
深度學習基礎(五)—— 資料預處理
1 PCA
主成分分析法,一般用於資料降維。WHY?
影象中相鄰的畫素高度相關,輸入資料是有一定冗餘的。具體來說,假如我們正在訓練的16x16灰度值影象,記為一個256維向量 x∈ℜ256,其中特徵值 xj對應每個畫素的亮度值。由於相鄰畫素間的相關性,PCA演算法可以將輸入向量轉換為一個維數低很多的近似向量,而且誤差非常小。
1.1 PCA例項
資料:
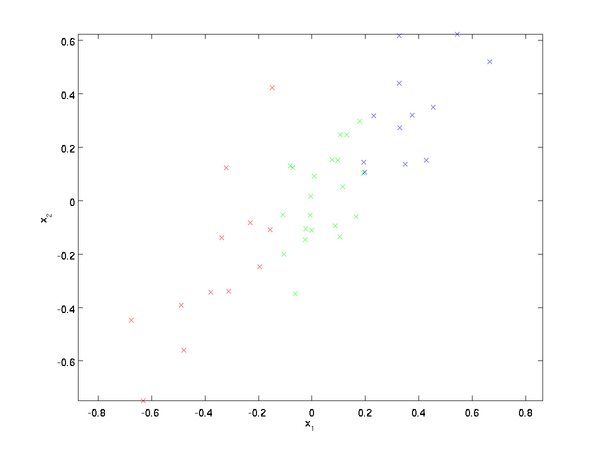
這些資料已經進行了預處理,使得每個特徵x1 和 x2 具有相同的均值(零)和方差。PCA演算法將尋找一個低維空間來投影我們的資料。從下圖中可以看出,u1 是資料變化的主方向,而 u2是次方向。
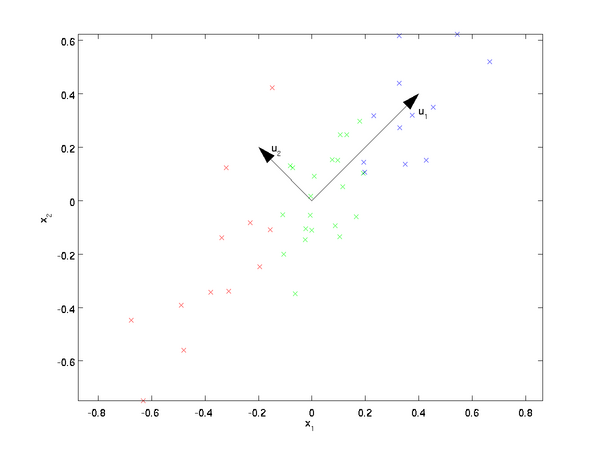
也就是說,資料在u1方向上的變化要比在 u
Σ=1mm∑i=1(x(i))(x(i))T.
假設x的均值為零,那麼Σ就是x的協方差矩陣。可以證明,資料變化的主方向u1就是協方差矩陣Σ的主特徵向量,而 u2 是次特徵向量。
先計算出協方差矩陣Σ的特徵向量,按列排放,而組成矩陣U:
U=[|||u1u2⋯un|||]
此處,u1是主特徵向量(對應最大的特徵值),u2是次特徵向量。以此類推,另記 λ1,λ2,…,λn 為相應的特徵值。
在本例中,向量 u1 和u2構成了一個新基,可以用來表示資料。令 x∈ℜ2為訓練樣本,那麼 uT1x 就是樣本點 x
1.2 旋轉資料
可以把x用(u1,u2)基表達為:
xrot=UTx=[uT1xuT2x]
(下標“rot”來源於單詞“rotation”,意指這是原資料經過旋轉(也可以說成對映)後得到的結果)。
對資料集中的每個樣本 i分別進行旋轉: x(i)rot=UTx(i)for every i,然後把變換後的資料 xrot顯示在座標圖上,可得:
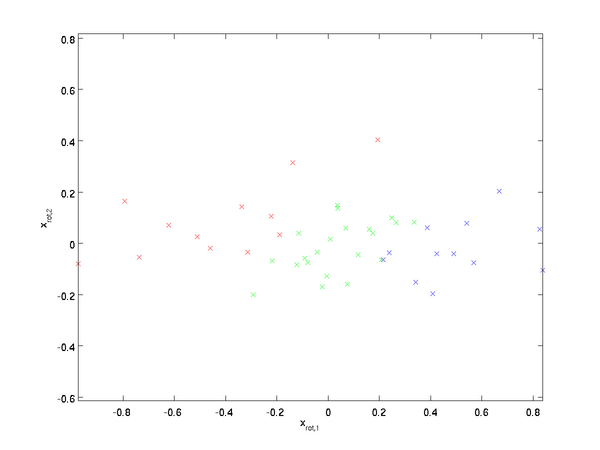
這就是把訓練資料集旋轉到 u1,u2 基後的結果。一般而言,運算 UTx表示旋轉到基 u1,u2,...,un 之上的訓練資料。矩陣 U有正交性,即滿足 U
1.3 資料降維
資料的主方向就是旋轉資料的第一維 xrot,1 。因此,若想把這資料降到一維,可令:
˜x(i)=x(i)rot,1=uT1x(i)∈ℜ.
