
java基礎知識學習筆記(三)
Java集合
引言
在實現某個方法時,選擇不同的資料結構,程式碼的簡潔性與時間效率會有所不同,根據需要,選擇合適的資料結構解決問題。比如要搜尋很大資料量但是有序的資料(陣列),或者在序列中間插入一個或刪除一個元素(連結串列),或者需要建立鍵與值的關係(map),等等。以上一些資料結構在java中如何實現的?
介面的概念
在介紹介面之前,先給出一個java的集合框架圖
簡單說明一下:
短虛線表示的矩形框:介面(8個,下面的兩個不屬於集合範疇,不算)。
長虛線表示的矩形框:抽象類(5個),對介面的部分實現,方便類庫的實現者。介面的方法很多,都實現太麻煩了,而抽象類中實現了介面的部分方法,只要在此基礎上擴充套件就可以了。
實線表示的矩形框:實現類(10 抽象類可以不必掌握,對於使用者而言(實現者可以看看),所以可以把上面的框架圖簡化一下
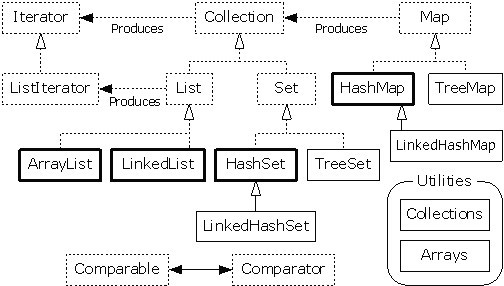
對比上圖說明一下:
抽象類去掉了,我們不考慮
標有legacy的也去掉了,遺留問題後面再講
SortedSet,SortedMap,WeakHashMap去掉了
增加了LinkedHashSet,LinkedHashMap
這5個實現類後面會講到現在基本框架清晰了,開始講介面。
介面與實現分離
java集合類將介面與實現分離,這是一種設計模式,介面模式或橋接模式,這裡不細講,感興趣可以看看大話設計模式。舉個簡單例子,常見的佇列(queue),在java中如何實現的呢?
interface Queue<E>//standard library
{
void add(Element e);
E remove();
int size();
}介面只是定義了佇列,並沒有講佇列如何實現。在java集合中佇列有兩種實現方式,就是前面的框架圖中的ArrayDeque和LinkedList,為什麼會是兩種呢?
在這裡引入一些資料結構的知識,幫助理解佇列的實現。
佇列作為一種線性表,儲存方式(即實現方式)有兩種,順序儲存和鏈式儲存。先來看順序儲存。
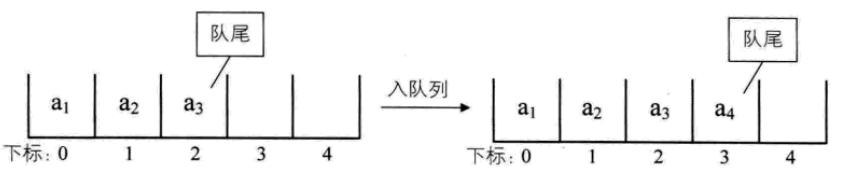
假設佇列中有n個元素,則順序儲存需要建立一個大於n的陣列,把n個元素放在前n個位置,後面的空間方便新增元素。此時隊頭指向下標為0的元素。
入隊:就是在隊尾加一個元素,O(1)
出隊:移除隊頭元素,並將後面的元素前移,O(n)
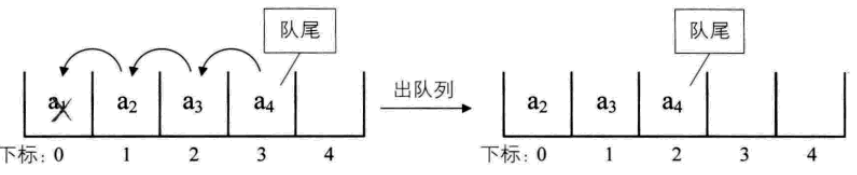
這就好比現實中排隊買票,前面的人買好走了,後面的人自然要補上。但我們希望提高效能,如果不限制前n個位置儲存元素(隊頭不固定在下標0),這樣就不用移動後面的元素

