
用BP人工神經網路識別手寫數字——《Python也可以》之三
這是我讀工程碩士的時候完成課程作業時做的,放在 dropbox 的角落中生塵已經有若干年頭了,最近 @shugelee 同學突然來了興致搞驗證碼識別,問到我的時候我記起自己做過一點點東西,特發上來給他參考,並趁機補充了一下《Python也可以》系列。
影象預處理
使用下圖(後方稱為 SAMPLE_BMP)作為訓練和測試資料來源,下文將講述如何將影象轉換為訓練資料。
灰度化和二值化
在字元識別的過程中,識別演算法不需要關心影象的彩色資訊。因此,需要將彩色影象轉化為灰度影象。經過灰度化處理後的影象中還包含有背景資訊。因此,我們還得進一步處理,將背景噪聲遮蔽掉,突顯出字元輪廓資訊。二值化處理就能夠將其中的字元顯現出來,並將背景去除掉。在一個[0,255]灰度級的灰度影象中,我們取 196 為該灰度影象的歸一化值,程式碼如下:下圖是灰度化的影象,可以看到背景仍然比較明顯,有一層淡灰色:def convert_to_bw(im): im = im.convert("L") im.save("sample_L.bmp") im = im.point(lambda x: WHITE if x > 196 else BLACK) im = im.convert('1') im.save("sample_1.bmp") return im

下圖是二值化的影象,可以看到背景已經完全去除:

圖片的分割和規範化:
通過二值化影象,我們可以分割出每一個字元為一個單獨的圖片,然後再計算相應的特徵值,如下圖所示: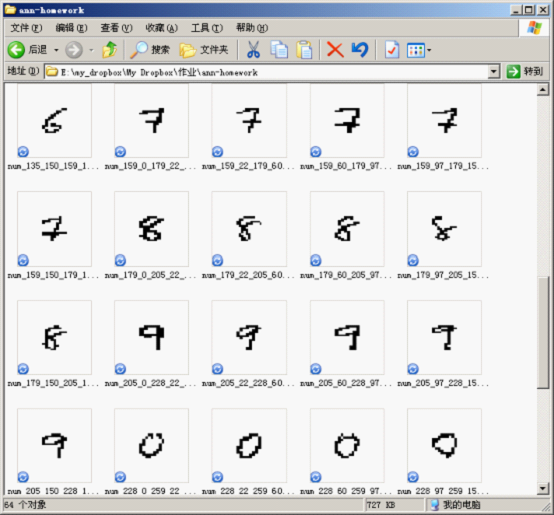
這些圖片是由程式自動進行分割而成,其中用到的程式碼片段如下:
其中的 xs 和 ys 分別是橫向和豎向切割的分界點,由手工測試後指定,t = im.crop(box).copy() 程式碼行是從指定的區域中“摳”出圖片,然後通過 normalize_32_32 進行規範化。進行規範化是為了產生規則的訓練和測試資料集,也是為了更容易地地計算出特徵碼。def split(im): assert im.mode == '1' result = [] w, h = im.size data = im.load() xs = [0, 23, 57, 77, 106, 135, 159, 179, 205, 228, w] ys = [0, 22, 60, 97, 150, h] for i, x in enumerate(xs): if i + 1 >= len(xs): break for j, y in enumerate(ys): if j + 1 >= len(ys): break box = (x, y, xs[i+1], ys[j+1]) t = im.crop(box).copy() box = box + ((i + 1) % 10, ) # save_32_32(t, 'num_%d_%d_%d_%d_%d'%box) result.append((normalize_32_32(t, 'num_%d_%d_%d_%d_%d'%box), (i + 1) % 10)) return result
產生訓練資料集和測試資料集
為簡單起見,我們使用了最簡單的影象特徵——黑色畫素在影象中的分佈來進行訓練和測試。首先,我們把影象規範化為 32*32 畫素的圖片,然後按 2*2 分切成 16*16 共 256 個子區域,然後統計這 4 個畫素中黑色畫素的個數,組成 256 維的特徵向量,如下是數字 2 的一個特徵向量:0 0 4 4 4 2 0 0 0 0 0 0 0 0 2 4 0 0 4 4 4 2 0 0 0 0 0 0 0 0 2 4 2 2 4 4 2 1 0 0 0 0 0 0 1 2 3 4 4 4 4 4 0 0 0 0 0 0 0 0 2 4 4 4 4 4 4 4 0 0 0 0 0 0 0 0 2 4 4 4 4 4 0 0 0 0 0 0 0 0 0 0 2 4 4 4 4 4 0 0 0 0 0 0 0 0 0 0 