python資料分析(資料視覺化)
資料分析初始階段,通常都要進行視覺化處理。資料視覺化旨在直觀展示資訊的分析結果和構思,令某些抽象資料具象化,這些抽象資料包括資料測量單位的性質或數量。本章用的程式庫matplotlib是建立在Numpy之上的一個Python相簿,它提供了一個面向物件的API和一個過程式類的MATLAB API,他們可以並行使用。本文涉及的主題有:
- matplotlib簡單繪圖
- 對數圖
- 散點圖
- 圖例和註解
- 三維圖
- pandas繪圖
- 時滯圖
- 自相關圖
- Plot.ly
1、matplotlib繪圖入門
程式碼:import matplotlib.pyplot as plt import numpy as np x=np.linspace(0,20) #linspace()函式指定橫座標範圍 plt.plot(x,.5+x) plt.plot(x,1+2*x,'--') plt.show()
執行結果:
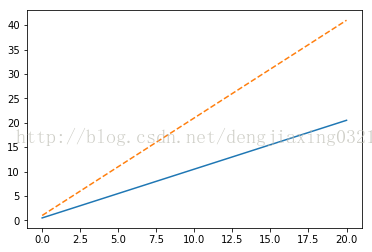
通過show函式將圖形顯示在螢幕上,也可以用savefig()函式把圖形儲存到檔案中。
2、對數圖
所謂對數圖,實際上就是使用對數座標繪製的圖形。對於對數刻度來說,其間隔表示的是變數的值在數量級上的變化,這與線性刻度有很大的不同。對數圖又分為兩種不同的型別,其中一種稱為雙對數圖,它的特點是兩個座標軸都採用對數刻度,對應的matplotlibh函式是matplotlib.pyplot..loglog()。半對數圖的一個座標軸採用線性刻度,另一個座標軸使用對數刻度,它對應的matplotlib API是semilogx()函式和semilogy()函式,在雙對數圖上,冪律表現為直線;在半對數圖上,直線則代表的是指數律。 摩爾定律大意為積體電路上電晶體的數量每兩年增加一倍。在https://en.wikipedia.org/wiki/Transistor_count#Microprocessors頁面有一個數據表,記錄了不同年份微處理器上電晶體的數量。我們為這些資料製作一個CSV檔案,名為transcount.csv,其中只包含電晶體數量和年份值。 程式碼:import matplotlib.pyplot as plt import numpy as np import pandas as pd df=pd.read_csv('H:\Python\data\\transcount.csv') df=df.groupby('year').aggregate(np.mean) #按年份分組,以數量均值聚合 #print grouped.mean() years=df.index.values #得到所有年份資訊 counts=df['trans_count'].values #print counts poly=np.polyfit(years,np.log(counts),deg=1) #線性擬合數據 print "poly:",poly plt.semilogy(years,counts,'o') plt.semilogy(years,np.exp(np.polyval(poly,years))) #polyval用於對多項式進行評估 plt.show() #print df #df=df.groupby('year').aggregate(np.mean)
執行結果:
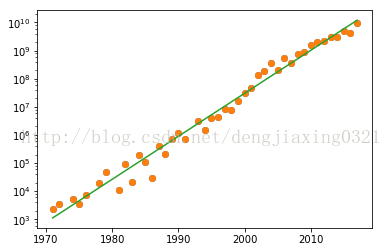
實線表示的是趨勢線,實心圓表示的是資料點。
3、散點圖
散點圖可以形象展示直角座標系中兩個變數之間的關係,每個資料點的位置實際上就是兩個變數的值。泡式圖是對散點圖的一種擴充套件。在泡式圖中,每個資料點都被一個氣泡所包圍,它由此得名;而第三個變數的值正好可以用來確定氣泡的相對大小。 在https://en.wikipedia.org/wiki/Transistor_count#GPU頁面上,有個記錄GPU晶體數量的資料表,我們用這些電晶體數量年份資料新建表gpu_transcount.csv。藉助matplotlib API提供的scatter()函式繪製散點圖。 