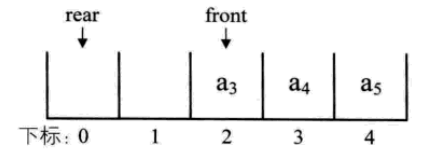
這樣的話就需要兩個指標:front,rear
比如,長度為5陣列,初始佇列為空,front和rear指向下標0。然後a1,a2,a3,a4依次入隊

出隊a1,a2。然後入隊a5

發現問題了,此時rear指向什麼地方?
此時佇列元素少於5個,但隊尾已被佔用,如果繼續入隊新元素,則會產生陣列越界的錯誤,但前面0,1位置都是空的,這就是所謂的“假溢位”
如果你坐公交車,發現後排座位已滿,但前面還有座位,你會怎麼辦?下車,然後說公交車滿了,等下一班車嗎?顯然沒有人會這麼傻。
以上例子就是為了說明,陣列方式實現佇列,顯然缺陷太多,所以資料結構裡面提供了一種迴圈佇列的方式。
前面的問題可以這樣解決
此時入隊a6,a7

這裡有個問題:佇列空,front==rear。現在佇列滿,front==rear
解決:
方法一:設定一個flag,
當front==rear,flag==0時,為空
當front==rear,flag==1時,為滿
方法二:保留一個空間
這個時候,我們認為佇列已經滿了。
左邊圖:(rear+1)%QueueSize==front
右邊圖:(rear+1)==front
總結:(rear+1)%QueueSize==front時,佇列滿
佇列的實際長度
左邊圖:rear>fornt,長度為rear-fornt
右邊圖:rear<fornt,長度為(QueueSize-front)+(rear-0)=rear-fornt+QueueSize
總結:長度為:(rear-fornt+QueueSize)%QueueSize至於佇列的連結串列實現,不再講了,就是單鏈表,想看的同學可以去看看大話資料結構。
總之佇列的實現無外乎就是以上講的兩種:迴圈陣列和連結串列
class CircleArrayQueue<E> implements Queue<E>//只是舉個例子
{
CircleArrayQueue(int capacity){...}
public void add(Element e){...}
public E remove(){...}
public int size(){...}
private E[] elements;
private int head;
private int tail;
...
}
class LinkedListQueue<E> implements Queue<E>//舉個例子
{
LinkedListQueue(){...}
public void add(Element e){...}
public E remove(){...}
public int size(){...}
private Link head;
private Link tail;
...
}其實java類庫中沒有CircleArrayQueue和LinkedListQueue,只是為了解釋一下介面和實現分離這個概念,實際上,java中queue的實現是ArrayDeque類和LinkedList類,他們都實現了Queue介面。
介面與實現分離的好處?
Queue<E> queue=new CircleArrayQueue<E>();
queue.add(...);
如果想換成另外一種實現,只需
Queue<E> queue=new LinkedListQueue<E>();
...
介面中存放的是集合的引用。Collection介面與Iterator介面
集合類的基本介面是Collection介面。兩個基本方法:
public interface Collection<E>
{
boolean add(E element);
Iterator<E> iterator();
...
}add()方法向集合中加入元素,如果改變了集合,返回true,否則返回false。比如,新增一個元素,集合中已經存在,則不會新增即不改變集合,返回false,因為集合不允許相同元素。
iterator()方法,返回一個實現Iterator介面的迭代器
public interface Iterator<E>
{
E next();
boolean hasNext();
void remove();
}next()方法:逐個訪問集合中的元素,若到達集合末尾,丟擲NoSuchElementException。
hasNext()方法:如果迭代器物件還有供訪問的元素,返回true
例如,遍歷一個集合的話,可以這樣使用
Collection<String> c=...;
Iterator<String> iter=c.iterator();
