
[python] 網路資料採集 操作清單 BeautifulSoup、Selenium、Tesseract、CSV等
Python網路資料採集操作清單
BeautifulSoup、Selenium、Tesseract、CSV等
常用正則表示式清單
常用正則表示式符號
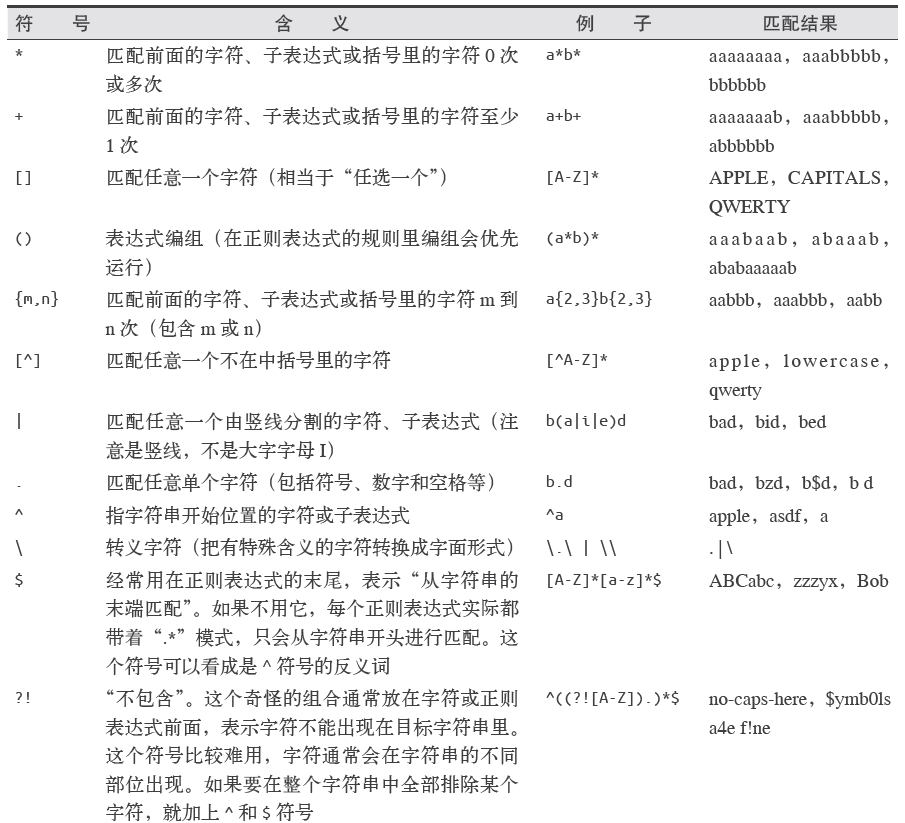
電子郵箱
[A-Za-z0-9\._+][email protected][A-Za-z]+\.(com|org|edu|net)
找出所有以”/”開頭的連結
for link in bsObj.findAll("a", href=re.compile("^(/|.*"+includeUrl+")")):
if link.attrs['href'] is not None 所有以”http”或”www”開頭且不包含當前URL的連結
for link in bsObj.findAll("a",
href = re.compile("^(http|www)((?!"+excludeUrl+").)*$")):
if 查詢
.get_text()
會把正在處理的HTML文件中所有的超連結、段落、標籤都清楚並返回只包含文字的字串
.findAll(tag, attributes, recursive, text, limit, keywords)
標籤引數tag 前面已經介紹過——你可以傳一個標籤的名稱或多個標籤名稱組成的Python
列表做標籤引數。例如,下面的程式碼將返回一個包含HTML 文件中所有標題標籤的列表:1
.findAll({“h1”,”h2”,”h3”,”h4”,”h5”,”h6”})屬性引數attributes 是用一個Python 字典封裝一個標籤的若干屬性和對應的屬性值。例如,下面這個函式會返回HTML文件裡紅色與綠色兩種顏色的span 標籤:
.findAll(“span”, {“class”:{“green”, “red”}})遞迴引數recursive 是一個布林變數。你想抓取HTML文件標籤結構裡多少層的資訊?如果recursive 設定為True,findAll就會根據你的要求去查詢標籤引數的所有子標籤,以及子標籤的子標籤。如果recursive設定為False,findAll就只查詢文件的一級標籤。findAll預設是支援遞迴查詢的(recursive預設值是True);一般情況下這個引數不需要設定,除非你真正瞭解自己需要哪些資訊,而且抓取速度非常重要,那時你可以設定遞迴引數。
文字引數text有點不同,它是用標籤的文字內容去匹配,而不是用標籤的屬性。假如我們想查詢前面網頁中包含“theprince”內容的標籤數量,我們可以把之前的findAll 方法換
成下面的程式碼:
nameList = bsObj.findAll(text=”the prince”)
print(len(nameList))
輸出結果為“7”。範圍限制引數limit,顯然只用於findAll 方法。find 其實等價於findAll 的limit等於1時的情形。如果你只對網頁中獲取的前x 項結果感興趣,就可以設定它。但是要注意,這個引數設定之後,獲得的前幾項結果是按照網頁上的順序排序的,未必是你想要的那前幾項。
還有一個關鍵詞引數keyword,可以讓你選擇那些具有指定屬性的標籤。例如:
allText = bsObj.findAll(id=”text”)
print(allText[0].get_text())
通過標籤引數tag把標籤列表傳到.findAll() 裡獲取一列標籤,實就是一個“或”關係的過濾器(即選擇所有帶標籤1或標籤2或標籤3……的一列標籤)。如果你的標籤列表很長,就需要花很長時間才能寫完。而關鍵詞引數keyword 可以讓你增加一個“與”關係的過濾器來簡化工作。
.find(tag, attributes, recursive, text, keywords)
同上
導航樹
.children
如果你只想找出子標籤,可以用.children 標籤:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for child in bsObj.find("table",{"id":"giftList"}).children:
print(child).next_siblings
BeautifulSoup 的next_siblings() 函式可以讓收集表格資料成為簡單的事情,尤其是處理帶標題行的表格:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)任何時候你獲取一個標籤的兄弟標籤,都不會包含這個標籤本身。其次,這個函式只調用後面的兄弟標籤。
.previous_sibling
如果你很容易找到一組兄弟標籤中的最後一個標籤, 那麼previous_siblings 函式也會很有用。
當然,還有next_sibling和previous_sibling 函式,與next_siblings 和previous_siblings的作用類似,只是它們返回的是單個標籤,而不是一組標籤。
.parent和.parents
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html)
print(bsObj.find("img",{"src":"../img/gifts/img1.jpg"
}).parent.previous_sibling.get_text())獲取屬性
.attrs
對於一個標籤物件,可以用下面的程式碼獲取它的全部屬性:
myTag.attrs
要注意這行程式碼返回的是一個Python 字典物件,可以獲取和操作這些屬性。比如要獲取圖
片的資源位置src,可以用下面這行程式碼:
myImgTag.attrs["src"]
Lambda表示式
BeautifulSoup允許我們把特定函式型別當作findAll 函式的引數。唯一的限制條件是這些函式必須把一個標籤作為引數且返回結果是布林型別。BeautifulSoup用這個函式來評估它遇到的每個標籤物件,最後把評估結果為“真”的標籤保留,把其他標籤剔除。
例如,下面的程式碼就是獲取有兩個屬性的標籤:
soup.findAll(lambda tag: len(tag.attrs) == 2)這行程式碼會找出下面的標籤:
<div class="body" id="content"></div>
<span style="color:red" class="title"></span>
如果你願意多寫一點兒程式碼,那麼在BeautifulSoup 裡用Lambda表示式選擇標籤,將是正則表示式的完美替代方案。
獲取資源
urllib.request.urlretrieve
