2HSV);
split(hsv, hsvSplit);
equalizeHist(hsvSplit[2], hsvSplit[2]);
merge(hsvSplit, hsv);
cvtColor(hsv, imt, CV_HSV2BGR);
}
// 若輸入影象為灰度圖,直接做直方圖均衡處理
else if (ima.channels() == 1){
equalizeHist(ima, imt);
}
return imt;
}
// 影象分割函式
vector<Plate> ImageRecognition::segment(Mat input)
{
vector<Plate> output;
//n影象轉換為灰度圖
Mat grayImage;
cvtColor(input, grayImage, CV_BGR2GRAY);
blur(grayImage, grayImage, Size(5, 5)); // 對影象進行濾波,去除噪聲
// 通常車牌擁有顯著的邊緣特徵,這裡使用sobel運算元檢測邊緣
Mat sobelImage;
Sobel(grayImage, // 輸入影象
sobelImage, // 輸出影象
CV_8U, //輸出影象的深度
1, // x方向上的差分階數
0, // y方向上的差分階數
3, // 擴充套件Sobel核的大小,必須是1,3,5或7
1, // 計算導數值時可選的縮放因子,預設值是1
0, // 表示在結果存入目標圖之前可選的delta值,預設值為0
BORDER_DEFAULT); // 邊界模式,預設值為BORDER_DEFAULT
if (showSteps)
imshow("Sobel", sobelImage);
// 閾值分割得到二值影象,所採用的閾值由Otsu演算法得到
Mat thresholdImage;
// 輸入一幅8點陣圖像,自動得到優化的閾值
threshold(sobelImage, thresholdImage, 0, 255, CV_THRESH_OTSU + CV_THRESH_BINARY);
if (showSteps)
imshow("Threshold Image", thresholdImage);
// 形態學之閉運算
// 定義一個結構元素structuringElement,維度為17*3
Mat structuringElement = getStructuringElement(MORPH_RECT, Size(17, 3));
// 使用morphologyEx函式得到包含車牌的區域(但不包含車牌號)
morphologyEx(thresholdImage, thresholdImage, CV_MOP_CLOSE, structuringElement);
if (showSteps)
imshow("Close", thresholdImage);
// 找到可能的車牌的輪廓
vector< vector< Point> > contours;
findContours(thresholdImage,
contours, // 檢測的輪廓陣列,每一個輪廓用一個point型別的vector表示
CV_RETR_EXTERNAL, // 表示只檢測外輪廓
CV_CHAIN_APPROX_NONE); // 輪廓的近似辦法,這裡儲存所有的輪廓點
// 對每個輪廓檢測和提取最小區域的有界矩形區域
vector<vector<Point> >::iterator itc = contours.begin();
vector<RotatedRect> rects;
// 若沒有達到設定的寬高比要求,移去該區域
while (itc != contours.end())
{
RotatedRect ROI = minAreaRect(Mat(*itc));
if (!verifySizes(ROI)){
itc = contours.erase(itc);
}
else{
++itc;
rects.push_back(ROI);
}
}
// 在白色的圖上畫出藍色的輪廓
cv::Mat result;
input.copyTo(result);
cv::drawContours(result,
contours,
-1, // 所有的輪廓都畫出
cv::Scalar(255, 0, 0), // 顏色
1); // 線粗
// 使用漫水填充演算法裁剪車牌獲取更清晰的輪廓
for (int i = 0; i< rects.size(); i++){
circle(result, rects[i].center, 3, Scalar(0, 255, 0), -1);
// 得到寬度和高度中較小的值,得到車牌的最小尺寸
float minSize = (rects[i].size.width < rects[i].size.height) ? rects[i].size.width : rects[i].size.height;
minSize = minSize - minSize * 0.5;
// 在塊中心附近產生若干個隨機種子
srand(time(NULL));
// 初始化漫水填充演算法的引數
Mat mask;
mask.create(input.rows + 2, input.cols + 2, CV_8UC1);
mask = Scalar::all(0);
// loDiff表示當前觀察畫素值與其部件鄰域畫素值或者待加入
// 該部件的種子畫素之間的亮度或顏色之負差的最大值
int loDiff = 30;
// upDiff表示當前觀察畫素值與其部件鄰域畫素值或者待加入
// 該部件的種子畫素之間的亮度或顏色之正差的最大值
int upDiff = 30;
int connectivity = 4; // 用於控制演算法的連通性,可取4或者8
int newMaskVal = 255;
int NumSeeds = 10;
Rect ccomp;