程式碼:import matplotlib.pyplot as plt import numpy as np import pandas as pd df=pd.read_csv('H:\Python\data\\transcount.csv') df=df.groupby('year').aggregate(np.mean) gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv') gpu=gpu.groupby('year').aggregate(np.mean) df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True) df=df.replace(np.nan,0) print df years=df.index.values counts=df['trans_count'].values gpu_counts=df['gpu_counts'].values cnt_log=np.log(counts) plt.scatter(years,cnt_log,c=200*years,s=20+200*gpu_counts/gpu_counts.max(),alpha=0.5) #表示顏色,s表示標量或陣列 plt.show()
執行結果
trans_count gpu_counts
year
1971 2300 0.000000e+00
1972 3500 0.000000e+00
1974 5400 0.000000e+00
1975 3510 0.000000e+00
1976 7500 0.000000e+00
1978 19000 0.000000e+00
1979 48500 0.000000e+00
1981 11500 0.000000e+00
1982 94500 0.000000e+00
1983 22000 0.000000e+00
1984 190000 0.000000e+00
1985 105333 0.000000e+00
1986 30000 0.000000e+00
1987 413000 0.000000e+00
1988 215000 0.000000e+00
1989 745117 0.000000e+00
1990 1200000 0.000000e+00
1991 692500 0.000000e+00
1993 3100000 0.000000e+00
1994 1539488 0.000000e+00
1995 4000000 0.000000e+00
1996 4300000 0.000000e+00
1997 8150000 3.500000e+06
1998 7500000 0.000000e+00
1999 16062200 1.533333e+07
2000 31500000 2.500000e+07
2001 45000000 5.850000e+07
2002 137500000 8.500000e+07
2003 190066666 1.260000e+08
2004 352000000 1.910000e+08
2005 198500000 3.120000e+08
2006 555600000 5.325000e+08
2007 371600000 4.882500e+08
2008 733200000 7.166000e+08
2009 904000000 9.155000e+08
2010 1511666666 1.804143e+09
2011 2010000000 1.370952e+09
2012 2160625000 3.121667e+09
2013 3015000000 3.140000e+09
2014 3145000000 3.752500e+09
2015 4948000000 8.450000e+09
2016 4175000000 7.933333e+09
2017 9637500000 8.190000e+09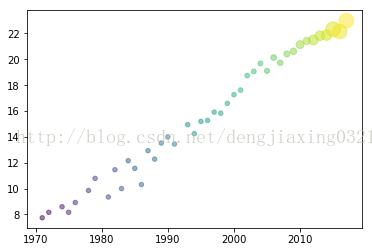
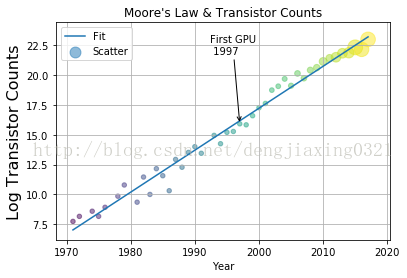
4、圖例和註解
要想做出讓人眼前一亮的神圖,圖例和註解肯定是少不了的。一般情況下,資料圖都帶有下列輔助資訊。- 用來描述圖中各資料序列的圖例,matplotlib提供的legend()函式可以為每個資料序列提供相應的標籤。
- 對圖中要點的註解。可以藉助matplotlib提供的annotate()函式。
- 橫軸和縱軸的標籤,可以通過xlabel()和ylabel()繪製出來。
- 一個說明性質的標題,通常由matplotlib的title函式來提供.
- 網格,對於輕鬆定位資料點非常有幫助。grid()函式可以用來決定是否使用網格。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df=pd.read_csv('H:\Python\data\\transcount.csv')
df=df.groupby('year').aggregate(np.mean)
gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv')
gpu=gpu.groupby('year').aggregate(np.mean)
df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True)
df=df.replace(np.nan,0)
years=df.index.values
counts=df['trans_count'].values
gpu_counts=df['gpu_counts'].values
#print df
poly=np.polyfit(years,np.log(counts),deg=1)
plt.plot(years,np.polyval(poly,years),label='Fit')
gpu_start=gpu.index.values.min()
y_ann=np.log(df.at[gpu_start,'trans_count'])
ann_str="First GPU\n %d"%gpu_start
plt.annotate(ann_str,xy=(gpu_start,y_ann),arrowprops=dict(arrowstyle="->"),xytext=(-30,+70),textcoords='offset points')
cnt_log=np.log(counts)
plt.scatter(years,cnt_log,c=200*years,s=20+200*gpu_counts/gpu_counts.max(),alpha=0.5,label="Scatter") #表示顏色,s表示標量或陣列
plt.legend(loc="upper left")
plt.grid()
plt.xlabel("Year")
plt.ylabel("Log Transistor Counts",fontsize=16)
plt.title("Moore's Law & Transistor Counts")
plt.show()
執行結果:
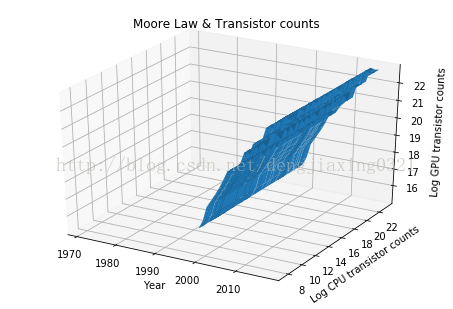
5、三維圖
Axes3D是由matplotlib提供的一個類,可以用來繪製三維圖。通過講解這個類的工作機制,就能夠明白麵向物件的matplotlib API的原理了,matplotlib的Figure類是存放各種影象元素的頂級容器。
程式碼:
from mpl_toolkits.mplot3d.axes3d import Axes3D
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df=pd.read_csv('H:\Python\data\\transcount.csv')
df=df.groupby('year').aggregate(np.mean)
gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv')
gpu=gpu.groupby('year').aggregate(np.mean)
df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True)
df=df.replace(np.nan,0)
fig=plt.figure()
ax=Axes3D(fig)
X=df.index.values
Y=np.log(df['trans_count'].values)
X,Y=np.meshgrid(X,Y)
Z=np.log(df['gpu_counts'].values)
ax.plot_surface(X,Y,Z)
ax.set_xlabel('Year')
ax.set_ylabel('Log CPU transistor counts')
ax.set_zlabel('Log GPU transistor counts')
ax.set_title('Moore Law & Transistor counts')
plt.show()執行結果:
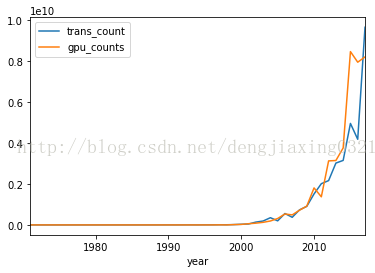
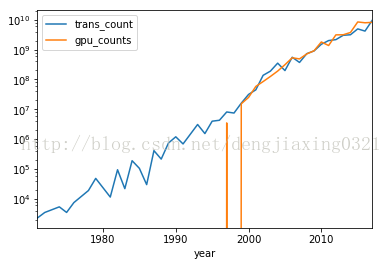
6、pandas繪圖
pandas的Series類和DataFrame類中的plot()方法都封裝了相關的matplotlib函式。如果不帶任何引數,使用plot方法繪製圖像如下:
程式碼:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
df=pd.read_csv('H:\Python\data\\transcount.csv')
df=df.groupby('year').aggregate(np.mean)
gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv')
gpu=gpu.groupby('year').aggregate(np.mean)
df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True)