可以根據檔案的URL下載檔案:
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com")
bsObj = BeautifulSoup(html)
imageLocation = bsObj.find("a",{"id":"logo"}).find("img")["src"]
urlretrieve(imageLocation, "logo.jpg")清洗下載地址並計算儲存路徑
import os
from urllib.request import urlretrieve
from urllib.request import urlopen
from bs4 import BeautifulSoup
downloadDirectory = "downloaded"
baseUrl = "http://pythonscraping.com"
def getAbsoluteURL(baseUrl, source):
if source.startswith("http://www."):
url = "http://"+source[11:]
elif source.startswith("http://"):
url = source
elif source.startswith("www."):
url = "http://"+source[4:]
else:
url = baseUrl+"/"+source
if baseUrl not in url:
return None
return url
def getDownloadPath(baseUrl, absoluteUrl, downloadDirectory):
path = absoluteUrl.replace("www.","")
path = path.replace(baseUrl, "")
path = downloadDirectory+path
directory = os.path.dirname(path)
if not os.path.exists(directory):
os.makedirs(directory)
return path
html = urlopen("http://www.pythonscraping.com")
bsObj = BeautifulSoup(html)
downloadList = bsObj.findAll(src=True)
for download in downloadList:
fileUrl = getAbsoluteURL(baseUrl, download["src"])
if fileUrl is not None:
print(fileUrl)
urlretrieve(fileUrl, getDownloadPath(baseUrl, fileUrl, downloadDirectory))用CSV儲存表格
import csv
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://en.wikipedia.org/wiki/Comparison_of_text_editors")
bsObj = BeautifulSoup(html, "html.parser")
#The main comparison table is currently the first table on the page
table = bsObj.findAll("table",{"class":"wikitable"})[0]
rows = table.findAll("tr")
csvFile = open("files/editors.csv", 'wt', newline='', encoding='utf-8')
writer = csv.writer(csvFile)
try:
for row in rows:
csvRow = []
for cell in row.findAll(['td', 'th']):
csvRow.append(cell.get_text())
writer.writerow(csvRow)
finally:
csvFile.close()
PyMySQL
要讓PyMySQL連上MySQL的話,預設情況下得用到sock檔案,
unix_socket='/var/run/mysqld/mysqld.sock'
否則要到
/etc/mysql/mysql.conf.d中修改mysqld.cnf檔案,將
bind-address = 127.0.0.1註釋掉,這時候就不用sock登入MySQL了。
import pymysql
coon = pymysql.connect(host='127.0.0.1',
user='root',
passwd='gmf1230132',
db='mysql',
charset='utf8')
cur = coon.cursor()
cur.execute("USE scraping")
cur.execute("SELECT * FROM pages WHERE id =1")
print(cur.fetchone())
cur.close()
coon.close()讓資料庫支援Unicode
ALTER DATABASE scraping CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE pages CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE title title VARCHAR(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE pages CHANGE content content VARCHAR(10000) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;用函式儲存資料
def store(title, content):
cur.execute("INSERT INTO pages (title, content) VALUES (\"%s\", \"%s\")", (title, content))
cur.connection.commit()CSV
StringIO(data)和csv.reader(dataFile)
由於CSV庫主要是面向本地檔案,就是說CSV檔案得儲存在電腦上,而進行網路資料採集的時候,很多檔案都是線上的。所以從網上直接把檔案讀成一個字串,然後轉換成StringIO物件,使它具有檔案的屬性:
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv").read().decode('ascii','ignore')
dataFile = StringIO(data)
csvReader = csv.reader(dataFile)
for row in csvReader:
print(row)csv.DictReader(dataFile)
會返回把CSV檔案每一行轉換成Python的字典物件返回,而不是列表物件,並儲存在dictReader.fieldnames裡,
from urllib.request import urlopen
from io import StringIO
import csv
data = urlopen("http://pythonscraping.com/files/MontyPythonAlbums.csv").read().decode('ascii','ignore')
dataFile = StringIO(data)
dictReader = csv.DictReader(dataFile)
print(dictReader.fieldnames)
for row in dictReader:
print(row)輸出:
['Name', 'Year']
{'Name': "Monty Python's Flying Circus", 'Year': '1970'}
{'Name': 'Another Monty Python Record', 'Year': '1971'}
{'Name': "Monty Python's Previous Record", 'Year': '1972'}PDF格式與PDFMiner3K
from urllib.request import urlopen
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from io import StringIO
from io import open
#下面的例子可以把任意 PDF 讀成字串,然後用 StringIO 轉換成檔案物件:
def readPDF(pdfFile):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparms = LAParams()
device = TextConverter(rsrcmgr, retstr, laparams=laparms)
process_pdf(rsrcmgr, device, pdfFile)
device.close()
content = retstr.getvalue()
retstr.close()
return content
pdfFile = urlopen("http://pythonscraping.com/pages/warandpeace/chapter1.pdf")
outputString = readPDF(pdfFile)
print(outputString)
pdfFile.close()DOCX格式
from zipfile import ZipFile
from urllib.request import urlopen
from io import BytesIO
from bs4 import BeautifulSoup
wordFile = urlopen("http://pythonscraping.com/pages/AWordDocument.docx").read()
wordFile = BytesIO(wordFile)
document = ZipFile(wordFile)
xml_content = document.read('word/document.xml')
wordObj = BeautifulSoup(xml_content.decode('utf-8'),'lxml')
textStrings = wordObj.findAll("w:t")
for textElem in textStrings:
closeTag = ""
try:
style = textElem.parent.previousSibling.find("w:pstyle")
if style is not None and style["w:val"] == "Title":
print("<h1>")
closeTag = "</h1>"
except AttributeError:
pass
print(textElem.text)
print(closeTag)資料清洗
n-gram
在語言學裡有一個模型叫n-gram,表示文字或語言中的n個連續的單片語成的序列。在進行自然語言分析時,使用n-gram或者尋找常用片語,可以很容易地把一句話分解成若干個文字片段。
def cleanInput(input):
input = re.sub('\n+', " ",input)
input = re.sub('\[[0-9]*\]',"",input)
input = re.sub(' +'," ",input)
input = bytes(input, "UTF-8")
input = input.decode("ascii", "ignore")
cleanInput = []
input = input.split(' ')
for item in input:
#string.punctuation獲取Python所有的標點符號,單詞兩端的任何標點符號都會被去掉
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() =='i'):
cleanInput.append(item)
return cleanInput
def ngrams(input, n):
input = cleanInput(input)
output=[]
for i in range(len(input)-n+1):
output.append(input[i:i+n])
return outputOpenRefine
安裝時要export JAVA_HOME=/usr/才可以執行./refine
用GREL清洗資料:(在Edit cells→transform裡)
if(value.length() != 4, "invalid", value)
OpenRefine 還有許多關於單元格編輯和 GERL 資料變換的方法。詳細介紹在 OpenRefine
的 GitHub 頁面。
自然語言處理
grams簡單的資料清理和化成2-grams
(可以直接from nltk import ngrams,通過使用ngrams(text,n)函式來生成ngrams)
def cleanInput(input):