2 4 4 4 4 4 0 0 0 0 0 0 0 4 4 4 4 4 4 4 4 4 0 0 0 0 0 0 0 4 4 4 4 4 4 4 4 4 2 2 2 2 2 2 2 4 4 2 3 4 4 4 4 4 4 4 4 4 4 4 4 4 4 0 2 4 4 4 2 2 2 2 4 3 2 2 2 2 2 0 2 4 4 4 0 0 0 0 4 2 0 0 0 0 0 0 2 4 4 4 0 0 0 0 4 2 0 0 0 0 0 0 2 4 4 4 0 0 0 0 0 0 0 0 0 0 0 0 2 4 4 4 0 0 0 0 0 0 0 0 0 0 0 0 2 4 4 4
相應地,因為我們只需要識別 0~9 共 10 個數字,所以建立一個 10 維的向量作為結果,數字相應的維置為 1 值,其它值為 0。數字 2 的結果如下:0 0 1 0 0 0 0 0 0 0
我們特徵向量和結果向量通過以下程式碼計算出來後,按 FANN 的格式把它們存到 train.data 中去:
f = open('train.data', 'wt') print >>f, len(result), 256, 10 for input, output in result: print >>f, input print >>f, output
BP神經網路
利用神經網路識別字符是本文的另外一個關鍵階段,良好的網路效能是識別結果可靠性的重要保證。這裡就介紹如何利用BP 神經網路來識別字符。反向傳播網路(即:Back-Propagation Networks ,簡稱:BP 網路)是對非線性可微分函式進行權值訓練的多層前向網路。在人工神經網路的實際應用中,80%~90%的模型採用 BP 網路。它主要用在函式逼近,模式識別,分類,資料壓縮等幾個方面,體現了人工神經網路的核心部分。網路結構
網路結構的設計是根據輸入結點和輸出結點的個數和網路效能來決定的,如下圖。本實驗中的標準待識別字符的大小為 32*32 的二值影象,即將 1024 個畫素點的影象轉化為一個 256 維的列向量作為輸入。由於本實驗要識別出10 個字元,可以將目標輸出的值設定為一個10 維的列向量,其中與字元相對應那個位為1,其他的全為0 。根據實際經驗和試驗確定,本文中的網路隱含層結點數目為64。因此,本文中的BP 網路的結構為 256-64-10。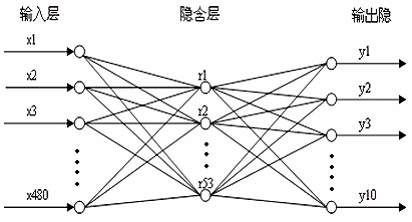
訓練結果
本實驗中的採用的樣本個數為 50 個,將樣本影象進行預處理,得到處理後的樣本向量P,再設定好對應的網路輸出目標向量T,把樣本向量 P 和網路輸出目標向量 T 都儲存到 train.data 檔案中。設定好網路訓練引數,對網路進行訓練和測試,並將最佳的一個網路權值儲存到 number_char_recognize.net 檔案中。下面就將本文中設定和訓練網路引數的程式列舉如下:connectionRate = 1
learningRate = 0.008
desiredError = 0.001
maxIterations = 10000
iterationsBetweenReports = 100
inNum= 256
hideNum = 64
outNum=10
class NeuNet(neural_net):
def __init__(self):
neural_net.__init__(self)
neural_net.create_standard_array(self,(inNum, hideNum, outNum))
def train_on_file(self,fileName):
neural_net.train_on_file(self,fileName,maxIterations,iterationsBetweenReports,desiredError)if __name__ == "__main__":
ann = NeuNet()
ann.train_on_file("train.data")