// 操作標誌符分為幾個部分
int flags = connectivity + // 用於控制演算法的連通性,可取4或者8
(newMaskVal << 8) +
CV_FLOODFILL_FIXED_RANGE + // 設定該識別符號,會考慮當前畫素與種子畫素之間的差
CV_FLOODFILL_MASK_ONLY; // 函式不會去填充改變原始影象, 而是去填充掩模影象
for (int j = 0; j < NumSeeds; j++){
Point seed;
seed.x = rects[i].center.x + rand() % (int)minSize - (minSize / 2);
seed.y = rects[i].center.y + rand() % (int)minSize - (minSize / 2);
circle(result, seed, 1, Scalar(0, 255, 255), -1);
// 運用填充演算法,引數已設定
int area = floodFill(input,
mask,
seed,
Scalar(255, 0, 0),
&ccomp,
Scalar(loDiff, loDiff, loDiff),
Scalar(upDiff, upDiff, upDiff),
flags);
}
if (showSteps)
imshow("MASK", mask);
// 得到裁剪掩碼後,檢查其有效尺寸
// 對於每個掩碼的白色畫素,先得到其位置
// 再使用minAreaRect函式獲取最接近的裁剪區域
vector<Point> pointsInterest;
Mat_<uchar>::iterator itMask = mask.begin<uchar>();
Mat_<uchar>::iterator end = mask.end<uchar>();
for (; itMask != end; ++itMask)
if (*itMask == 255)
pointsInterest.push_back(itMask.pos());
RotatedRect minRect = minAreaRect(pointsInterest);
if (verifySizes(minRect)){
// 旋轉矩形圖
Point2f rect_points[4]; minRect.points(rect_points);
for (int j = 0; j < 4; j++)
line(result, rect_points[j], rect_points[(j + 1) % 4], Scalar(0, 0, 255), 1, 8);
// 得到旋轉影象區域的矩陣
float r = (float)minRect.size.width / (float)minRect.size.height;
float angle = minRect.angle;
if (r<1)
angle = 90 + angle;
Mat rotmat = getRotationMatrix2D(minRect.center, angle, 1);
// 通過仿射變換旋轉輸入的影象
Mat img_rotated;
warpAffine(input, img_rotated, rotmat, input.size(), CV_INTER_CUBIC);
// 最後裁剪影象
Size rect_size = minRect.size;
if (r < 1)
swap(rect_size.width, rect_size.height);
Mat img_crop;
getRectSubPix(img_rotated, rect_size, minRect.center, img_crop);
Mat resultResized;
resultResized.create(33, 144, CV_8UC3);
resize(img_crop, resultResized, resultResized.size(), 0, 0, INTER_CUBIC);
// 為了消除光照影響,對裁剪影象使用直方圖均衡化處理
Mat grayResult;
cvtColor(resultResized, grayResult, CV_BGR2GRAY);
blur(grayResult, grayResult, Size(3, 3));
grayResult = histeq(grayResult);
if (saveRecognition){
stringstream ss(stringstream::in | stringstream::out);
ss << "tmp/" << filename << "_" << i << ".jpg";
imwrite(ss.str(), grayResult);
}
output.push_back(Plate(grayResult, minRect.boundingRect()));
}
}
if (showSteps)
imshow("Contours", result);
return output;
}
vector<Plate> ImageRecognition::run(Mat input)
{
vector<Plate> tmp = segment(input);
// 返回檢測結果
return tmp;
}- 影象分類
對分割完的影象使用SVM分類,並由程式碼自動建立正負樣本。這裡需要了解一下SVM(Support Vector Machine),即支援向量機演算法,這是一種有監督學習方法。OpenCV開發SVM演算法是基於LibSVM軟體包開發的,LibSVM軟體包是臺灣大學林智仁開發設計的一個簡單、易於使用和快速有效的SVM模式識別與迴歸的軟體包。用OpenCV使用SVM演算法的大概流程如下:
1)設定訓練樣本集,一般需要兩組資料,一組是資料的類別,一組是資料的向量資訊。
2)設定SVM引數。利用CvSVMParams類實現類內的成員變數svm_type表示SVM型別:
CvSVM::C_SVC // C-SVC
CvSVM::NU_SVC // v-SVC
CvSVM::ONE_CLASS // 一類SVM
CvSVM::EPS_SVR // e-SVR
CvSVM::NU_SVR // v-SVR成員變數kernel_type表示核函式的型別:
CvSVM::LINEAR 線性 u'v
CvSVM::POLY 多項式:(r*u'v + coef0)^degree
CvSVM::RBF RBF函式:exp(-r|u-v|^2)
CvSVM::SIGMOID sigmoid函式:tanh(r*u'v + coef0)成員變數degree針對多項式核函式degree的設定,gamma針對多項式/rbf/sigmoid核函式的設定,coef0針對多項式/sigmoid核函式的設定,Cvalue為損失函式,在C-SVC、e-SVR、v-SVR中有效,nu設定v-SVC、一類SVM和v-SVR引數,p為設定e-SVR中損失函式的值,class_weightsC_SVC的權重,term_crit為SVM訓練過程的終止條件。其中預設值degree = 0,gamma = 1,coef0 = 0,Cvalue = 1,nu = 0,p = 0,class_weights = 0
3)在分類之前,需要訓練分類器。
在這裡,使用75張包含車牌的影象(正樣本)和35張不包含車牌的大小為144*33畫素的影象(對應負樣本)。(若要使車牌識別系統具有普適性,需要更多的訓練資料,在本實驗中這些資料已經夠用)。
在得到分割後的車牌和非車牌影象後,我們把二者都執行reshaple(1,1),再存放到trainImage的矩陣中,並修改對應trainLables矩陣的0-1值,然後把trainData改為32為浮點數系,再把trainData和trainLabel直接寫進xml檔案。
訓練SVM的程式碼如下:
// Main entry code OpenCV
#include <cv.h>
#include <highgui.h>
#include <cvaux.h>
#include <iostream>
#include <vector>
using namespace std;
using namespace cv;
int main ( int argc, char** argv )
{
cout << "OpenCV Training SVM Automatic Number Plate Recognition\n";
cout << "\n";
char* path_Plates;
char* path_NoPlates;
int numPlates;
int numNoPlates;
int imageWidth=144;
int imageHeight=33;
//Check if user specify image to process
if(argc >= 5 )
{
numPlates= atoi(argv[1]);
numNoPlates= atoi(argv[2]);
path_Plates= argv[3];
path_NoPlates= argv[4];
}else{
cout << "Usage:\n" << argv[0] << " <num Plate Files> <num Non Plate Files> <path to plate folder files> <path to non plate files> \n";
return 0;
}
Mat classes;//(numPlates+numNoPlates, 1, CV_32FC1);
Mat trainingData;//(numPlates+numNoPlates, imageWidth*imageHeight, CV_32FC1 );
Mat trainingImages;
vector<int> trainingLabels;
for(int i=0; i< numPlates; i++)
{
stringstream ss(stringstream::in | stringstream::out);
ss << path_Plates << i << ".jpg";
Mat img=imread(ss.str(), 0);
img= img.reshape(1, 1);
trainingImages.push_back(img);
trainingLabels.push_back(1);
}
for(int i=0; i< numNoPlates; i++)
{
stringstream ss(stringstream::in | stringstream::out);
ss << path_NoPlates << i << ".jpg";
Mat img=imread(ss.str(), 0);
img= img.reshape(1, 1);
trainingImages.push_back(img);
trainingLabels.push_back(0);
}
Mat(trainingImages).copyTo(trainingData);
//trainingData = trainingData.reshape(1,trainingData.rows);
trainingData.convertTo(trainingData, CV_32FC1);
Mat(trainingLabels).copyTo(classes);
FileStorage fs("SVM.xml", FileStorage::WRITE);
fs << "TrainingData" << trainingData;
fs << "classes" << classes;
fs.release();
return 0;
}
在程式碼中,呼叫CvSVM::train函式建立SVM模型,第一個引數為訓練資料,第二個引數為分類結果,最後一個引數即CvSVMParams。
4)用這個SVM進行分類。呼叫函式CvSVM::predict實現分類。
5)獲得支援向量
除了分類,也可以得到SVM的支援向量,呼叫函式CvSVM::get_support_vector_count獲得支援向量的個數,CvSVM::get_support_vector獲得對應的索引編號的支援向量。
在OpenCV中,SVM函式的呼叫方法如下:
// 訓練SVM,用於訓練和測試的影象資料儲存在SVM.xml檔案中
FileStorage fs;
fs.open("SVM.xml", FileStorage::READ);
Mat SVM_TrainingData;
Mat SVM_Classes;
fs["TrainingData"] >> SVM_TrainingData;
fs["classes"] >> SVM_Classes;
// 設定SVM的基本引數
CvSVMParams SVM_params; // CvSVMParams結構用於定義基本引數
SVM_params.svm_type = CvSVM::C_SVC; // SVM型別
SVM_params.kernel_type = CvSVM::LINEAR; // 不做對映
SVM_params.degree = 0;
SVM_params.gamma = 1;
SVM_params.coef0 = 0;
SVM_params.C = 1;
SVM_params.nu = 0;
SVM_params.p = 0;
SVM_params.term_crit = cvTermCriteria(CV_TERMCRIT_ITER, 1000, 0.01);
// 建立並訓練分類器
CvSVM svmClassifier(SVM_TrainingData, SVM_Classes, Mat(), Mat(), SVM_params);取各個影象預處理步驟的結果,如下圖所示:

其中圖1為原彩色影象;
圖2將彩色影象轉化為灰度圖,並採用5*5模版對影象進行高斯濾波,去除環境噪聲;
圖3是使用Sobel濾波器求一階水平方向導數,輸出垂直邊緣的結果;
圖4使用Otsu自適應閾值演算法獲得影象二值化的閾值,從而得到二值影象;
圖5採用閉操作,去除每個垂直邊緣線之間的空白空格,並連線所有包含 大量邊緣的區域(這步過後,我們將有許多包含車牌的候選區域);
圖6顯示了執行SVM分類器後得到的正負樣本,此時需要對這些正負樣本(其實是分割後的影象塊)進行分類。
四、車牌識別
車牌識別演算法的第二步是使用光學字元識別獲取車牌上的字元,而對於車牌號識別工作主要包含以下步驟:
1.ROC分割:對於每個車牌,可以將每個字元分割出來
2.訓練人工神經網路(Artificial Neural Network, ANN)
3.使用人工神經網路以識別字符
- ROC分割
分割步驟如下圖所示:

首先,圖1為輸入分割後的車牌,之後,對影象進行二值化,如圖2所示;之後求每個字元的輪廓、最小外接矩形進而求矩形的縱橫比及面積。最後統一矩形大小,並將每個字元的圖片儲存下來。
- 訓練人工神經網路
人工神經網路實際是一個多層感知器,是一種前饋人工神經網路模型,其將輸入的多個數據集對映到單一的輸出的資料集上。對比單層感知器,多層感知器的一大優點是可以輕鬆實現非線性分類。一個簡單的例子是:單個感知器無法解決異或問題,但將多個感知器進行組合可以實現這種較為複雜的空間分割,如下圖所示。
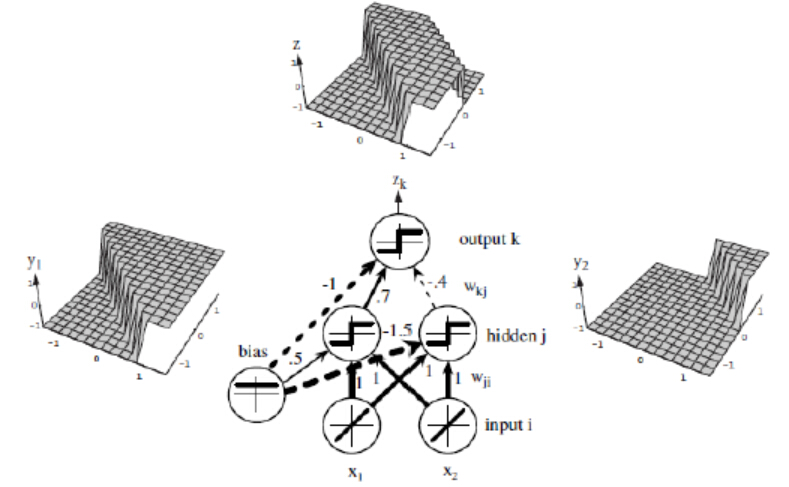
實際上,上述模型就是多層感知器神經網路(Multi-layer perceptron neural networks,MLP neural netwoks)的基礎模型。神經網路中每個節點為一個感知器,模型生物神經網路中神經元的基礎功能:來自外界(環境或其他細胞)的電訊號通過突觸傳遞給神經元,當細胞收到的訊號總和超過一定閾值後,細胞被啟用,通過軸突向下一個細胞傳送電訊號,完成對外界資訊的加工。

- 使用人工神經網路以識別字符
主要包含以下步驟:
1.讀取一張車牌影象
2.設定人工神經網路引數,並使用xml檔案訓練神經網路
3.提取車牌影象的累計直方圖和低解析度影象特徵矩陣
4.將該特徵矩陣作為神經網路輸入,經過神經網路計算從而得到預測結果
5.按照每個字元影象的相對位置,進行字元重新排序
6.得到最終的字串並打印出來
車牌識別部分的完整程式碼如下:
#ifndef OCR_h
#define OCR_h
#include <string.h>
#include <vector>
#include "Plate.h"
#include <opencv/cv.h>
#include <opencv/highgui.h>
#include <opencv/cvaux.h>
#include <opencv/ml.h>
using namespace std;
using namespace cv;
#define HORIZONTAL 1
#define VERTICAL 0
class CharSegment{
public:
CharSegment();
CharSegment(Mat i, Rect p);
Mat img;
Rect pos;
};
class OCR{
public:
bool DEBUG;
bool saveSegments;
string filename;
static const int numCharacters;
static const char strCharacters[];
OCR(string trainFile);
OCR();
string run(Plate *input);
int charSize;
Mat preprocessChar(Mat in);
int classify(Mat f);
void train(Mat trainData, Mat trainClasses, int nlayers);
int classifyKnn(Mat f);
void trainKnn(Mat trainSamples, Mat trainClasses, int k);
Mat features(Mat input, int size);
private:
bool trained;
vector<CharSegment> segment(Plate input);
Mat Preprocess(Mat in, int newSize);
Mat getVisualHistogram(Mat *hist, int type);
void drawVisualFeatures(Mat character, Mat hhist, Mat vhist, Mat lowData);
Mat ProjectedHistogram(Mat img, int t);
bool verifySizes(Mat r);
CvANN_MLP ann;
CvKNearest knnClassifier;
int K;
};
#endif
#include "OCR.h"
const char OCR::strCharacters[] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'B', 'C', 'D', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'R', 'S', 'T', 'V', 'W', 'X', 'Y', 'Z' };
const int OCR::numCharacters = 30;
CharSegment::CharSegment(){}
CharSegment::CharSegment(Mat i, Rect p)
{
img = i;
pos = p;
}
OCR::OCR()
{
DEBUG = false;
trained = false;
saveSegments = false;
charSize = 20;
}
OCR::OCR(string trainFile)
{
DEBUG = false;
trained = false;
saveSegments = false;
charSize = 20;
// 讀取OCR.xml檔案
FileStorage fs;
fs.open("OCR.xml", FileStorage::READ);
Mat TrainingData;
Mat Classes;
fs["TrainingDataF15"] >> TrainingData;
fs["classes"] >> Classes;
train(TrainingData, Classes, 10);
}
Mat OCR::preprocessChar(Mat in){
//Remap image
int h = in.rows;
int w = in.cols;
Mat transformMat = Mat::eye(2, 3, CV_32F);
int m = max(w, h);
transformMat.at<float>(0, 2) = m / 2 - w / 2;
transformMat.at<float>(1, 2) = m / 2 - h / 2;
Mat warpImage(m, m, in.type());
warpAffine(in, warpImage, transformMat, warpImage.size(), INTER_LINEAR, BORDER_CONSTANT, Scalar(0));
Mat out;
resize(warpImage, out, Size(charSize, charSize));
return out;
}
bool OCR::verifySizes(Mat r){
// 正確的車牌字元寬高比為45/77
float aspect = 45.0f / 77.0f;
float charAspect = (float)r.cols / (float)r.rows;
float error = 0.35; // 允許誤差達到35%
float minHeight = 15;
float maxHeight = 28;
// 最小比例
float minAspect = 0.2;
float maxAspect = aspect + aspect*error;
// 區域畫素
float area = countNonZero(r);
// bb區域
float bbArea = r.cols*r.rows;
// 畫素佔區域的百分比
float percPixels = area / bbArea;
// 若一塊區域的比率超過標準比率的80%,則認為該區域為黑色快,而不是一個字元
if (DEBUG)
cout << "Aspect: " << aspect << " [" << minAspect << "," << maxAspect << "] " << "Area " << percPixels << " Char aspect " << charAspect << " Height char " << r.rows << "\n";
if (percPixels < 0.8 && charAspect > minAspect && charAspect < maxAspect && r.rows >= minHeight && r.rows < maxHeight)
return true;
else
return false;
}
// 閾值分割
vector<CharSegment> OCR::segment(Plate plate){
Mat input = plate.plateImg;
vector<CharSegment> output;
Mat thresholdImage;
threshold(input, thresholdImage, 60, 255, CV_THRESH_BINARY_INV);
if (DEBUG)
imshow("Threshold plate", thresholdImage);
Mat img_contours;
thresholdImage.copyTo(img_contours);
// 找到可能的車牌的輪廓
vector< vector< Point> > contours;
findContours(thresholdImage,
contours, // 檢測的輪廓陣列,每一個輪廓用一個point型別的vector表示
CV_RETR_EXTERNAL, // 表示只檢測外輪廓
CV_CHAIN_APPROX_NONE); // 輪廓的近似辦法,這裡儲存所有的輪廓點
// 在白色的圖上畫出藍色的輪廓
cv::Mat result;
thresholdImage.copyTo(result);
cvtColor(result, result, CV_GRAY2RGB);
cv::drawContours(result, contours,
-1, // 所有的輪廓都畫出
cv::Scalar(255, 0, 0), // 顏色
1); // 線粗
// 對每個輪廓檢測和提取最小區域的有界矩形區域
vector<vector<Point> >::iterator itc = contours.begin();
char res[20];
int i = 0;
// 若沒有達到設定的寬高比要求,移去該區域
while (itc != contours.end())
{
Rect mr = boundingRect(Mat(*itc));
rectangle(result, mr, Scalar(0, 255, 0));
// 裁剪影象
Mat auxRoi(thresholdImage, mr);
if (verifySizes(auxRoi)){
auxRoi = preprocessChar(auxRoi);
output.push_back(CharSegment(auxRoi, mr));
//儲存每個字元圖片
sprintf(res, "PlateNumber%d.jpg", i);
i++;
imwrite(res, auxRoi);
rectangle(result, mr, Scalar(0, 125, 255));
}
++itc;
}
if (DEBUG)
cout << "Num chars: " << output.size() << "\n";
if (DEBUG)
imshow("SEgmented Chars", result);
return output;
}
Mat OCR::ProjectedHistogram(Mat img, int t)
{
int sz = (t) ? img.rows : img.cols;
Mat mhist = Mat::zeros(1, sz, CV_32F);
for (int j = 0; j<sz; j++){
Mat data = (t) ? img.row(j) : img.col(j);
mhist.at<float>(j) = countNonZero(data);
}
// 歸一化直方圖
double min, max;
minMaxLoc(mhist, &min, &max);
if (max>0)
mhist.convertTo(mhist, -1, 1.0f / max, 0);
return mhist;
}
Mat OCR::getVisualHistogram(Mat *hist, int type)
{
int size = 100;
Mat imHist;
if (type == HORIZONTAL){
imHist.create(Size(size, hist->cols), CV_8UC3);
}
else{
imHist.create(Size(hist->cols, size), CV_8UC3);
}
imHist = Scalar(55, 55, 55);
for (int i = 0; i<hist->cols; i++){
float value = hist->at<float>(i);
int maxval = (int)(value*size);
Point pt1;
Point pt2, pt3, pt4;
if (type == HORIZONTAL)
{
pt1.x = pt3.x = 0;
pt2.x = pt4.x = maxval;
pt1.y = pt2.y = i;
pt3.y = pt4.y = i + 1;
line(imHist, pt1, pt2, CV_RGB(220, 220, 220), 1, 8, 0);
line(imHist, pt3, pt4, CV_RGB(34, 34, 34), 1, 8, 0);
pt3.y = pt4.y = i + 2;
line(imHist, pt3, pt4, CV_RGB(44, 44, 44), 1, 8, 0);
pt3.y = pt4.y = i + 3;
line(imHist, pt3, pt4, CV_RGB(50, 50, 50), 1, 8, 0);
}
else
{
pt1.x = pt2.x = i;
pt3.x = pt4.x = i + 1;
pt1.y = pt3.y = 100;
pt2.y = pt4.y = 100 - maxval;
line(imHist, pt1, pt2, CV_RGB(220, 220, 220), 1, 8, 0);
line(imHist, pt3, pt4, CV_RGB(34, 34, 34), 1, 8, 0);
pt3.x = pt4.x = i + 2;
line(imHist, pt3, pt4, CV_RGB(44, 44, 44), 1, 8, 0);