input = re.sub('\n+'," ",input).lower()
input = re.sub('\[[0-9]*\]', "", input)
input = re.sub(' +', " ", input)
#input = input.decode("ascii", "ignore")
cleanInput = []
input = input.split(' ')
for item in input:
item = item.strip(string.punctuation)
if len(item) > 1 or (item.lower() == 'a' or item.lower() == 'i'):
cleanInput.append(item)
return cleanInput
def ngrams(input, n):
input = cleanInput(input)
output = {}
for i in range(len(input)-n+1):
ngramTemp = " ".join(input[i:i+n])
if ngramTemp not in output:
output[ngramTemp] = 0
output[ngramTemp]+=1
return output馬爾可夫鏈
from urllib.request import urlopen
from random import randint
def wordListSum(wordList):
sum = 0
for word, value in wordList.items():
sum += value
return sum
def retrieveRandomWord(wordList):
randIndex = randint(1, wordListSum(wordList))
for word, value in wordList.items():
randIndex -= value
if randIndex <=0:
return word
def buildWordDict(text):
#剔除換行符和引號
text = text.replace("\n", " ")
text = text.replace("\"","")
#保證每個標點符號都和前面的單詞在一起
#這樣不會被剔除,保留在馬爾可夫鏈中
punctuation = [',','.',';',':']
for symbol in punctuation:
text = text.replace(symbol, " "+symbol+" ")
words = text.split(" ")
#過濾空單詞
words = [word for word in words if word != ""]
wordDict = {}
for i in range(1,len(words)):
if words[i-1] not in wordDict:
wordDict[words[i-1]]={}
if words[i] not in wordDict[words[i-1]]:
wordDict[words[i-1]][words[i]] = 0
wordDict[words[i-1]][words[i]] = wordDict[words[i-1]][words[i]] + 1
return wordDict
text = str(urlopen("http://pythonscraping.com/files/inaugurationSpeech.txt").read(), 'utf-8')
wordDict = buildWordDict(text)
#生成鏈長位100的馬爾可夫鏈
length = 100
chain =""
currentWord = "I"
for i in range(0,length):
chain += currentWord+" "
currentWord = retrieveRandomWord(wordDict[currentWord])
print(chain)buildWordDict 函式把網上獲取的演講文字的字串作為引數,然後對字串做一些清理和格式化處理,去掉引號,把其他標點符號兩端加上空格,這樣就可以對每一個單詞進行有效的處理。最後,再建立如下所示的一個二維字典——字典裡有字典:
{word_a : {word_b : 2, word_c : 1, word_d : 1},
word_e : {word_b : 5, word_d : 2},…}
如果我們要畫出這個結果的節點模型,那麼“word_a”可能就有帶 50% 概率的箭頭指向“word_b”(四次中的兩次),帶25%概率的箭頭指向“word_c”,還有帶 25% 概率的箭頭指向“word_d”。
一旦字典建成,不管你現在看到了文章的哪個詞,都可以用這個字典作為查詢表來選擇下一個節點。這個字典的字典是這麼使用的,如果我們現在位於“word_e”節點,那麼下一步就要把字典 {word_b : 5, word_d : 2}傳遞到retrieveRandomWord函式。這個函式會按照字典中單詞頻次的權重隨機獲取一個單詞。
廣度優先搜尋
class SolutionFound(RuntimeError):
def __init__(self, message):
self.message = message
def getLinks(fromPageId):
cur.execute("SELECT toPageId FROM links WHERE fromPageId = %s", (fromPageId))
if cur.rowcount == 0:
return None
else:
return [x[0] for x in cur.fetchall()]
def constructDict(currentPageId):
links = getLinks(currentPageId)
if links:
return dict(zip(links, [{}]*len(links)))
return {}
#連結要麼位空,要麼包含多個連結
def searchDepth(targetPageId, currentPageId, linkTree, depth):
if depth == 0:
return linkTree
if not linkTree:
linkTree = constructDict(currentPageId)
if not linkTree:
return {}
if targetPageId in linkTree.keys():
print("TARGET "+str(targetPageId)+" FOUND!")
raise SolutionFound("PAGE: "+str(currentPageId))
for branchKey, branchValue in linkTree.items():
try:
# 遞迴建立連結樹
linkTree[branchKey] = searchDepth(targetPageId, branchKey, branchValue, depth-1)
except SolutionFound as e:
print(e.message)
raise SolutionFound("PAGE: "+str(currentPageId))
return linkTree
try:
searchDepth(134951, 1, {}, 4)
print("No solution found")
except SolutionFound as e:
print(e.message)穿越網頁表單與登入視窗進行採集
在Python中用Selenium執行JavaScript與Selenium的選擇器說明
Selenium 可以讓瀏覽器自動載入頁面,獲取需要的資料,甚至頁面截圖,或者判斷網站上某些動作是否發生。
PhantomJS 是一個“無頭”(headless)瀏覽器。它會把網站載入到記憶體並執行頁面上的JavaScript,但是它不會向用戶展示網頁的圖形介面。把Selenium 和PhantomJS結合在一起,就可以執行一個非常強大的網路爬蟲了,可以處理cookie、JavaScrip、header,以及任何你需要做的事情。
from selenium import webdriver
import time
#注意設定路徑的時候要先把路徑帶r賦值給一個變數再使用
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(
executable_path=phantomjs_path)
driver.get("http://pythonscraping.com/pages/javascript/ajaxDemo.html")
time.sleep(3)
print(driver.find_element_by_id('content').text)
driver.close()
Selenium的隱式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(
executable_path=phantomjs_path)
driver.get("http://pythonscraping.com/pages/javascript/ajaxDemo.html")
#WebDriverWait和expected_conditions兩個模組組合起來構成了Selenium的隱式等待
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.ID, "loadedButton")))
finally:
print(driver.find_element_by_id("content").text)
driver.close()隱式等待與顯式等待的不同之處在於,隱式等待是等DOM 中某個狀態發生後再繼續執行程式碼(沒有明確的等待時間,但是有最大等待時限,只要在時限內就可以),而顯式等待明確設定了等待時間,如前面例子的等待三秒鐘。在隱式等待中,DOM 觸發的狀態是用expected_conditions定義的(這裡匯入後用了別名EC,是經常使用的簡稱)。在Selenium庫裡面元素被觸發的期望條件(expected condition)有很多種,包括:
• 彈出一個提示框
• 一個元素被選中(比如文字框)
• 頁面的標題改變了,或者某個文字顯示在頁面上或者某個元素裡
• 一個元素在DOM 中變成可見的,或者一個元素從DOM 中消失了
如果你可以不用定位器,就不要用,畢竟這樣可以少匯入一個模組。但是,定位器是一種十分方便的工具,可以用在不同的應用中,並且具有很好的靈活性。
下面是定位器通過By 物件進行選擇的策略。
• ID
在上面的例子裡用過;通過HTML 的id 屬性查詢元素。
• CLASS_NAME
通過HTML的class屬性來查詢元素。為什麼這個函式是CLASS_NAME,而不是簡單的CLASS?在Selenium 的Java 庫裡使用object.CLASS可能會出現問題,.class是Java保留的一個方法。為了讓Selenium 語法可以相容不同的語言,就用CLASS_NAME 代替。
• CSS_SELECTOR
通過CSS 的class、id、tag 屬性名來查詢元素,用#idName、.className、tagName表示。
• LINK_TEXT
通過連結文字查詢HTML 的標籤。例如,如果一個連結的文字是“Next”,就可以用(By.LINK_TEXT, “Next”) 來選擇。
• PARTIAL_LINK_TEXT
與LINK_TEXT 類似,只是通過部分連結文字來查詢。
• NAME
通過HTML 標籤的name 屬性查詢。這在處理HTML 表單時非常方便。
• TAG_NAME
通過HTML 標籤的名稱查詢。
• XPATH
用XPath 表示式(語法在下面介紹)選擇匹配的元素。


XPATH入門說明
使用正則表示式處理XPATH採集標籤
page = driver.find_elements_by_xpath(
'//tbody[starts-with(@id,"normalthread_")]')處理重定向
我們可以用一種智慧的方法來檢測客戶端重定向是否完成,首先從頁面開始載入時就“監視”DOM 中的一個元素, 然後重複呼叫這個元素直到Selenium丟擲一個StaleElementReferenceException 異常;也就是說,元素不在頁面的DOM 裡了,說明這時網站已經跳轉:
from selenium import webdriver
import time
from selenium.webdriver.remote.webelement import WebElement
from selenium.common.exceptions import StaleElementReferenceException
def waitForLoad(driver):
elem = driver.find_element_by_tag_name("html")
count = 0
while True:
count += 1
# 檢測該driver十秒鐘,當檢測不到html標籤時丟擲異常
if count > 20:
print("Timing out after 10 seconds and returning")
return
time.sleep(.5)
# 每隔半秒鐘檢查一次html標籤還在不在,時限為10秒鐘,不在的時候會丟擲異常,然後結束函式
try:
elem == driver.find_element_by_tag_name("html")
except StaleElementReferenceException:
return
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(executable_path=phantomjs_path)
driver.get("http://pythoncraping.com/pages//javascript/redirectDemo1.html")
waitForLoad(driver)
print(driver.page_source)
#輸出結果
Timing out after 10 seconds and returning
<html><head></head><body></body></html>影象識別與文書處理
from PIL import Image, ImageFilter
pic = Image.open("avatar.jpg")
blurryAvatar = pic.filter(ImageFilter.GaussianBlur)
blurryAvatar.save("avatar_blurred.jpg")
blurryAvatar.show()Tesseract 是一個Python的命令列工具,安裝之後,要用tesseract命令在Python的外面執行。
中文庫也在github中,名字為chi_sim,放到tesseract-ocr安裝目錄下的tessdata 目錄。
需要新增環境變數到PATH: C:\Program Files (x86)\Tesseract-OCR
和TESSDATA_PREFIX:C:\Program Files (x86)\Tesseract-OCR
$tesseract text.tif textoutput
使用pillow過濾掉漸變的背景色,呼叫命令列執行tesseract(subprocess)
from PIL import Image
import subprocess
def cleanFile(filePath, newFilePath):
image = Image.open(filePath)
%常見的過濾方式,將圖片處理成高對比度圖片
image = image.point(lambda x: 0 if x < 143 else 255)
image.save(newFilePath)
subprocess.call(["tesseract", newFilePath, "output"])
outputFile = open("output.txt", 'r')
print(outputFile.read())
outputFile.close()
cleanFile("text_2.jpg", "text_2_clean.png")
執行結果:
>> & python d:/Library/PythonScrapy/pillowtest.py
Tesseract Open Source OCR Engine v4.00.00alpha with Leptonica
Warning. Invalid resolution 0 dpi. Using 70 instead.
This is some text. written in Arial, that will be read by
Tesseract Here are some symbols: !@#$%"&*()使用Tesseract爬取ajax圖片並進行分析(程式碼不可用,amazon標籤已修改)
import time
from urllib.request import urlretrieve
import subprocess
from selenium import webdriver
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(executable_path=phantomjs_path)
driver.get("http://www.amazon.com/War-Peace-Leo-Nikolayevich-Tolstoy/dp/1427030200")
time.sleep(2)
# 單機圖書預覽按鈕
driver.find_element_by_id("sitbLogoImg").click()
imageList = set()
# 等待頁面載入完成
time.sleep(5)
# 當向右箭頭可以點選時,開始翻頁
while "pointer" in driver.find_element_by_id("sitbReaderRightPageTurner").get_attribute("style"):
driver.find_element_by_id("sitbReaderRightPageTurner").click()
time.sleep(2)
# 獲取已載入的新頁面(一次可以載入多個頁面,但是重複的頁面不能載入到集合中)
pages = driver.find_elements_by_xpath("//div[@class='pageImage']/div/img")
for page in pages:
image = page.get_attribute("src")
imageList.add(image)
driver.quit()
# 用Tesseract處理我們收集的圖片URL連結
for image in sorted(imageList):
urlretrieve(image, "page.jpg")
p = subprocess.Popen(["tesseract", "page.jpg", "page"],
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
p.wait()
f = open("page.txt", "r")
print(f.read())一個圖片的矩形定位檔案如下所示:

第一列符號是圖片中的每個字元,後面的4個數字分別是包圍這個字元的最小矩形的座標(圖片左下角是原點(0,0),4 個數字分別對應每個字元的左下角x 座標、左下角y 座標、右上角x 座標和右上角y 座標),最後一個數字“0”表示圖片樣本的編號。
矩形定位檔案必須儲存在一個.box字尾的文字檔案中。和圖片檔案一樣,文字檔案也是用驗證碼的實際結果命名(例如,4MmC3.box)
訓練完成後把eng.trainedddata複製到C:\Program Files (x86)\Tesseract-OCR\tessdata下即可
避開採集陷阱
呼叫requests庫的session來傳遞cookie
import requests
from bs4 import BeautifulSoup
session = requests.Session()
headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5)
AppleWebKit 537.36 (KHTML, like Gecko) Chrome",
"Accept":"text/html,application/xhtml+xml,application/xml;
q=0.9,image/webp,*/*;q=0.8"}
url = "https://www.whatismybrowser.com/developers/what-http-headers-is-my-browser-sending"
req = session.get(url, headers=headers)
bsObj = BeautifulSoup(req.text)
print(bsObj.find("table",{"class":"table-striped"}).get_text)呼叫driver的get_cookie()、delete_cookie()、add_cookie()、delete_all_cookies()方法
from selenium import webdriver
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(phantomjs_path)
driver.get("http://pythonscraping.com")
driver.implicitly_wait(1)
print(driver.get_cookies())判斷哪些元素是陷阱(包含從一個元素獲取另外一個屬性的值的方法,get_attribute)
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(phantomjs_path)
driver.get("http://pythonscraping.com/pages/itsatrap.html")
links = driver.find_elements_by_tag_name("a")
for link in links:
if not link.is_displayed():
#從顯示不了的a標籤中獲取href屬性
print("The link " + link.get_attribute("href") + " is a trap")
fields = driver.find_elements_by_tag_name("input")
for field in fields:
if not field.is_displayed():
print("Do not change value of " + field.get_attribute("name"))
driver.implicitly_wait(1)
print(driver.get_cookies())
執行結果:
The link http://pythonscraping.com/dontgohere is a trap
Do not change value of phone
Do not change value of email使用Selenium與網站進行互動
myElement.click()
myElement.click_and_hold()
myElement.release()
myElement.double_click()
myElement.send_keys_to_element("content to enter")為了一次性完成一個元素的多個操作,可以用動作鏈(actionchain)儲存多個操作,然後在一個程式中執行一次或多次。
填寫表單的兩種方法(send_keys和ActionChains)
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(phantomjs_path)
driver.get("http://pythonscraping.com/pages/files/form.html")
firstnameField = driver.find_element_by_name("firstname")
lastnameField = driver.find_element_by_name("lastname")
submitButton = driver.find_element_by_id("submit")
# 方法1
firstnameField.send_keys("Ryan")
lastnameField.send_keys("Mitchell")
submitButton.click()
# 方法2
actions = ActionChains(driver).click(firstnameField).send_keys("Ryan") \
.click(lastnameField).send_keys("Mitchell") \
.send_keys(Keys.RETURN)
actions.perform()
print(driver.find_element_by_tag_name("body").text)滑鼠拖放動作
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
from selenium.webdriver.common.keys import Keys
from selenium.webdriver import ActionChains
phantomjs_path = r"D:\Library\PythonScrapy\phantomjs-2.1.1-windows\bin\phantomjs.exe"
driver = webdriver.PhantomJS(phantomjs_path)
driver.get("http://pythonscraping.com/pages/javascript/draggableDemo.html")
print(driver.find_element_by_id("message").text)
element = driver.find_element_by_id("draggable")
target = driver.find_element_by_id("div2")
actions = ActionChains(driver)
actions.drag_and_drop(element, target).perform()
print(driver.find_element_by_id("message").text)截圖
driver.get_screenshot_as_file('tmp/pythonscraping.png')博主隨便說說
這個學期比較忙,抽了幾個週末的空看完了這本兩百多頁的,可以算是爬蟲入門的書籍,比較讓人失望的一點是書中並沒有提及有關多執行緒、併發爬蟲的內容,博主接下來打算去了解有關scrapy的資料。同時也很感謝這本書能帶給我這些基礎知識。如果我整理的操作清單中有什麼不對的地方,歡迎大家指出!謝謝大家!
參考資料:
《Python網路資料採集》
相關推薦
[python] 網路資料採集 操作清單 BeautifulSoup、Selenium、Tesseract、CSV等
Python網路資料採集操作清單 BeautifulSoup、Selenium、Tesseract、CSV等 常用正則表示式清單 常用正則表示式符號 電子郵箱 [A-Za-z0-9\._+][email pr
初識python爬蟲 Python網路資料採集1.0 BeautifulSoup安裝測試
*文章說明這個學習資料是Ryan Mitchel的著作<Web Scraping with Python: Collecting Data from the Modern Web>我算是一步一步跟著一起去學習。分享自及遇到的問題。總結*環境說明我使用的是pytho
Python網路資料採集 pdf下載
網路上的資料量越來越大,單靠瀏覽網頁獲取資訊越來越困難,如何有效地提取並利用資訊已成為一個巨大的挑戰。本書採用簡潔強大的Python語言,全面介紹網路資料採集技術,教你從不同形式的網路資源中自由地獲取資料。你將學會如何使用Python指令碼和網路API一次性採集並處理成千上萬個網頁上的資料。&
Python網路資料採集(爬蟲)