ann.save("number_char_recognize2.net")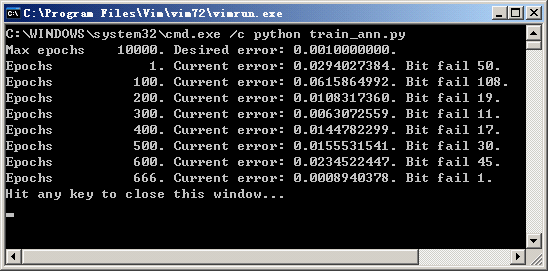
通過 666 次迭代之後,錯誤率已經低於 0.001,學習中止,並將結果儲存起來。
測試結果
實驗的測試是通過從儲存好的 NN 資料檔案中建立 NN 的形式來實驗的,具體的程式碼如下:if __name__ == "__main__":
ann = NeuNet()
ann.create_from_file("number_char_recognize.net")
data = read_test_data()
for k, v in data.iteritems():
k = string_to_list(k)
v = string_to_list(v)
result = ann.run(k)
print euclidean_distance(v, result)

可見兩個向量的歐氏距離已經接近於 0,識別效果非常好。
小結
本文為該項研究的初步實驗階段,由於樣本字元的數目較少,選取了50 個樣本用來訓練,對10 個待檢數字字元進行識別和模擬,成功識別出字元的個數為9 個,識別效率為90.0%。對於神經網路而言,在這樣少的訓練樣本的情況下,能夠取的這種效果已經比較成功,表明該方法具有較好識別效能。相關推薦
用BP人工神經網路識別手寫數字——《Python也可以》之三
這是我讀工程碩士的時候完成課程作業時做的,放在 dropbox 的角落中生塵已經有若干年頭了,最近 @shugelee 同學突然來了興致搞驗證碼識別,問到我的時候我記起自己做過一點點東西,特發上來給他參考,並趁機補充了一下《Python也可以》系列。影象預處理使用下圖(後方稱
利用卷積神經網路識別手寫數字
1.測試資料準備 1.我們使用的測試資料,可以直接從keras.datasets.mnist匯入 import numpy as np import seaborn as sns import matplotlib.pyplot as plt plt.rcParams['figure
tensorflow-神經網路識別手寫數字
資料下載連線:http://yann.lecun.com/exdb/mnist/ 下載t10k-images-idx3-ubyte.gz;t10k-labels-idx1-ubyte.gz;train-images-idx3-ubyte.gz;train-labels-idx1
第一章: 利用神經網路識別手寫數字
人類視覺系統是大自然的一大奇蹟。 考慮下面的手寫數字序列: 大部分人能夠毫不費力的識別出這些數字是 504192。這種簡單性只是一個幻覺。在我們大腦各半球,有一個主要的視覺皮層,即V1,它包含1.4億個神經元以及數以百億的神經元連線。而且人類不只
機器學習(四):BP神經網路_手寫數字識別_Python
機器學習演算法Python實現 三、BP神經網路 全部程式碼 1、神經網路model 先介紹個三層的神經網路,如下圖所示 輸入層(input layer)有三個units(為
用python的numpy實現神經網路 實現 手寫數字識別
首先是讀取檔案,train-images-idx3-ubyte等四個檔案是mnist資料集裡的資料。放在MNIST資料夾裡。MNIST資料夾和這個.py檔案放在同一個資料夾裡。 import numpy as np import struct train_images
【深度學習】python實現簡單神經網路以及手寫數字識別案例
前言 \quad \qu
利用卷積神經網路進行手寫數字識別詳解
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data ‘’‘可分別用這兩個函式建立卷積核(kernel)與偏置(bias)’’’ #返回一個給定形狀的變數,並自動以截斷正態分佈
【深度學習】基於Numpy實現的神經網路進行手寫數字識別
直接先用前面設定的網路進行識別,即進行推理的過程,而先忽視學習的過程。 推理的過程其實就是前向傳播的過程。 深度學習也是分成兩步:學習 + 推理。學習就是訓練模型,更新引數;推理就是用學習到的引數來處理新的資料。 from keras.datasets.mnist impor