更一般的,假如想把資料 x∈ℜn降到 k 維表示 ˜x∈ℜk(令 k<n ),只需選取xrot的前 k個成分,分別對應前k個數據變化的主方向。
PCA的另外一種解釋是:xrot是一個 n維向量,其中前幾個成分可能比較大(例如,上例中大部分樣本第一個成分 x(i)rot,1=uT1x(i)的取值相對較大),而後面成分可能會比較小(例如,上例中大部分樣本的 x(i)rot,2=uT2x(i) 較小)。
PCA演算法做的其實就是丟棄xrot中後面(取值較小)的成分,就是將這些成分的值近似為零。具體的說,設 ˜x 是 xrot的近似表示,那麼將 xrot 除了前k個成分外,其餘全賦值為零,就得到:
˜x=[xrot,1⋮xrot,k0⋮0]≈[xrot,1⋮xrot,kxrot,k+1⋮xrot,n]=xrot
在本例中,可得 \textstyle \tilde{x} 的點圖如下(取 \textstyle n=2, k=1 ):
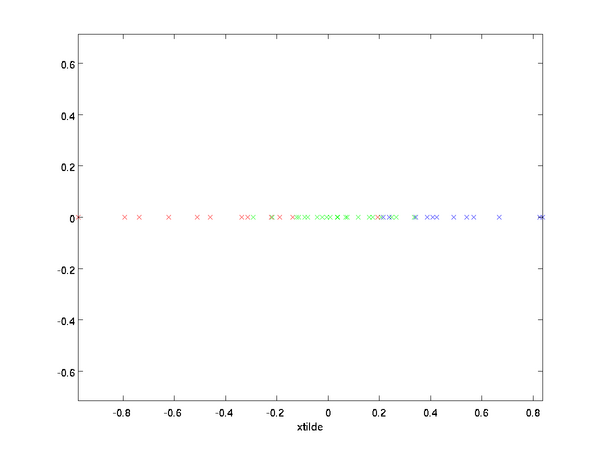
然而,由於上面 \textstyle \tilde{x} 的後\textstyle n-k項均為零,沒必要把這些零項保留下來。所以,我們僅用前 \textstyle k 個(非零)成分來定義 \textstyle k 維向量 \textstyle \tilde{x} 。
這也解釋了我們為什麼會以 \textstyle u_1, u_2, \ldots, u_n 為基來表示資料:要決定保留哪些成分變得很簡單,只需取前 \textstyle k 個成分即可。這時也可以說,我們“保留了前 \textstyle k 個PCA(主)成分”。
1.4 還原近似資料
給定 \textstyle \tilde{x} ,我們應如何還原原始資料 \textstyle x 呢?
只需 \textstyle x = U x_{\rm rot} 即可,我們把 \textstyle \tilde{x} 看作將 \textstyle x_{\rm rot} 的最後 \textstyle n-k 個元素被置0所得的近似表示,因此如果給定 \textstyle \tilde{x} \in \Re^k ,可以通過在其末尾新增 \textstyle n-k 個0來得到對 \textstyle x_{\rm rot} \in \Re^n 的近似,最後,左乘 \textstyle U 便可近似還原出原資料 \textstyle x 。具體來說,計算如下:
\hat{x} = U \begin{bmatrix} \tilde{x}_1 \\ \vdots \\ \tilde{x}_k \\ 0 \\ \vdots \\ 0 \end{bmatrix}
= \sum_{i=1}^k u_i \tilde{x}_i.