while(iter.hasNext()){
String element=iter.next();
System.out.println(element);
}或者for each
for(String element:c)
{
System.out.println(element);
}
for each可以和任何實現了Iterable介面的物件一起使用
public interface Iterable<E>
{
Iterator<E> iterator();
}
Collection擴充套件了Iterable介面,所以集合物件都可以使用for eachjava集合中迭代器的實現是怎樣的?
比如,c++中,迭代器是根據陣列索引建模的。給你一個迭代器,可以檢視指定位置上的元素,就像知道陣列索引i就可以檢視陣列元素a[i]一樣。迭代器向前移動,不需要檢視元素,就像通過i++將索引向前移動一樣。
但是java中的迭代器和上面是有區別的。查詢一個元素只能通過next方法,而且執行查詢的同時,迭代器向前移動。迭代器位於兩個元素之間。
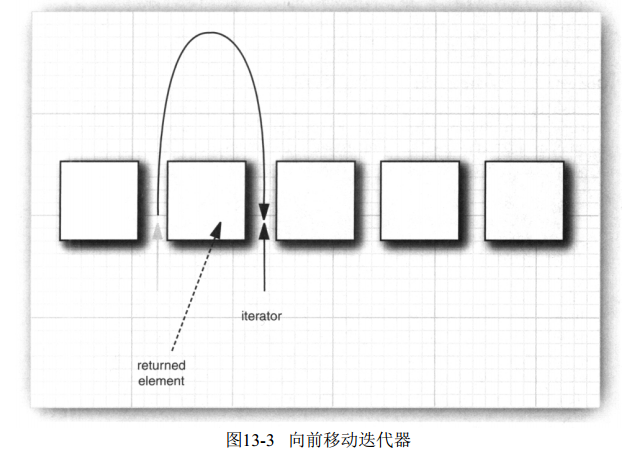
remove方法:刪除呼叫next返回的元素(就好像刪除之前,看一下刪除元素,還是有必要的),而且必須先next,才能刪除
Iterator<String> it=c.iterator();
it.next();//skip the first element
it.remove();//remove it
it.remove();
it.remove();//error
it.remove();
it.next();
it.remove();//ok下面給出Collection介面和Iterator介面的API
java.util.Collection<E> 1.2• Iterator<E> iterator()
返回一個用於訪問集合中每個元素的迭代器。
• int size()
返回當前儲存在集合中的元素個數。
• boolean isEmpty()
如果集合中沒有元素,返回true。
• boolean contains(Object obj)
如果集合中包含了一個與obj 相等的物件,返回true。
• boolean containsAll(Collection<?> other)
如果這個集合包含other集合中的所有元素,返回true。
• boolean add(Object element)
將一個元素新增到集合中。如果由於這個呼叫改變了集合,返回true。
• boolean addAll(Collection<? extends E> other)
將other集合中的所有元素新增到這個集合。如果由於這個呼叫改變了集合,返回true。
• boolean remove(Object obj)
從這個集合中刪除等於 obj 的物件。如果有匹配的物件被刪除,返回true。
• boolean removeAll(Collection<?> other)
從這個集合中刪除other集合中存在的所有元素。如果由於這個呼叫改變了集合,返回true。
• void clear()
從這個集合中刪除所有的元素。
• boolean retainAll(Collection<?> other)
從這個集合中刪除所有與other集合中的元素不同的元素。如果由於這個呼叫改變了集合,
返回true。
• Object[] toArray()
返回這個集合的物件陣列。
• <T> T[] toArray(T[] arrayToFill)
返回這個集合的物件陣列。如果arrayToFill足夠大,就將集合中的元素填入這個陣列中。
剩餘空間填補null;否則,分配一個新陣列,其成員型別與arrayToFill的成員型別相同,
其長度等於集合的大小,並添入集合元素。java.util.Iterator<E> 1.2• boolean hasNext()
如果存在可訪問的元素,返回true。
• E next()
返回將要訪問的下一個物件。如果已經到達了集合的尾部,將丟擲一個NoSuchElement
Exception。
• void remove()
刪除上次訪問的物件。這個方法必須緊跟在訪問一個元素之後執行。如果上次訪問之後,
集合已經發生了變化,這個方法將丟擲一個IllegalStateException。具體集合(實現類)
上面介面,只講了兩個:Collection和Iterator,那其餘的:List、Set、Map、ListIterator介面都沒講到,接下來會先將他們的實現類然後在去看這些上層介面。
先給出一個java集合實現類列表