邏輯迴歸softmax神經網路實現手寫數字識別(cs)
邏輯迴歸softmax神經網路實現手寫數字識別全過程 1 - 匯入模組 import numpy as np import matplotlib.pyplot as plt from ld_mnist import load_digits
Deep Learning-TensorFlow (1) CNN卷積神經網路_MNIST手寫數字識別程式碼實現詳解
import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data import time # 計算開始時間 start = time.clock()
第一章 用神經網路來識別手寫數字(1)
寫在章節前面的 翻譯文章來源 人類的識別系統是世界上的一大奇蹟,看下面的一串手寫數字 大部分人都能準確地認出這些數字是504192,這是很容易的。在大腦的每個半球,人類都有一個被稱為V1的視覺皮層,其中包含了超過140,000,000個
python神經網路解決手寫識別問題演算法和程式碼
1.演算法 2.程式碼 import numpy # scipy.special for the sigmoid function expit() import scipy.special # library for plotting arrays import matplotlib.
基於神經網路(多層感知機)識別手寫數字
資料集是經典的MNIST,來自美國國家標準與技術研究所,是人工書寫的0~9數字圖片,圖片的畫素為28*28,圖片為灰度圖。MNIST分別為訓練集和測試集,訓練資料包含6萬個樣本,測試資料集包含1萬個樣本。使用Tensorflow框架載入資料集。 載入資料集的程式碼如下: import ten
機器學習筆記:tensorflow實現卷積神經網路經典案例--識別手寫數字
從識別手寫數字的案例開始認識神經網路,並瞭解如何在tensorflow中一步步建立卷積神經網路。 安裝tensorflow 資料來源 kaggle新手入門的數字識別案例,包含手寫0-9的灰度值影象的csv檔案,下載地址:https://www.
matlab手寫神經網路實現識別手寫數字
實驗說明 一直想自己寫一個神經網路來實現手寫數字的識別,而不是套用別人的框架。恰巧前幾天,有幸從同學那拿到5000張已經貼好標籤的手寫數字圖片,於是我就嘗試用matlab寫一個網路。 實驗資料:5000張手寫數字圖片(.jpg),圖片命名為1.jpg,2.
【python keras實戰】利用VGG卷積神經網路進行手寫字型識別
# encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import numpy as np from keras.datasets import mnist impor
python手寫神經網路實現識別手寫數字
實驗說明 一直想自己寫一個神經網路來實現手寫數字的識別,而不是套用別人的框架。恰巧前幾天,有幸從同學那拿到5000張已經貼好標籤的手寫數字圖片,於是我就嘗試用matlab寫一個網路。 實驗資料:5000張手寫數字圖片(.jpg),圖片命名為
基於BP人工神經網路的數字字元識別及MATLAB實現
應用背景:在模式識別中,有一種高實用性的分類方法,就是人工神經網路,它被成功應用於智慧機器人、自動控制、語音識別、預測估計、生物、醫學、經濟等領域,解決了許多其他分類方法難以解決的實際問題。這得益於神經網路的模型比較多,可針對不同的問題使用相應的神經網路模型,這裡使用BP神
keras+卷積神經網路HWDB手寫漢字識別
寫在前面 HWDB手寫漢字資料集來自於中科院自動化研究所,下載地址: 原始碼 按照github上的提示操作: (1)解壓 unzip HWDB1.1trn_gnt.zip Archive: HWDB1.1trn_gnt.zip inflating: