
mysql 高階(基礎四 索引優化 join 案例)
索引分析:單表
建表sql
create table if not exists article(
id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
author_id INT(10) UNSIGNED NOT NULL,
category_id INT(10) UNSIGNED NOT NULL,
views INT(10) UNSIGNED NOT NULL,
comments INT(10) UNSIGNED NOT NULL,
title VARBINARY(255) NOT 查詢category_id 為1 且 comments 大於1 的情況下,views 最多的article_id
select id,author_id from article where category_id =1 and explain 分析

顯然,type是all ,即最壞的情況,Extra 裡還出現了Using filesort,也是最壞的情況。優化是必須的。
show index from article ;
開始優化:
1.1新建索引+刪除索引
ALTER TABLE article add index index_article_ccv(category_id,comments,views);
create index idx_article_ccv on article(category_id,comments,views); 第一次想到的是這樣建立索引。
create index idx_article_ccv on article(category_id,comments,views);但是分析三個欄位,category_id ,comments ,views
按照BTree 索引建立的工作原理,
先排序category_id,
如果遇到相同的category_id 則再排序comments,如果遇到相同的comments則再排序views。
當comments 欄位在聯合索引中間位置時,
因為comments>1是範圍值(range) ,
mysql 無法利用索引再對後面的view部分進行檢索,即range型別查詢欄位後面的索引無效。
所以,建立索引,選擇
create index idx_article_ccv on article(category_id,views);
檢視新增索引後的查詢效果:

type為ref extra 為Using where
That’s beautiful
兩表:
create table if not exists clazz (
id INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL
);create table if not exists book (
bookid INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL
);insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));
insert into clazz(card) values(FLOOR(1+(RAND()*20)));insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
insert into book (card) values(FLOOR(1+(RAND()*20)));
如果是左連線 就將索引建到右表;
如果是右連線 就將索引建到左表;
事例:
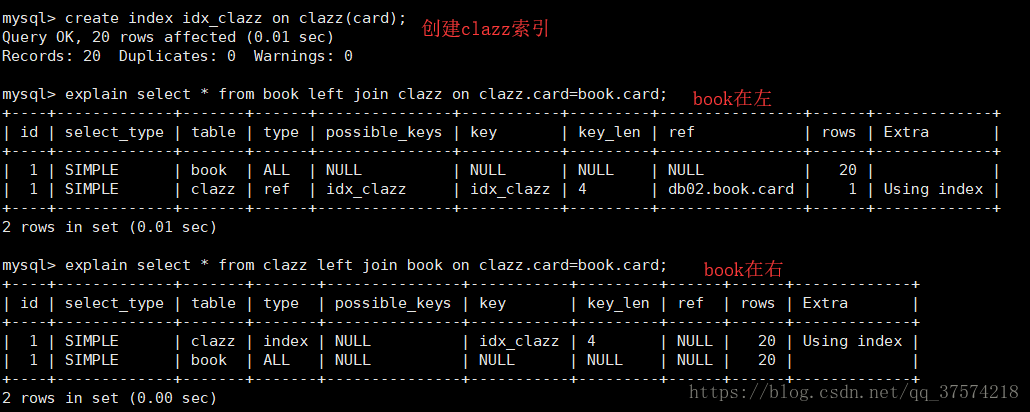
可以看出來book在左索引生效,book在右不走索引;
三表:
再加一張表:
create table if not exists phone (
phoneid INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
card INT(10) UNSIGNED NOT NULL
);insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));
insert into phone(card) values(FLOOR(1+(RAND()*20)));

book phone 為全表掃描
為book phone 建立索引後的結果

結論:
join語句的優化
儘可能減少join語句中的NestedLoop 的迴圈總次數;”永遠用小結果集驅動大結果集”
優先優化NestedLoop 的內層迴圈:
保證join語句中被驅動表上join條件欄位已經被索引;
當無法保證被驅動表的join條件欄位被索引且記憶體資源充足的前提下,不要太吝嗇joinbuffer的設定。