df=df.replace(np.nan,0)
df.plot()
df.plot(logy=True) #建立半對數圖
df[df['gpu_counts']>0].plot(kind='scatter',x='trans_count',y='gpu_counts',loglog=True) #loglog=True 生成雙對數
plt.show()
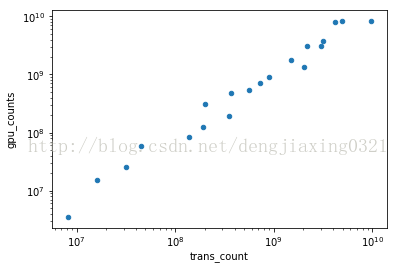
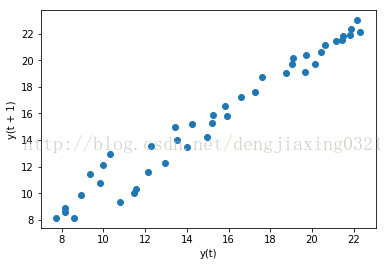
7、時滯圖
時滯圖實際上就是一個散點圖,只不過把時間序列的影象及相同序列在時間軸上後延影象放一起展示而已。例如,我們可以利用這種圖考察今年的CPU電晶體數量與上一年度CPU電晶體數量之間的相關性。可以利用pandas字型檔pandas.tools.plotting中的lag_plot()函式來繪製時滯圖,滯預設為1。 程式碼:import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pandas.tools.plotting import lag_plot
df=pd.read_csv('H:\Python\data\\transcount.csv')
df=df.groupby('year').aggregate(np.mean)
gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv')
gpu=gpu.groupby('year').aggregate(np.mean)
df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True)
df=df.replace(np.nan,0)
lag_plot(np.log(df['trans_count']))
plt.show()執行結果:
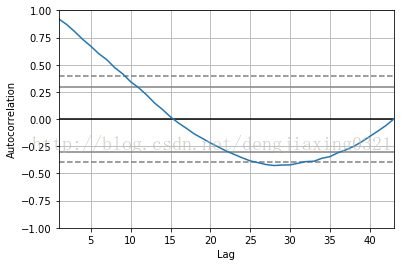
8、自相關圖
自相關圖描述的是時間序列在不同時間延遲情況下的自相關性。所謂自相關,就是一個時間序列與相同資料在不同時間延遲情況下的相互關係。利用pandas子庫pandas.tools.plotting 中的autocorrelation_plot()函式,就可以畫出自相關圖了。
程式碼:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from pandas.tools.plotting import autocorrelation_plot
df=pd.read_csv('H:\Python\data\\transcount.csv')
df=df.groupby('year').aggregate(np.mean)
gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv')
gpu=gpu.groupby('year').aggregate(np.mean)
df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True)
df=df.replace(np.nan,0)
autocorrelation_plot(np.log(df['trans_count'])) #繪製自相關圖
plt.show()
從圖中可以看出,較之於時間上越遠(即時間延遲越大)的數值,當前的數值與時間上越接近(及時間延遲越小)的數值相關性越大;當時間延遲極大時,相關性為0;
9、Plot.ly
Plot.ly實際上是一個網站,它不僅提供了許多資料視覺化的線上工具,同時還提供了可在使用者機器上使用的對應的python庫。可以通過Web介面或以本地匯入並分析資料,可以將分析結果公佈到Plot.ly網站上。
安裝plotly庫:pip install plotly
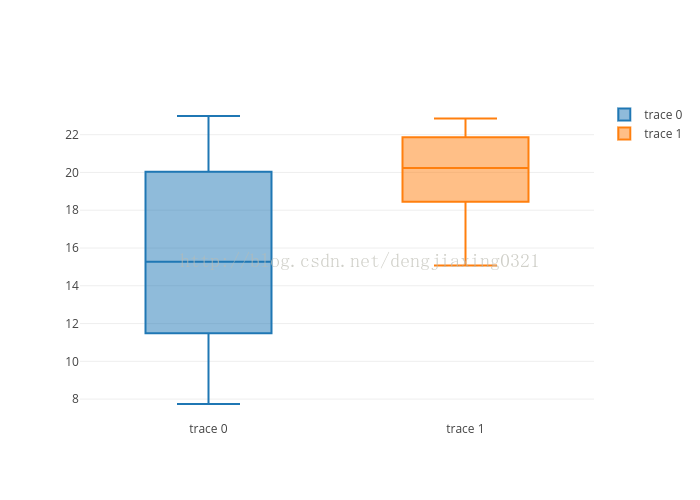
先在plotly註冊一個賬號,然後產生一個api_key。最後可以繪製箱形圖。
程式碼:
import numpy as np
import pandas as pd
import plotly.plotly as py
from plotly.graph_objs import *
from getpass import getpass
df=pd.read_csv('H:\Python\data\\transcount.csv')
df=df.groupby('year').aggregate(np.mean)
gpu=pd.read_csv('H:\Python\data\\gpu_transcount.csv')
gpu=gpu.groupby('year').aggregate(np.mean)
df=pd.merge(df,gpu,how='outer',left_index=True,right_index=True)
df=df.replace(np.nan,0)
api_key=getpass()
py.sign_in(username='dengjiaxing',api_key='qPCrc5EA7unk9PlhNwLG')
counts=np.log(df['trans_count'].values)
gpu_counts=np.log(df['gpu_counts'].values)
data=Data([Box(y=counts),Box(y=gpu_counts)])
plot_url=py.plot(data,filename='moore-law-scatter')
print plot_url執行結果: