
《一個影象復原例項入門深度學習&TensorFlow—第五篇》資料讀取
從TFRrecord檔案中多執行緒的讀取資料
從這一篇開始,要啃一些硬骨頭了,不過掌握這一篇的內容就等於是掌握了深度學習中最重要的內容之一了
1. TFRecord檔案介紹
前一篇我們已經獲取了用於訓練和測試的資料,這些資料需要生成一個一個的mini-batch餵給神經網路讓它學習,我們希望這個mini-batch能快速產生,而且每一個mini-batch中image和label必須要互相對應(錯誤的label,網路必然學到錯誤的結果),與此同時,我們還希望這個batch是亂序的。出於這些要求,我們選用從TFRecord檔案中多執行緒的讀取資料的方式來產生mini-batch。(這是TensorFlow為解決資料匯入而設計的標準方式)
TFRecord檔案中將資料通過tf.train.Example Protocol Buffer的格式儲存,實際上就是一個數據打包的過程,我們的一組資料應該包括一幅轉置後的圖(image)和一幅沒有轉置的圖(label),同時這些圖還有行數,列數,通道數等屬性,對於分類問題可能還有類別,我們通過tf.train.Example Protocol Buffer格式,將同一組的相關屬性打包,這樣就整合了同一組資料中不同型別不同大小的屬性封裝到一起,這樣給我們的管理資料帶來了極大的便利。每一組打包好的資料結構中,都包含了一個從屬性名稱到取值的字典,其中屬性名稱是一個字串,屬性的取值可以為字串,實數列表或者整數列表。對於本系列部落格將要處理的問題,圖片都是28x28的灰度影象,我們只需將image和與之對應的label封裝到一起,屬性名稱分別為‘image’和‘label’,屬性取值為對應影象的畫素值,每一幅圖片的尺寸和通道都是固定的,就不用打包了。
2. 生成TFRecord檔案
為了統一檔案路徑,在大量寫程式碼之前,我們先統一檔案路徑吧,我們統一在E盤建一個名為MNIST_data的資料夾,其中有下列子資料夾:

| 資料夾 | 存放內容 |
|---|---|
| code | 程式碼 |
| models | 訓練好的神經網路模型 |
| result | 測試結果 |
| TensorBoard | 訓練過程視覺化檔案 |
| test_images | 測試資料 |
| test_labels | 測試資料理想輸出 |
| train_images | 訓練資料 轉置後的影象 |
| train_labels | 訓練資料 未轉置的影象 |
按照,第一部分對TFRecord檔案的介紹,我們開始將資料存放到TFRecord檔案中。程式如下:(備註:初學的話不要過多的在意程式碼的細節,知道流程看懂程式碼就ok啦)拷貝到Spyder或Notebook中執行,程式碼估計需要好幾分鐘,可以歇會兒了。如果報錯說找不到PIL包,你知道的吧:activate TensorFlow、 conda install pillow(不知道的話回看第二篇)
import os
import tensorflow as tf
from PIL import Image
image_path = 'E:\\MNIST_data\\train_images\\' # 輸入影象的路徑
label_path = 'E:\\MNIST_data\\train_labels\\' # 輸出影象的路徑
TFRecord_path = 'E:\\MNIST_data\\tfrecord\\train_data_set.tfrecord'# 輸出TFRecord檔案的路徑
def _bytes_feature(value): # 生成字串型的屬性,用於儲存圖片畫素資訊,根據自己問題的要求選擇要存的屬性
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# 將image_path和label_path中的圖片一一對應封裝在TFRecord_path中
def generate_TFRecordfile(image_path,label_path,TFRecord_path):
images = []
labels = []
for file in os.listdir(image_path):
images.append(image_path+file) # 得到所有轉置影象的檔名
for file in os.listdir(label_path):
labels.append(label_path+file) # 得到所有未轉置影象的檔名
num_examples = len(images) # 統計有多少用於訓練的圖片
print('There are %d images for training\n'%(num_examples))
writer = tf.python_io.TFRecordWriter(TFRecord_path) #建立一個writer寫TFRecord檔案
for index in range(num_examples):
print(index)
image = Image.open(images[index]) # 開啟一個image
image = image.tobytes() # 轉換為字元型格式(因為之前生成的也是字串型的屬性嘛)
label = Image.open(labels[index]) # 開啟一個對應的label
label = label.tobytes() # 轉換為字元型格式(因為之前生成的也是字串型的屬性嘛)
#將一個樣例轉換為Example Protocol Buffer的格式,並且一組資料的資訊都寫入這個資料結構中,(打包咯)
example = tf.train.Example(features=tf.train.Features(feature={
'image':_bytes_feature(image),
'label':_bytes_feature(label)}))
writer.write(example.SerializeToString())#將這個example 寫入TFRecord檔案
print('TFRecord file was generated successfully\n')