pt3.x = pt4.x = i + 3;
line(imHist, pt3, pt4, CV_RGB(50, 50, 50), 1, 8, 0);
}
}
return imHist;
}
void OCR::drawVisualFeatures(Mat character, Mat hhist, Mat vhist, Mat lowData){
Mat img(121, 121, CV_8UC3, Scalar(0, 0, 0));
Mat ch;
Mat ld;
cvtColor(character, ch, CV_GRAY2RGB);
resize(lowData, ld, Size(100, 100), 0, 0, INTER_NEAREST);
cvtColor(ld, ld, CV_GRAY2RGB);
Mat hh = getVisualHistogram(&hhist, HORIZONTAL);
Mat hv = getVisualHistogram(&vhist, VERTICAL);
Mat subImg = img(Rect(0, 101, 20, 20));
ch.copyTo(subImg);
subImg = img(Rect(21, 101, 100, 20));
hh.copyTo(subImg);
subImg = img(Rect(0, 0, 20, 100));
hv.copyTo(subImg);
subImg = img(Rect(21, 0, 100, 100));
ld.copyTo(subImg);
line(img, Point(0, 100), Point(121, 100), Scalar(0, 0, 255));
line(img, Point(20, 0), Point(20, 121), Scalar(0, 0, 255));
imshow("Visual Features", img);
cvWaitKey(0);
}
// 特徵提取
Mat OCR::features(Mat in, int sizeData){
//Histogram features
Mat vhist = ProjectedHistogram(in, VERTICAL);
Mat hhist = ProjectedHistogram(in, HORIZONTAL);
Mat lowData;
resize(in, lowData, Size(sizeData, sizeData));
if (DEBUG)
drawVisualFeatures(in, hhist, vhist, lowData);
int numCols = vhist.cols + hhist.cols + lowData.cols*lowData.cols;
Mat out = Mat::zeros(1, numCols, CV_32F);
int j = 0;
for (int i = 0; i<vhist.cols; i++)
{
out.at<float>(j) = vhist.at<float>(i);
j++;
}
for (int i = 0; i<hhist.cols; i++)
{
out.at<float>(j) = hhist.at<float>(i);
j++;
}
for (int x = 0; x<lowData.cols; x++)
{
for (int y = 0; y<lowData.rows; y++){
out.at<float>(j) = (float)lowData.at<unsigned char>(x, y);
j++;
}
}
if (DEBUG)
cout << out << "\n===========================================\n";
return out;
}
// 用於建立所有需要的矩陣並用訓練資料、類標籤矩
// 陣、在隱藏層的神經元數量來訓練一個識別系統
void OCR::train(Mat TrainData, Mat classes, int nlayers){
Mat layers(1, 3, CV_32SC1);
layers.at<int>(0) = TrainData.cols;
layers.at<int>(1) = nlayers;
layers.at<int>(2) = numCharacters;
ann.create(layers, CvANN_MLP::SIGMOID_SYM, 1, 1);
// 建立一個矩陣,其中存放n個訓練資料,並將其分為m類
Mat trainClasses;
trainClasses.create(TrainData.rows, numCharacters, CV_32FC1);
for (int i = 0; i < trainClasses.rows; i++)
{
for (int k = 0; k < trainClasses.cols; k++)
{
if (k == classes.at<int>(i))
trainClasses.at<float>(i, k) = 1;
else
trainClasses.at<float>(i, k) = 0;
}
}
Mat weights(1, TrainData.rows, CV_32FC1, Scalar::all(1));
// 分類器學習
ann.train(TrainData, trainClasses, weights);
trained = true;
}
int OCR::classify(Mat f){
int result = -1;
Mat output(1, numCharacters, CV_32FC1);
ann.predict(f, output);
Point maxLoc;
double maxVal;
minMaxLoc(output, 0, &maxVal, 0, &