寫程式碼之前擬個大綱或畫個流程圖是很好的程式設計習慣,這麼做不僅可以為你後期處理節省 很多時間,更重要的是可以防止自己在爬蟲變得越來越複雜時亂了分寸。(自己當產品經理) 新增處理異常會讓程式碼更好體驗,在寫爬蟲的時候,思考程式碼的總體格局,讓程式碼既可以捕捉異常又容
python網路資料採集-第5章儲存資料
5.1 媒體檔案簡述 網路上的資源很多,有圖片,視訊,常規檔案rar\zip等,由於網路爬去的資料量大,如果直接儲存,相對只儲存對應的連結字串,有很多缺陷:1、由於下載,導致爬取速度慢;2、消耗儲存空間;3、而且還要實現檔案下載的方法,繁瑣;優點:1、防
Python網路資料爬取----網路爬蟲基礎(一)
The website is the API......(未來的資料都是通過網路來提供的,website本身對爬蟲來講就是自動獲取資料的API)。掌握定向網路資料爬取和網頁解析的基本能力。 ##Requests 庫的使用,此庫是Python公認的優秀的第三方網路爬蟲庫。能夠自動的爬取HTML頁面;自動的
Selenium-網路資料採集工具庫-初學篇
目錄 庫介紹 Selenium是一個強大的網路資料採集工具(http://www.seleniumhq.org/),最初是為網站自動化測試而開發,同時也它們也可以執行在瀏覽器上。在Python中應用功能主要如下: 讓瀏覽器自動載入頁面 獲取瀏覽器網頁載入的資料
Python常用資料夾操作
@[email protected]/? 匯入os庫 import os 檢測某路徑是否存在 if not os.path.exists(path): 建立某路徑 os.makedirs(path)
爬蟲--網路資料採集
用一週的時間翻完了python網路資料採集,在此整理一下。 0x000資料採集 資料採集是一個很寬泛的概念,總的來說應該包含以下部分。 選擇採集目標源–>組織構建資料庫–>編寫爬蟲–>資料清洗–>資料整理–>存入資料庫,一般情
Python核心資料型別之序列型別及其運算(字元、列表、元組運算及其深淺拷貝)
Python核心資料型別之序列型別及其運算(列表、元組運算及其拷貝)序列:序列表示索引為非負整數的有序物件集合,包括字串、列表和元組,所有序列都支援迭代;序列型別:字串(strings):字串也屬於序列型別,不可變型別; 字串字面量:把文字放入單引號、雙引號或
scapy:網路資料包操作
scapy 是具有超強功能的資料包操作工具,不僅具有無數個協議的解碼功能,還可以 傳輸修改後的資料包.scapy的最大特點就是可以執行多種功能。例如:建立網路掃描、資料包轉儲、資料包攻擊時需要利用多個不同的工具,而只要一個scapy就夠了。 Welcome t
python網路資料探勘--JS隱式等待和顯式等待
第一部分:隱式等待和顯式等待 隱式等待和顯式等待的不同之處在於,隱式等待是等DOM中某個狀態發生改變後再繼續執行程式碼(沒有明確的等待時間,但是有最大等待期限,只要在時限內就可以),而顯式等待明確設定了等待時間,如上篇文章中等待三秒鐘。在隱式等待中,DOM被觸發的
Web自動化必會知識:「Web基礎、元素定位、元素操作、Selenium執行原理、專案實戰+框架」
1.web 基礎-html、dom 物件、js 基本語法 Dom 物件裡面涉及元素定位以及對元素的修改。因為對元素操作當中涉及的一些 js 操作,js 基本語法要會用。得要掌握前端的基本用法。為什麼要元素定位?因為找到這個元素,就能告訴程式碼要找誰要做什麼。 2.元素定位 四大基本元素定位:id name c
Linux基礎02:磁碟操作,檔案許可權、檔案及資料夾操作、網路服務
1.Linux磁碟與U盤操作 1.1 顯示系統的磁碟空間用量 ##du命令也是檢視使用空間的,但是與df命令不同的是Linux du命令是對檔案和目錄磁碟使用的空間的檢視 du -sh ##查目錄使用大小(-s表示總結) ## du -sh /bin ##df命令用於顯示磁碟分割槽
24、python對資料框進行分組統計簡單操作
分組分析:是指根據分組欄位,將分析物件劃分成不同的部分,已進行對比分析各組之間的差異性的一種分析方法 常見的統計指標: 計數 求和 平均值 1 函式 01 分組統計函式: groupby(by=[分組列1,分組列2,...])[統計列1,統計列2,。。。] .agg({統計列名1:統計函
python網路爬蟲-資料採集之遍歷單個爬蟲
之所以稱之為爬蟲(Web Carwler)是因為它們可以沿著網路爬行。它們的本質就是一種遞迴方式。為了找到URL連結,它們必須首先獲取網頁內容,檢查這個頁面的內容,在尋找另外一個URL,然後後獲取URL對應的網頁內容,不斷迴圈這一過程。不過要注意的是:你可以這樣重
python資料儲存系列教程——python操作sqlite資料庫:連線、增刪查改、指令執行
全棧工程師開發手冊 (作者:欒鵬) python操作sqlite資料庫 sqlite資料庫以.db格式的檔案形式存在,所以不需要安裝驅動和應用系統,在標準庫中也集成了sqli
python應用系列教程——python使用scapy監聽網路資料包、按TCP/IP協議進行解析
全棧工程師開發手冊 (作者:欒鵬) python使用scapy監聽抓取網路資料包。 scapy具有模擬傳送資料包、監聽解析資料包、網際網路協議解析、資料探勘等多種用處。這裡我們只來說一下scapy監聽資料包,並按照不同的協議進行解析。
Python網路爬蟲--歷史天氣資料採集
在很多機器學習應用中,天氣資料為重要的輔助特徵資料,故本文主要介紹如何利用Python獲取歷史天氣資料。 目標網站 資料爬取的目標網站為天氣網 程式設計實現 匯入相關包 import requests # 匯入reques
python股票資料爬蟲requests、etree、BeautifulSoup學習
最近在研究股票資料回測(其實想做量化交易),但是能直接提供資料的API都不太穩定(tushare超時,雅虎的要修復才能用,也不太穩定) #雅虎股票資料API的修復包 from pandas_datareader import data as pdr imp