writer.close()
generate_TFRecordfile(image_path,label_path,TFRecord_path) # 呼叫函式
執行結束,在我們的tfrecord資料夾中就有了用於訓練的資料所生成的TFRecord檔案:
3.多執行緒讀取TFRecord檔案
資料存好了,現在拉出來溜溜
首先你要知道tensorflow資料讀取機制,這裡先看看這篇文章:https://zhuanlan.zhihu.com/p/27238630
你要確保你知道:
1:檔名佇列是用來存放所有資料的(你會想,我的TFRecord檔案裡面不就是存放的資料嗎,幹嘛還要加這樣一個檔名佇列,原因是我們訓練時同一組資料想要使用不止一次,而且希望隨機的將資料讀出來,通過建立檔名佇列就能完成這些要求)使用的函式tf.train.string_input_producer(files,shuffle ,num_epochs )將files中的資料是否(shuffle)隨機的放入檔名佇列中num_epochs次,比如我們有55000個用於訓練的資料存放在files,shuffle=True,num_epochs=2,那麼建立檔名佇列之後,檔名佇列中就含有110000組打亂後的資料(image和對應的label可沒有打亂哦,因為它們被我們封裝成一個整體了嘛,一組就是一個image和一個label)同時在佇列的最後有一個結束標記,當所有資料都使用過兩次之後,再嘗試讀取資料,這個結束標記就會報出一個OutOfRangeError的錯誤,我們捕捉這個錯誤然後跳出迴圈,結束訓練。
2:使用tf.train.string_input_producer建立檔名佇列後,整個系統其實還是處於“停滯狀態”的,也就是說,我們檔名並沒有真正被加入到佇列中。此時如果我們開始計算,因為記憶體佇列中什麼也沒有,計算單元就會一直等待,導致整個系統被阻塞。所以我們需要在之後使用tf.train.start_queue_runners,才會啟動填充佇列的執行緒,這時系統就不再“停滯”。此後計算單元就可以拿到資料並進行計算,整個程式也就跑起來了。
3:多執行緒協同完成,對於我們使用者來說只需要控制它什麼時候開始,什麼時候結束就好了。多執行緒的啟動就是使用2中介紹的tf.train.start_queue_runners在開始運算前加入使用這個函式啟動多執行緒,多執行緒的停止通過tf.Coordinator類來實現,這個類中提供了should_stop、request_stop還有join三個函式。在啟動執行緒之前,需要先宣告一個tf.Coordinator類的物件,並將這個物件傳入每一個建立的執行緒中,所以你會看到這樣兩行程式碼:
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess,coord=coord)
啟動的執行緒需要一直查詢tf.Coordinator類中提供的should_stop函式,當這個函式的返回值為True時,也就是需要執行緒(英文為:thread)should stop了,那麼這個執行緒就需要停止了,每一個啟動的執行緒都可以呼叫request_stop函式來通知其他執行緒停止,當某一個執行緒呼叫request_stop之後,should_stop函式的返回值就會變為True,這樣其他執行緒就可以同時停止了。下面這塊不完整的程式碼就是在做這個事。
try:
for step in range(5500):
if coord.should_stop(): # 讀到結束標記後coord.should_stop()變為True,跳出迴圈
break
image_batch,label_batch = sess.run([Image_Batch,Label_Batch])# 得到一個mini-batch
except tf.errors.OutOfRangeError: # 捕捉檔名佇列中的結束標記
print('epoch limit reached')
coord.request_stop() #通知其它執行緒停止讀取資料
finally:
coord.request_stop()
coord.join(threads) # 等待所有執行緒退出
下面讀一讀程式碼吧:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
image_path = 'E:\\MNIST_data\\train_images\\' # 輸入影象的路徑
label_path = 'E:\\MNIST_data\\train_labels\\' # 輸出影象的路徑
TFRecord_path = 'E:\\MNIST_data\\tfrecord\\train_data_set.tfrecord'# 輸出TFRecord檔案的路徑
img_W = 28 # 影象寬度
img_H = 28 # 影象高度
batch_size = 10 # 每個mini-batch含有的樣本數量
min_after_dequeue = 1000 # 佇列中最少檔案數量
capacity = min_after_dequeue + 3*batch_size # 佇列中最多檔案數量
num_threads = 5 #讀取資料的執行緒數
def get_batch(TFRecord_path):
reader = tf.TFRecordReader() # 建立一個reader來讀取TFRecord檔案中的樣例
files = tf.train.match_filenames_once(TFRecord_path) # 獲取檔案列表
# 建立檔名佇列,亂序,每個樣本使用num_epochs次
filename_queue = tf.train.string_input_producer(files,shuffle = True,num_epochs = 1)
# 讀取並解析一個樣本
_,example = reader.read(filename_queue)
features = tf.parse_single_example(
example,
features={
'image':tf.FixedLenFeature([],tf.string),