簡單說明一下
除了以Map結尾的類之外,其他類都實現了Collection 介面。而以Map結尾的類實現了Map介面連結串列(LinkedList),有序的
在java中連結串列是雙向的,通過LinkedList(實現List介面)實現,舉個例子:
List<String> staff=new LinkedList<String>();//implements list
staff.add("aaa");
staff.add("bbb");
staff.add("ccc");
Iterator iter=list.iterator();
String first=iter.next();//visit first element
String second=iter.next();
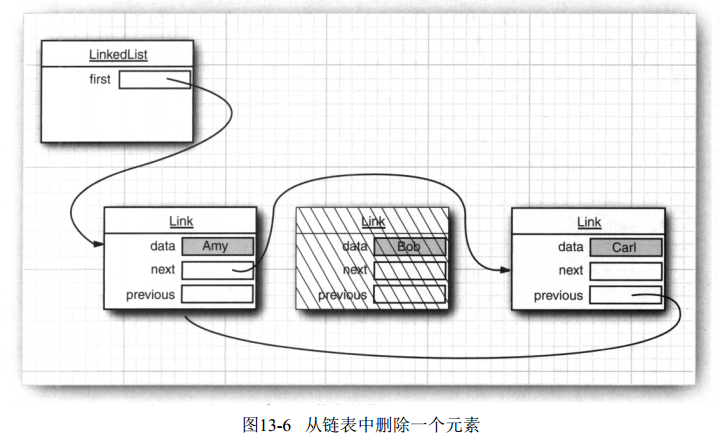
iter.remove();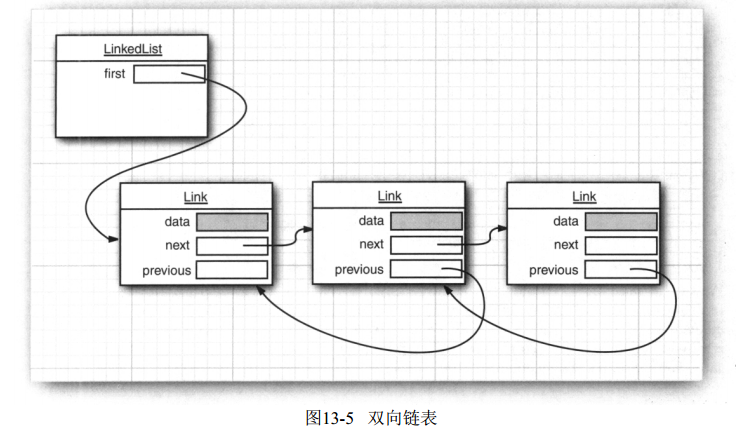
ListIterator介面
連結串列是有序集合,如果使用LinkedList.add方法會新增到連結串列末尾,而有時我們希望新增到連結串列中間,這個時候就需要藉助迭代器實現,所以在迭代器中就過載了add方法。當然如果集合無序的話,元素的位置就不重要了,就沒有所謂的末尾和中間,所以不是所有的迭代器都需要過載add方法,於是產生了一個子介面ListIterator介面。
public interface ListIterator<E> extends Iterator<E>
{
void add(Element e);//新增元素到當前迭代器之前
E previous();
boolean hasPrevious();
//following extends Iterator method
E next();
boolean hasNext();
void remove();
void set(Element e);
}與Collection.add方法有不同之處:返回值是void,Collection.add返回值是boolean。除此之外還有
E previous();//返回越過的物件
boolean hasPrevious();這兩個方法,可以反向遍歷連結串列。
而LinkedList類中的listIterator方法返回一個實現了ListIterator介面的迭代器物件
ListIterator<String> iter=list.listIterator();Note:void add()方法
它的新增位置有以下幾種(假設已有三個元素)
|ABC,A|BC,AB|C,ABC|看前面的java集合框架圖,LinkedList類是繼承自AbstractList,AbstractList又繼承自AbstractCollection類,簡而言之LinkedList繼承自超類AbstractCollection類,在超類裡面實現了一些對連結串列操作有用的方法,比如toString方法,返回中括號括起來的逗號分開的一串字元[a,b,c]。也可以判斷連結串列中是否包含一個字串,使用list.contains(“aa”)。
當然也有一些看似有歧義的方法,因為連結串列是不支援隨機訪問的,查詢一個元素只能通過next方法返回越過的元素,但是LinkedList類還是給出了一個用來訪問特定元素的get方法
LinkedList<String> list=...;
String obj=list.get(i);但其實這個方法的實現還是用遍歷的思想得到的,只不過做了一些優化,比如索引>size()/2時,會從後反向遍歷(previous方法)。
陣列列表(ArrayList)
連結串列的實現已經說了,現在說一下陣列的實現。java集合框架圖中有兩種陣列的實現:Vector和ArrayList,兩者區別是什麼?
Vector:方法都是同步的,可以有兩個執行緒安全訪問一個Vector物件
ArrayList:當一個執行緒訪問Vector物件時,在同步操作上會耗費大量的時間(這是不必要的),這種情況也是很常見的,故出現了ArrayList類。雜湊集(hashSet)
前面講到連結串列作用是方便元素插入刪除方便,不用移動大量元素。陣列作用是根據索引可以隨機查詢指定元素,且效率相對連結串列較高。那雜湊集的作用是什麼?
當我們忘記一個元素的索引時 ,如何快速找到給定元素。即給定元素—>索引。一般方法:搜尋所有元素,若元素較多時,顯然耗費時間。
散列表就是一種可以快速找到要找物件的一種結構,通過物件的雜湊碼。
雜湊碼是由物件的例項域產生的一個整數,更準確地說,具有不同資料域的物件產生的雜湊碼不同,如圖所示的雜湊碼是String類的hasCode方法產生的。

如果自定義類,就要負責實現這個類的hashCode方法。注意,自己實現的hashCode方法應該與equals方法相容,即如果a.equals(b)為true, a
與b必須具有相同的雜湊碼。
既然追求查詢效率,那麼計算這個雜湊碼不能浪費太多時間。而且這個計算只能根據物件的狀態,與散列表中的其他物件無關。
在這裡,我們先來回顧一下相關資料結構的知識。
散列表查詢的定義
儲存位置=f(關鍵字)雜湊就是在儲存位置與關鍵字之間建立的對應關係f,使得每個關鍵字key對應一個儲存位置f(key)。查詢時,根據關係f就能得到key對應的儲存位置f(key),若集合中存在這個記錄,則必定在f(key)位置上。
我們稱f為雜湊函式(或雜湊函式),採用雜湊技術將記錄儲存在一塊連續的空間,這塊空間就是散列表或雜湊表。關鍵字對應的儲存地址就是雜湊地址。
查詢步驟
分兩步:儲存記錄,查詢記錄
1)儲存記錄時,通過雜湊函式計算儲存地址,並按此地址儲存記錄。
2)查詢記錄時,通過雜湊函式計算雜湊地址,按此雜湊地址訪問該記錄。在哪存,去哪找。
由此可見,雜湊技術實際上是一種儲存方法,同時也是查詢方法。
如何實現
回到雜湊函式的定義,首先設計一個好的雜湊函式是必須的。理想情況下,設計的雜湊函式應滿足:k1!=k2,f(k1)!=f(k2)。(若f(k1)==f(k2),則衝突)。衝突是不可避免的,即便雜湊函式設計的很好,所以實現的另一個方面即如何處理衝突。
現在考慮第一個問題:如何設計一個好的雜湊函式?
遵循這兩個原則:計算簡單,雜湊地址均勻分佈。
接下來介紹幾種常見雜湊方法。
1 直接地址法
f(key)=key
f(key)=a*key+b比如,對0-100歲的人口數字統計,f(key)=key

或者80後出生年份的人數統計,f(key)=1*key-1980

這種方法優點:簡單,分佈均勻,不會產生衝突
缺點:需要事先知道關鍵字的分佈,適合查詢表較小,且連續的情況。
使用條件太多,用的較少。
2 數字分析法
如果關鍵字位數較多,比如電話號碼11位,一般前三位是服務商,中間四位是號碼歸屬,後面四位才是真正使用者號,所以可以抽取後四位作為雜湊地址(或者在此基礎上再反轉1234改為4321,右環位移1234改為4123,左環位移,前兩位與後兩位疊加1234改為12+34=46),總之就是抽取一部分來計算雜湊地址。
數字分析法適合數字位數較多的情況,且需要知道關鍵字的分佈情況。
3 平方取中法
1234平方1522756,再取中間3位就是227,作為雜湊地址。
平方取中法適用於不知道關鍵字分佈,且位數不大的情況。
4 摺疊法
將關鍵字從左到右劃分為相等位數的幾部分(如果最後不足,不用管),然後疊加,最後根據散列表長度從右到左擷取,作為雜湊地址。
比如關鍵字9876543210,散列表長度為3位,987|654|321|0,然後疊加987+654+321+0=1962,擷取後幾位962就是雜湊地址。
摺疊法適用於位數較多,且不知關鍵字分佈。
5 除留餘數法(重要)
f(key)=key mod p(p<=m)//m散列表長本方法選p是關鍵:p選接近m的最大素數或不包括小於20質因子的合數
6 隨機數法
f(key)=random(key)現在考慮第二個問題:如何解決衝突?
1 開放定址法
一旦發生衝突,就尋找下一個空的雜湊地址,只要散列表足夠大,就能找到。
fi(key)=(f(key)+di) mod m (di=1,2,...m-1)又稱為線性探測法。
舉個例子,集合{12,67,56,16,25,37,22,29,15,47,48,34},表長12,我們就用雜湊函式f(key)=key mod 12
計算{12,67,56,16,25}得

計算37,得f(37)=37 mod 12=1,與25位置衝突,利用公式f(37)=(f(37)+1) mod 12=2

22,29,15,47沒有衝突依次放入
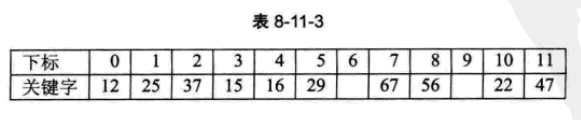
計算48,f(48)=0,與12衝突,利用公式f(48)=(f(48)+1)mod 12=1,與25衝突,…,f(48)=(f(48)+6) mod 12=6,不衝突,可以放入

這裡發現48和37本來不衝突,但最後卻衝突了,所以這種方法會產生堆積(因為逐步向後移),使得我們不斷處理衝突,降低查詢效率。
另外,key=34,f(key)=10,與22衝突,但後面沒有空位置,前面有一個,但是隻能向後查詢然後在返回來,顯然效率較低,所以可以改進如下:令di=1^2,-1^2,2^2,…q^2,-q^2
這種方法的目的就是不讓關鍵字聚集,稱為二次探測法。
還有一種方法,di=隨機數,稱為隨機探測法。
如果是隨機的,那查詢的時候如何保證獲得的隨機數恰好和儲存時的隨機數相同呢?(這個有疑問,沒明白,需要隨機種子)。
2 再雜湊法
fi(key)=RHi(key)(i=1,2,...k)RHi是不同的雜湊函式,即當出現衝突時,可以用另外一種雜湊函式繼續雜湊。
3 鏈地址法
將產生相同雜湊地址的關鍵字放在一個連結串列中。
比如,集合{12,67,56,16,25,37,22,29,15,47,48,34},表長12,我們就用雜湊函式f(key)=key mod 12
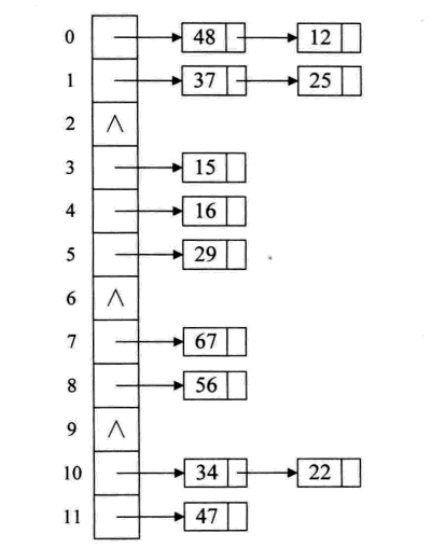
不會出現找不到空閒地址的情況,但是有可能在遍歷單鏈表時浪費時間,影響效率。
4 公共溢位區法
就是為所有衝突的關鍵字建立一個溢位區。

在查詢時,對給定值通過雜湊函式計算雜湊地址,先於基本表的位置比對,如果找不到,就到溢位表順序查詢。
雜湊查詢的效能
如果沒有衝突,雜湊查詢時間是O(1),如果有衝突,查詢效率與哪些因素有關呢?
1 雜湊函式是否均勻
雜湊函式會直接影響衝突出現的頻率,但如果雜湊函式不同,對相同的值,產生衝突的可能性是相同的,所以雜湊函式對平均查詢長度影響可以忽略。
2 處理衝突的方法
相同的關鍵字,相同的雜湊函式,不同的衝突處理方法,會影響平均查詢長度。比如線性探測法會產生堆積,沒有二次探測法好,而鏈地址法處理衝突不會產生任何堆積,具有更佳的平均查詢效能。
3 散列表的裝填因子
裝填因子a=填入表中的記錄個數/散列表長度如果表長12,裝入表中的記錄是11,則此時裝填因子a=11/12=0.9176。再填入另一個關鍵字產生衝突的可能性很大。也就是說散列表的平均查詢長度取決於裝填因子,而不是取決於查詢集合中的記錄個數
不管記錄n多大,總能找到一個裝填因子使得平均查詢長度限制在一個範圍內,這樣雜湊查詢的時間就是O(1)了,這是以空間換時間。(讓散列表大於集合記錄數)
現在考慮一下java中如何實現這種散列表查詢?
在Java中,散列表用連結串列陣列實現。如圖

好像和資料結構裡的鏈地址法很像。在此不做考究。
分析一下它的執行過程:每個列表為一個桶,給你一個物件,先計算它的雜湊碼,然後對桶的總數取餘,所得結果即為桶號。例如,某個物件雜湊碼76286,有128個桶,取餘得108,則物件應儲存在108號桶。如果桶沒有其他元素,則直接插入,若有,則先與桶中元素逐個比較,看是否已經存在。若桶已滿,需要建立一個溢位塊,將物件存入溢位塊中。
如果想要控制散列表的執行效能,需要提供一個初始的桶數(存放相同雜湊值的桶的數目)。
通常將桶數設定成記錄數的75%-150%。最好將桶數設成一個素數,以防鍵的集聚。標準類庫中使用的桶數是2的冪,預設值是16(為表大小提供的任何值都將被自動地轉換為2的下一個冪)。
空間利用率問題
實際鍵值數 / 所有桶可放置的鍵值數
<50%:空間浪費
>80%:溢位問題
50%到80%之間(GOOD!)
當然,並不是總能夠知道需要儲存多少個元素的,也有可能最初的估計過低。如果散列表太滿,就需要再雜湊( rehashed)。(如果溢位塊增多,意味著比較次數增多,會降低效能,可以考慮在雜湊,減少衝突)。
這裡會有兩種擴充套件散列表的方式:成倍增加桶數目,線性增加
1 成倍增加桶數目:當出現雜湊衝突時,即擴大一倍桶的數目。
缺點:桶增長速度快,可能會導致記憶體放不下整個桶陣列,影響其他儲存在主存中的資料,波動較大。
2 線性增加:桶數與當前記錄數保持固定比例(裝填因子a=記錄數/表長,當裝填因子超過75%時,就開始增加桶),一旦超過,開始增加桶的數目,當不超過時使用溢位塊。
散列表可以用於實現幾個重要的資料結構。其中最簡單的是set型別。 set是沒有重複元素的元素集合。 set的add方法首先在集中查詢要新增的物件,如果不存在,就將這個物件新增進去。
Java集合類庫提供了一個HashSet類,它實現了基於散列表的集。可以用add方法新增元素。contains方法已經被重新定義,用來快速地檢視是否某個元素已經出現在集中。它只在某個桶中查詢元素,而不必檢視集合中的所有元素。
雜湊集迭代器將依次訪問所有的桶。由於雜湊將元素分散在表的各個位置上,所以訪問它們的順序幾乎是隨機的。只有不關心集合中元素的順序時才應該使用HashSet。
樹集(TreeSet)
TreeSet與雜湊集相似,但它是有序的。比如
SortedSet<String> sorter=new TreeSet<String>();//TreeSet implements SortedSet
sorter.add("A");
sorter.add("B");
sorter.add("C");
for(String s:sorter)
System.out.println(s);
//output:
A
B
C