
kafka broker節點負載均衡失效
阿新 • • 發佈:2019-02-04
一大早上班,運維就給我發訊息,說一臺主機磁碟爆了,登上去一看
![]()
使用率100%,直接嚇尿,發現是我的一臺kafka主機,這是個kafka叢集,共3臺,再登入其他2臺,發現磁碟使用率才10%,高可用呢????
立馬覺得不對,百度沒搜到啥,Google了下,說是沒開啟高可用。。。。
如下檢視一個topic時發現Relicas確實只有一個節點。
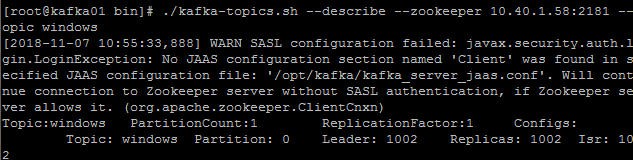
解決方案:
我用的ambari建的kafka,修改Advanced kafka-broker下的offsets.topic.replication.factor,之前預設為1。
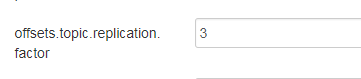
重啟kafka
修改後,新建一個topic,發現正常了

但是!!!!之前建立的topic並沒有增加副本,難道要刪了topic重建麼??
新建的topic會自動建立多個副本,但並未指定分割槽。
手工新增,從1個分割槽增加到3個,
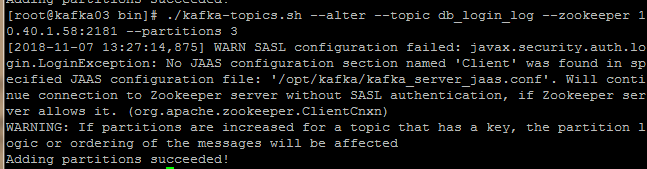
./kafka-reassign-partitions.sh --zookeeper 10.40.1.58:2181 --reassignment-json-file addReplicas.json --execute
即可解決。
還有個問題就是我是 用logstash建立的topic,預設就只有1個分割槽!!!