'label':tf.FixedLenFeature([],tf.string)})
# 使用tf.decode_raw將字串解析成影象對應的畫素陣列 ()
images = tf.decode_raw(features['image'],tf.uint8)
labels = tf.decode_raw(features['label'],tf.uint8)
# 所得畫素陣列為shape為((img_W*img_H),),應該reshape
images = tf.reshape(images, shape=[img_W,img_H])
labels = tf.reshape(labels, shape=[img_W,img_H])
#在這裡新增影象預處理函式(optional)
#使用tf.train.shuffle_batch來隨機組合資料生成用於隨機梯度下降的mini-batch
Image_Batch,Label_Batch = tf.train.shuffle_batch([images,labels],
batch_size = batch_size,
num_threads = 5,
min_after_dequeue = min_after_dequeue,
capacity = capacity)
return Image_Batch,Label_Batch
Image_Batch,Label_Batch = get_batch(TFRecord_path)
init_op = (tf.local_variables_initializer(),tf.global_variables_initializer())#初始化操作
with tf.Session() as sess:
sess.run(init_op)
coord = tf.train.Coordinator() # 用於協調多個執行緒同時終止
threads = tf.train.start_queue_runners(sess=sess,coord=coord) # 啟動執行緒
try:
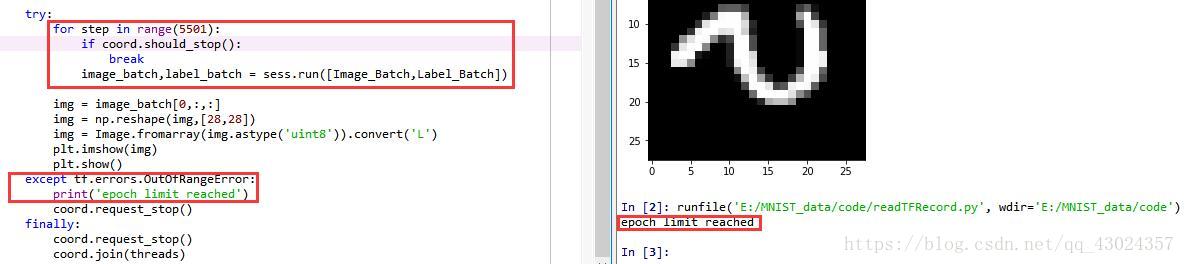
for step in range(5500):
if coord.should_stop(): # 讀到結束標記後coord.should_stop()變為True,跳出迴圈
break
image_batch,label_batch = sess.run([Image_Batch,Label_Batch])# 得到一個mini-batch
#這裡就可以feed進入網路,進行訓練啦
#畫個圖
img = image_batch[0,:,:] # 取一個mini-batch(10張)中的一張出來看看
img = np.reshape(img,[28,28])
img = Image.fromarray(img.astype('uint8')).convert('L')
plt.imshow(img)
plt.show()
except tf.errors.OutOfRangeError: # 捕捉檔名佇列中的結束標記
print('epoch limit reached')
coord.request_stop() #通知其它執行緒停止讀取資料
finally:
coord.request_stop()
coord.join(threads) #等待所有執行緒退出
執行程式碼得到結果:

這時,每一個mini-batch有10張組資料,一共迴圈了5500步取出了5500個mini-batch,也就是取出了55000組資料,我們訓練集中恰好含有55000組資料,因此每張圖恰好使用了一次,如果迴圈次數變為5501步在取第5501個batch時,取到的是一個結束標記,這時產生一個OutOfRangeError的錯誤得到如下結果:
4.總結
本篇部落格的主要內容是:
1:如何將資料封裝到TFRecord檔案中
2:如何多執行緒的讀取TFRecord檔案中的資料並生成一個可以用於訓練的mini-batch
內容確實不好理解,我也不確定是否講的清楚,感興趣的可以結合以下資源加深理解:
最後整合一下程式碼:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
image_path = 'E:\\MNIST_data\\train_images\\' # 輸入影象的路徑
label_path = 'E:\\MNIST_data\\train_labels\\' # 輸出影象的路徑
TFRecord_path = 'E:\\MNIST_data\\tfrecord\\train_data_set.tfrecord'# 輸出TFRecord檔案的路徑
img_W = 28 # 影象寬度
img_H = 28 # 影象高度
batch_size = 10 # 每個mini-batch含有的樣本數量
min_after_dequeue = 1000 # 佇列中最少檔案數量
capacity = min_after_dequeue + 3*batch_size # 佇列中最多檔案數量
def _bytes_feature(value): # 生成字串型的屬性,用於儲存圖片畫素資訊,根據自己問題的要求選擇要存的屬性
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
# 將image_path和label_path中的圖片一一對應封裝在TFRecord_path中
def generate_TFRecordfile(image_path,label_path,TFRecord_path):
images = []
labels = []
for file in os.listdir(image_path):
images.append(image_path+file) # 得到所有轉置影象的檔名
for file in os.listdir(label_path):
labels.append(label_path+file) # 得到所有未轉置影象的檔名
num_examples = len(images) # 統計有多少用於訓練的圖片
print('There are %d images for training\n'%(num_examples))
writer = tf.python_io.TFRecordWriter(TFRecord_path) #建立一個writer寫TFRecord檔案
for index in range(num_examples):
print(index)
image = Image.open(images[index]) # 開啟一個image
image = image.tobytes() # 轉換為字元型格式(因為之前生成的也是字串型的屬性嘛)
label = Image.open(labels[index]) # 開啟一個對應的label
label = label.tobytes() # 轉換為字元型格式(因為之前生成的也是字串型的屬性嘛)
#將一個樣例轉換為Example Protocol Buffer的格式,並且一組資料的資訊都寫入這個資料結構中,(打包咯)
example = tf.train.Example(features=tf.train.Features(feature={
'image':_bytes_feature(image),
'label':_bytes_feature(label)}))
writer.write(example.SerializeToString())#將這個example 寫入TFRecord檔案
print('TFRecord file was generated successfully\n')
writer.close()
def get_batch(TFRecord_path):
reader = tf.TFRecordReader() # 建立一個reader來讀取TFRecord檔案中的樣例
files = tf.train.match_filenames_once(TFRecord_path) # 獲取檔案列表
# 建立檔名佇列,亂序,每個樣本使用num_epochs次
filename_queue = tf.train.string_input_producer(files,shuffle = True,num_epochs = 1)
# 讀取並解析一個樣本
_,example = reader.read(filename_queue)
features = tf.parse_single_example(
example,
features={
'image':tf.FixedLenFeature([],tf.string),
'label':tf.FixedLenFeature([],tf.string)})
# 使用tf.decode_raw將字串解析成影象對應的畫素陣列 ()
images = tf.decode_raw(features['image'],tf.uint8)
labels = tf.decode_raw(features['label'],tf.uint8)
# 所得畫素陣列為shape為((img_W*img_H),),應該reshape
images = tf.reshape(images, shape=[img_W,img_H])
labels = tf.reshape(labels, shape=[img_W,img_H])
#在這裡新增影象預處理函式(optional)
#使用tf.train.shuffle_batch來隨機組合資料生成用於隨機梯度下降的mini-batch
Image_Batch,Label_Batch = tf.train.shuffle_batch([images,labels],
batch_size = batch_size,
num_threads = 5,
min_after_dequeue = min_after_dequeue,
capacity = capacity)
return Image_Batch,Label_Batch
generate_TFRecordfile(image_path,label_path,TFRecord_path) # 呼叫函式生成TFRecord檔案
Image_Batch,Label_Batch = get_batch(TFRecord_path) # 呼叫函式多執行緒讀取TFRecord檔案生成mini-batch
init_op = (tf.local_variables_initializer(),tf.global_variables_initializer())#初始化操作
with tf.Session() as sess:
sess.run(init_op)
coord = tf.train.Coordinator() # 用於協調多個執行緒同時終止
threads = tf.train.start_queue_runners(sess=sess,coord=coord) # 啟動執行緒
try:
for step in range(5500):
if coord.should_stop(): # 讀到結束標記後coord.should_stop()變為True,跳出迴圈
break
image_batch,label_batch = sess.run([Image_Batch,Label_Batch])# 得到一個mini-batch
#這裡就可以feed進入網路,進行訓練啦
#畫個圖
img = image_batch[0,:,:] # 取一個mini-batch(10張)中的一張出來看看
img = np.reshape(img,[28,28])
img = Image.fromarray(img.astype('uint8')).convert('L')
plt.imshow(img)
plt.show()
except tf.errors.OutOfRangeError: # 捕捉檔名佇列中的結束標記
print('epoch limit reached')
coord.request_stop() #通知其它執行緒停止讀取資料
finally:
coord.request_stop()
coord.join(threads) #等待所有執行緒退出