上面的等式基於先前對 \textstyle U 的定義。在實現時,我們實際上並不先給 \textstyle \tilde{x} 填0然後再左乘 \textstyle U ,因為這意味著大量的乘0運算。我們可用 \textstyle \tilde{x} \in \Re^k 來與 \textstyle U 的前 \textstyle k 列相乘,即上式中最右項,來達到同樣的目的。將該演算法應用於本例中的資料集,可得如下關於重構資料 \textstyle \hat{x} 的點圖:
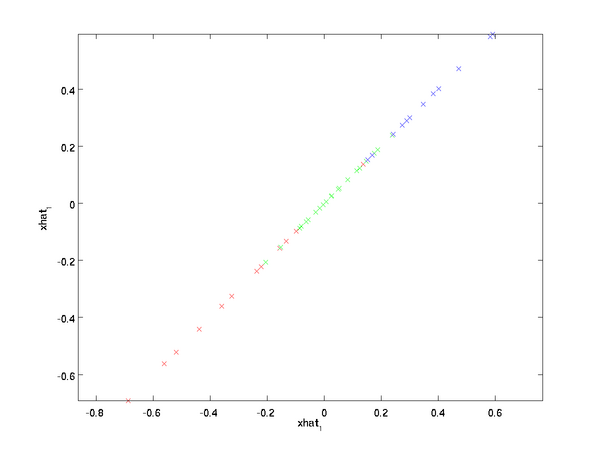
由圖可見,我們得到的是對原始資料集的一維近似重構。
在訓練自動編碼器或其它無監督特徵學習演算法時,演算法執行時間將依賴於輸入資料的維數。若用 \textstyle \tilde{x} \in \Re^k 取代 \textstyle x 作為輸入資料,那麼演算法就可使用低維資料進行訓練,執行速度將顯著加快。對於很多資料集來說,低維表徵量 \textstyle \tilde{x} 是原資料集的極佳近似,因此在這些場合使用PCA是很合適的,它引入的近似誤差的很小,卻可顯著地提高你演算法的執行速度。
1.5 選擇主成分個數
我們該如何選擇 \textstyle k ,即保留多少個PCA主成分?在上面這個簡單的二維實驗中,保留第一個成分看起來是自然的選擇。對於高維資料來說,做這個決定就沒那麼簡單:如果 \textstyle k 過大,資料壓縮率不高,在極限情況 \textstyle k=n 時,等於是在使用原始資料(只是旋轉投射到了不同的基);相反地,如果 \textstyle k 過小,那資料的近似誤差太太。
決定 \textstyle k 值時,我們通常會考慮不同 \textstyle k 值可保留的方差百分比。具體來說,如果
1 PCA
主成分分析法,一般用於資料降維。WHY?
影象中相鄰的畫素高度相關,輸入資料是有一定冗餘的。具體來說,假如我們正在訓練的16x16灰度值影象,記為一個256維向量 x∈ℜ256,其中特徵值 xj對應每個畫素的亮度值。由於相鄰畫素間的相關
總結一下今天的學習過程(注:程式碼都是根據教程抄的,哈哈)
1,溫習了統計學中的相關度與R值有關知識,以及計算公式,以及Python程式碼的實現,在簡單線性迴歸中,兩個是等價的
2,學習了k-means演算法,感覺這個應該是理解了,並對程式碼進行了單步除錯及邏輯的進一步理解
資料預處理
均值減法
它對資料中每個獨立特徵減去平均值,從幾何上可以理解為在每個維度上都將資料雲的中心都遷移到原點。
#numpy
X -= np.mean(X, axis=0)
歸一化
是指將資料的所有維度都歸一化,使其數值範圍都
深度學習是一種特殊的機器學習。要了解深度學習需要對機器學習有紮實的理解。本章是對整本書需要使用的最重要的通用原理的簡單課程。
什麼是學習演算法?比如:線性迴歸。大多數學習演算法需要預先設定好超級引數(hyperparameters)。我們要討論怎麼去設定它。 本文系PWN2WEB原創,轉載請說明出處
機器學習演算法最終學習結果的優劣取決於資料質量和資料中蘊含的有用資訊數量,對資料的處理對模型高效性起到了巨大的作用。
一 缺失資料的處理
資料採集過程中的錯誤導致缺失值的出現,我們無法忽略這些缺失值,所以我們需要對這些缺失值進行處理。
首先我們構造一個cs 原文地址:https://zybuluo.com/hanbingtao/note/581764
轉載在此的目的是自己做個筆記,日後好複習,如侵權請聯絡我!!
深度學習是什麼?
在人工智慧領域,有一個方法叫機器學習。在機器學習這個方法裡,有一類演算法叫神經網路。神經網路如下圖所示:
上圖的每 原文地址:https://www.zybuluo.com/hanbingtao/note/476663
轉載在此的目的是自己做個筆記,日後好複習,如侵權請聯絡我!!
在上一篇文章中,我們已經掌握了機器學習的基本套路,對模型、目標函式、優化演算法這些概念有了一定程度的理解,而且已經會訓練單個的感知器或者
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術感興趣的同學加入。
關於卷積神經網路CNN,網路和文獻中有非常多的資料,我在工作/研究中也用了好一段時間各種常見的model了,就想著 原文地址:https://zybuluo.com/hanbingtao/note/626300
轉載在此的目的是自己做個筆記,日後好複習,如侵權請聯絡我!!
在前面的文章中,我們介紹了迴圈神經網路,它可以用來處理包含序列結構的資訊。然而,除此之外,資訊往往還存在著諸如樹結構、圖結構等更復雜的結構。對於 softmax:重新定義了多層神經網路的輸出層(output layer),注意僅和輸出層有關係,和其他層無關。softmax function,也稱為 normalized exponential(指數族分佈的觀點);1. softmax我們知道在神經網路的前饋(feedfo
經典的多層感知機(Multi-Layer Perceptron)形式上是全連線(fully-connected)的鄰接網路(adjacent network)。
That is, every neuron in the network is connec
1. Sigmoid
函式定義:
f(x)=11+e−xf(x)=11+e−x
對應的影象是:
優點:
Sigmoid函式的輸出對映在(0,1)之間,單調連續,輸出範圍有限,優化穩定,可以用作輸出層。
求導容易。
缺點:
si
本節主要介紹一個深度學習的matlab版工具箱,
該工具箱中的程式碼很簡單,感覺比較適合用來學習演算法。裡面有常見的網路結構,包括深度網路(NN),稀疏自編碼網路(SAE),CAE,深度信念網路(DBN)(基於玻爾茲曼RBM實現),卷積神經網路(CNN
第6章 影象識別與卷積神經網路
本章通過利用CNN實現影象識別的應用來說明如何使用TensorFlow實現卷積神經網路
6.1 影象識別問題簡介及經典資料集
1. Cifar
Cifar-10:10種不同種類的60000張影象,畫素大小為3
這一節先介紹一些基本操作,然後再對我們前面建立的網路進行訓練
神經網路的前向傳播和反向傳播
隨即生產一張照片,1通道,32x32畫素的。為了直觀像是,匯入image包,然後用itorch.image()方法顯示生成的圖片,就是隨即的一些點
本節程式碼地址
現在終於到了激動人心的時刻了。我最初選用Torch的目的就是為了學習RNN。RNN全稱Recurrent Neural Network(遞迴神經網路),是通過在網路中增加回路而使其具有記憶功能。對自然語言處理,影象識別等方面都有深遠影響。
這次我們要用R
稀疏編碼演算法是一種無監督學習方法,它用來尋找一組“超完備”基向量來更高效地表示樣本資料。稀疏編碼演算法的目的就是找到一組基向量 (自然影象的小波基?)ϕi ,使得我們能將輸入向量 x 表示為這些基向量的線性組合:
x=∑i=1kaiϕi
所謂“超完備”基向
Recurrent Neural Networks
人類並不是每時每刻都從一片空白的大腦開始他們的思考。在你閱讀這篇文章時候,你都是基於自己已經擁有的對先前所見詞的理解來推斷當前詞的真實含義。我們不會將所有的東西都全部丟棄,然後用空白的大腦進行思考。我們的思想擁有永續性。
傳統的神經網路並不能做到這點
1.原始資料存在的幾個問題:不一致;重複;含噪聲;維度高。
2.資料預處理包含資料清洗、資料整合、資料變換和資料歸約幾種方法。
3.資料探勘中使用的資料的原則
應該是從原始資料中選取合適的屬性作為資料探勘屬性,這個選取過程應參考的原則是:儘可能賦予屬性名和屬性值明確的含義;
神經機器翻譯工具Nematus
1、資料預處理 ./preprocess.sh
主要流程包括:
tokenization(符號化處理)
This means that s 相關推薦
深度學習基礎(五)—— 資料預處理
深度學習基礎(五)--聚類
CS231n課程學習筆記(七)——資料預處理、批量歸一化和Dropout
深度學習筆記(五)第五章 深度學習基礎
機器學習基礎系列(2)——資料預處理
(轉載)深度學習基礎(1)——感知器
(轉載)深度學習基礎(3)——神經網路和反向傳播演算法
深度學習方法(五):卷積神經網路CNN經典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
(轉載)深度學習基礎(7)——遞迴神經網路
深度學習基礎(一) —— softmax 及 logsoftmax
深度學習基礎(二)—— 從多層感知機(MLP)到卷積神經網路(CNN)
深度學習基礎(七)—— Activation Function
深度學習系列(五):一個簡單深度學習工具箱
TensorFlow:實戰Google深度學習框架(五)影象識別與卷積神經網路
Torch7深度學習教程(五)
深度學習筆記(五)用Torch實現RNN來製作一個神經網路計時器
深度學習基礎(九)—— 稀疏編碼(sparse coding)
深度學習基礎(六):LSTM模型及原理介紹
資料探勘筆記(三)—資料預處理
Nematus(一)資料預處理與超引數配置