機器學習教程 之 整合學習演算法: 深入刨析AdaBoost
Boosting 是一族可以將弱學習器提升為強學習器的演算法。這族演算法的工作機制類似:先從初始訓練集訓練出一個基學習器,再根據基學習器的表現對訓練樣本分佈進行調整,使得先前基學習器做錯的訓練樣本在後續受到更多的關注,然後基於調整後的樣本分佈來訓練下一個基學習器;如此重複進行,直至基學習器達到事先指定的值T,最終將這T個基學習器進行加權結合。
一、什麼是整合學習?
二、AdaBoost演算法
三、AdaBoost的python3實現(決策樹樁為基分類器)
四、AdaBoost演算法效能的影響因素
五、AdaBoost演算法的優缺點
六、隨機森林演算法簡介
一、什麼是整合學習?
整合學習(ensemble learning)是機器學習演算法當中的一類,它通過構建並結合多個學習器來完成學習任務,有時也被稱為多分類器系統(multi-classifier system)
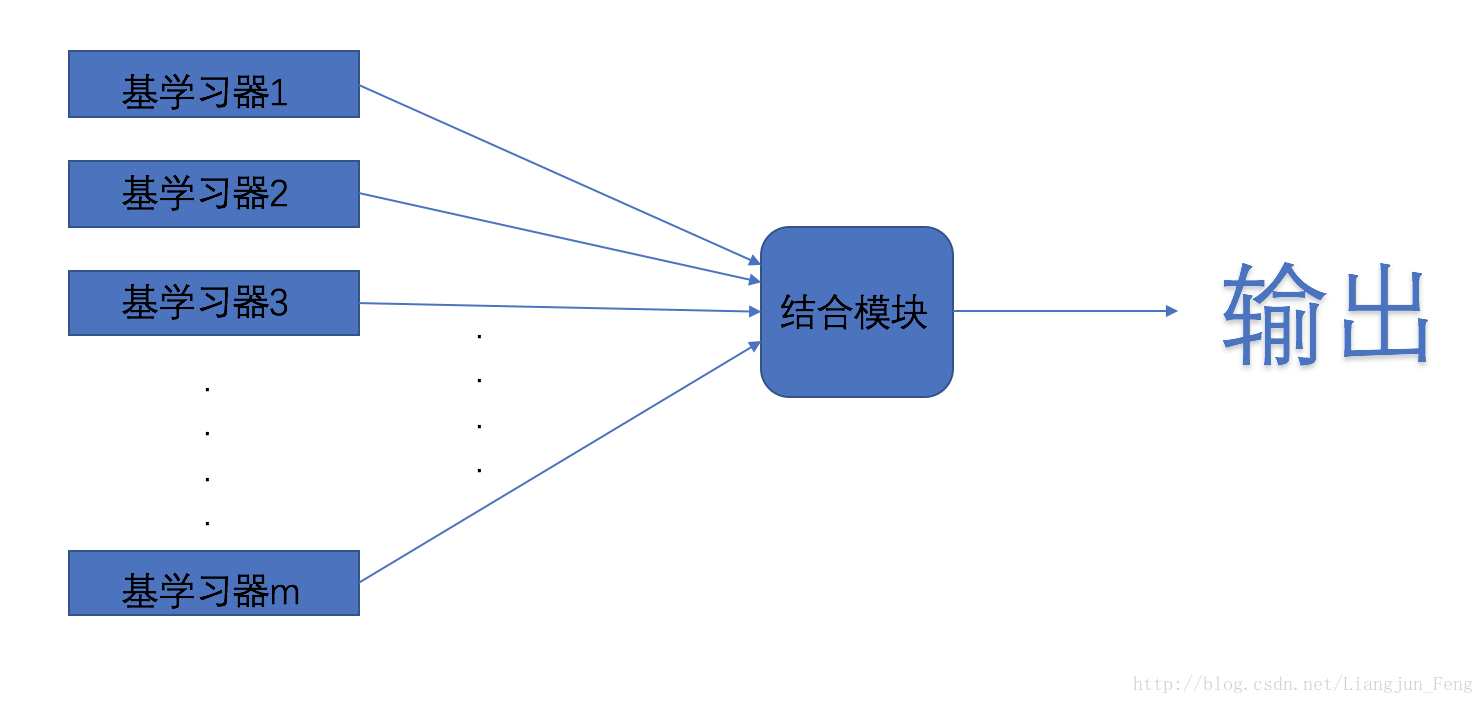
它的基本思路是:先產生一組“基學習器”,再使用某種策略將它們結合起來,基學習器通常是現有的學習演算法,比如決策樹、神經網路等、基學習器可以是相同的,也可以是不同的
不要把整合學習看作一些機器學習演算法結果上簡單的整合,因為使用同一個資料集去訓練同一種分類器,即使訓練很多個分類器,它們的分類結果也可能是十分相似的,對於最終的分類幫助也不會很大
整合學習對於基學習器有一個標準:
要獲得好的整合結果,基學習器應當“好而不同”,即個體學習器要有一定的“準確性”,即學習器不能太壞,並且學習器的分類效能應當存在差異但事實上,基學習器都是為了解決同一個問題基於同一個訓練集訓練出來的,其“準確性”和“多樣性”本身就存在一定的衝突,一般來說,準確性高了,增加多樣性就需要犧牲準確性,如何產生並結合“好而不同”的基學習器是整合學習的核心問題
目前的整合學習演算法可以根據基學習器的生成方式分為兩類:
1) 基學習器採用序列生成的序列化方法,個體學習器之間存在強依賴關係,代表為Boosting演算法群
2) 基學習器採用並行化的生成方法,不存在強依賴關係,可同時生成,其代表為隨機森林(Random Forest)演算法
這裡我們將主要以Boosting演算法中最成功,也是最具代表性的AdaBoost演算法為例,說明整合學習的原理和特性,在結尾會稍微對隨機森林演算法有所介紹
二、AdaBoost演算法
在介紹Adaboost演算法之前,我先簡單介紹一下Boosting演算法,boosting起源於1988年Kearns在研究PAC(Probably Approximately Correct)模型時對Valiant提出的問題——“弱學習是否等於強學習?”
弱學習演算法:指泛化效能略優於隨機猜測的分類演算法
強學習演算法:識別準確率很高並且能在多項式時間內完成的學習演算法
至1990年,Schapire最先對該問題給出了肯定的證明,提出了最初的Boosting 演算法,該演算法證明了弱學習演算法可以被提升到1- a(置信度)概率輸出錯誤率小於任意b(精度)的假設,即得到強學習演算法
Boosting演算法的證明中要求提前預知分類器錯誤率的上限,因此難以在實際問題中使用,Freund和Schapire為了改進Boosting演算法的這一缺陷,於1995年提出了AdaBoost(Adaptive Boosting演算法),這一演算法提出,在機器學習領域受到了極大的關注,成為Boosting家族最具代表性的演算法
在深度學習出現以前,Adaboost、隨機森林還有支援向量機,幾乎是當時效能最為優越的分類演算法,即使是現在,Adaboost在影象識別、語音識別等領域也佔有重要地位
AdaBoost演算法流程:
1 初始化訓練資料的權值分佈,一開始每一個樣本賦予相同的權值1/N
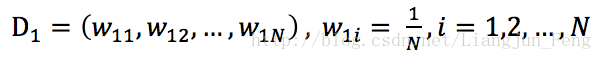
2)進行多輪的迭代學習,使用具有權值分佈的Dm的訓練資料集來學習,得到基本分類器。分對的樣本的權值會降低,分錯的樣本的權值會增加,目的是使分錯的訓練樣本得到更多的關注。每個學習器都會有一個權值am,am的值是基於每個弱分類器的錯誤率和權值分佈進行計算的
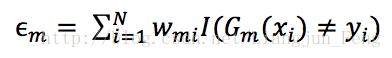
學習器的權值為
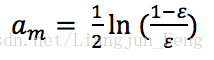
m表示第幾個學習器。從這個公式可以看出,當小於0.5時,am>0,意味著學習器的誤差率越小,基學習器在最終的分類器中作用越大,然後我們還需要更新樣本的權值分佈
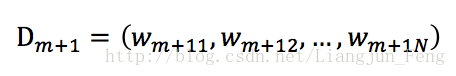
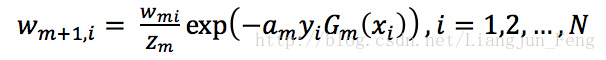
這樣可以使得被級分類器Gm誤分類樣本的權值增大,而被正確分類樣本的權值減小,其中Zm是規範化因子,可以使得Dm+1成為一個概率分佈
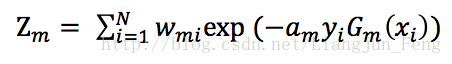
3) 組合各弱學習器
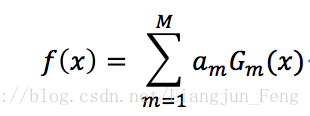
得到的最終分類器為
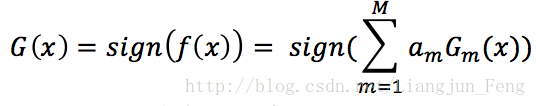
sign(x)在x<0,x=0,x>0時分別取值為-1,0,1
三、AdaBoost的python3實現(決策樹樁為基分類器)
接下來,使用決策樹樁(即只有一層的決策樹)作為基學習器,以皮馬印第安糖尿病資料集作為學習物件,實現AdaBoost演算法
程式分段講解,資料預處理
#!/usr/bin/env python3
# -*-coding: utf-8-*-
# Author : LiangjunFeng
# Blog : http://my.csdn.net/Liangjun_Feng
# GitHub : https://www.github.com/LiangjunFeng
# File : AdaBoost.py
# Date : 2017/09/17 11:12
# Version: 0.1
# Description: AdaBoost algorithm ,ensemble learning
import numpy
import math
from pandas import read_csv
def loadData(): #讀取CSV格式資料檔案
dataSet = read_csv('/Users/zhuxiaoxiansheng/Desktop/data_set/pima-indians-diabetes/pima-indians-diabetes.csv',header = None)
return dataSet
def dataPrepreocess(dataSet): #資料預處理,將屬性與標籤分開,同時以中值填充缺少資料,將資料轉化為矩陣格式
dataSet[[0,1,2,3,4,5,6,7]] = dataSet[[0,1,2,3,4,5,6,7]].replace(0,numpy.NaN)
data = dataSet[[0,1,2,3,4,5,6,7]]
data.fillna(data.median(),inplace = True) #以中值填充空白
label = dataSet[8]
data = numpy.matrix(data.as_matrix(columns=None)) #轉化為矩陣
label = numpy.matrix(label.as_matrix(columns=None)) #轉化為矩陣
return data,label.T
def dataSplit(data,label): #將資料分為測試集和訓練集
for i in range(len(label)):
if label[i,0] == 0:
label[i,0] = -1
mid = int(len(data)*0.68)
trainData = data[0:mid] #前68%為訓練集
testData = data[mid:] #剩下的為測試集
trainLabel = label[0:mid,0]
testLabel = label[mid:,0]
return trainData,trainLabel,testData,testLabel #返回訓練集、訓練標籤、測試集、測試標籤程式主體為兩個類,決策樹樁類與AdaBoost類
class decisionRoot: #以決策樹樁類作為基學習器
def __init__(self):
self._rootAttribute = 0 #樹根的分類屬性
self._thresholdValue = 0 #分類屬性的分類閾值
self._minError = 0 #存貯該分類器的分類誤差
self._operator = None #分類操作符,取值為‘le’或‘gt’
self._estimateLabel = None #對訓練樣本的估計分類
@classmethod
def classify(cls,data,operator,thresholdValue): #已知樹根的分類屬性、分類閾值、分類操作符後,用於實現樣資料的二分類
estimateLabel = numpy.ones((data.shape[0],1))
if operator == 'le':
estimateLabel[data <= thresholdValue] = -1 #屬性值小於等於閾值的樣本標籤設定為-1,其餘的為1
else:
estimateLabel[data > thresholdValue] = -1 #屬性值大於閾值的樣本標籤設定為-1,其餘的為1
return estimateLabel
def buildTree(self,data,label,distribute): #根據訓練資料和樣本分佈訓練取得最優分類樹
samples,attributes = data.shape
estimateLabel = numpy.matrix(numpy.zeros((samples,1)))
minError = numpy.inf #初始的最小誤差為無限大
stepNumber = 10.0 #為決定屬性的最優分類閾值,將樣本的屬性從最小值到最大值遍歷,步數為10
for rootAttribute in range(attributes):
attributeMin = data[:,rootAttribute].min()
attributeMax = data[:,rootAttribute].max()
stepSize = (attributeMax - attributeMin)/stepNumber #獲得步長
for j in range(int(stepNumber+1)): #遍歷屬性,以求得最優分類屬性
for operator in ['le','gt']: #選擇操作符,獲得最優操作符號
thresholdValue = attributeMin + j*stepSize #分類閾值
estimateLabel = decisionRoot.classify(data[:,rootAttribute],operator,thresholdValue) #估計標籤
errLabel = numpy.matrix(numpy.ones((samples,1)))
errLabel[estimateLabel == label] = 0
error = float(distribute*errLabel) #計算分類誤差
if error < minError:
minError = error #將最小誤差的引數記錄
self._minError = minError
self._rootAttribute = rootAttribute
self._thresholdValue = thresholdValue
self._operator = operator
self._estimateLabel = estimateLabel.copy()
def predict(self,data): #輸入資料,預測結果
samples = data.shape[0]
result = numpy.matrix(decisionRoot.classify(data[:,self._rootAttribute],self._operator,self._thresholdValue))
return result
class AdaBoost:
def __init__(self):
self._rootNumber = 0 #訓練分類樹樁的數目
self._decisionRootArray = [] #儲存訓練好的分類樹樁
self._alphaList = [] #分類樹樁對應的alpha列表
@classmethod
def exp(cls,vector): #對向量裡的所有成員使用exp函式
for i in range(len(vector)):
vector[i,0] = math.exp(vector[i,0])
return vector
def trainRoot(self,data,label,rootNumber = 41): #序列訓練樹樁,並存儲訓練好的分類器
samples,attributes = data.shape
self._rootNumber = rootNumber
distribute = numpy.matrix(numpy.ones((1,samples))/float(samples))
for i in range(self._rootNumber): #訓練給定數目的基分類器
root = decisionRoot()
root.buildTree(data,label,distribute) #建立分類樹樁
alpha = 0.5 * math.log((1.0 - root._minError)/max(root._minError,1e-16))
self._alphaList.append(alpha)
expValue = AdaBoost.exp(numpy.multiply(-1*alpha*label,root._estimateLabel))
distribute = numpy.multiply(distribute,expValue.T)
distribute = distribute/float(distribute.sum()) #更新分佈
self._decisionRootArray.append(root)
def vote(self,predictMatrix): #投票法決定分類結果
samples = predictMatrix[0].shape[0]
result = []
for i in range(samples):
sign = 0
for j in range(self._rootNumber):
sign += predictMatrix[j][i,0] * self._alphaList[j] #計算sign函式的輸入值
if sign >= 0:
result.append(1)
else:
result.append(-1) #記錄投票結果
return result
def predict(self,data): #根據眾多訓練好的分類器,整合投票結果
predictMatrix = []
for i in range(self._rootNumber): #遍歷每一個分類器,得到分類值
root = self._decisionRootArray[i]
result = root.predict(data)
predictMatrix.append(result)
return numpy.matrix(self.vote(predictMatrix)).T #返回各個分類器的投票結果
def assess(predictResult,actualLabel): #評估分類器正確率
count = 0
for i in range(predictResult.shape[0]):
if predictResult[i,0] == actualLabel[i,0]:
count += 1
return count/ float(predictResult.shape[0])測試函式
if __name__ == '__main__':
dataSet = loadData()
data,label = dataPrepreocess(dataSet)
trainData,trainLabel,testData,testLabel = dataSplit(data,label) #獲得訓練集、測試集
Ada = AdaBoost()
Ada.trainRoot(trainData,trainLabel)
result = Ada.predict(testData)
print(assess(result,testLabel))四、AdaBoost演算法效能的影響因素
4.1 結合策略
1)平均法
對數值型輸出hi(x),最常見的結合策略是使用平均法,平均法又分為簡單平均法和加權平均法,其公式可統一為
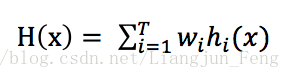
其中wi是基學習器的權重,通常要求wi >= 0,同時權重之和為1,簡單平均法是加權平均法為wi = 1/T的特例。AdaBoost演算法應用的就是這種加權平均法
2)投票法
對分類任務來說,學習器hi從類別標記集合{c1,c2,…,cN}中預測出一個標記,為方便討論,我們將hi在樣本x上的預測輸出為一個N維向量
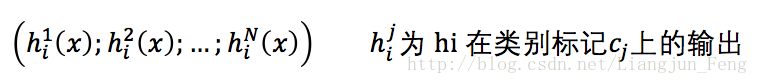
投票法有絕對多數投票法
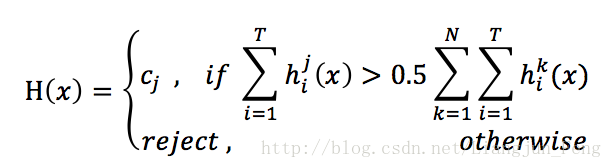
即若某標記得票數過半,則預測為該標記;否則拒絕預測
相對多數投票法
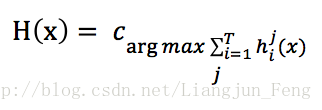
即預測為得票最多的標記,若同時有多個標記獲得最高票,則從中隨機選取一個
加權投票法
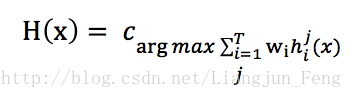
與加權平均法類似,通常要求wi >= 0,同時權重之和為1
3)學習法
學習法相比於之前的兩種方式較為複雜,需要先從初始資料集訓練出初級學習器,然後“生成”一個新的資料集用於訓練次級學習器,在這個新資料集中,初級學習器的輸出被當作樣例輸入特徵,而初始樣本的標記仍被當作樣例標記。這裡不在過多贅述這種方法
4.2 多樣性增強
1)資料樣本擾動
給定資料集,可以從中產出不同的資料子集,再利用不同的資料子集訓練出不同的個體學習器,資料樣本擾動是基於取樣法
資料樣本擾動對於一些“不穩定的基學習器”較為有效,例如決策樹、神經網路等等,訓練樣本稍加變化就會導致學習器有顯著變動
2)輸入屬性擾動
訓練樣本通常由一組屬性描述,不同子空間提供了資料的不同觀察視角。顯然,從不同子空間訓練出的個體學習器必然有所不同,隨機森林演算法採用的就是這一策略
五、AdaBoost演算法的優缺點
演算法優點:
AdaBoost演算法具有能夠顯著改善分類器預測精度、不需要先驗知識、理論紮實等優點,但其更重要的意義在於為研究和解決實際問題帶來了新的思想,在學大多數學習演算法通過構造越來越複雜的分類器來提高預測精度時,AdaBoos卻追求將最簡單的、比隨機猜測略好的弱分類器組合得到強分類器
演算法缺點:
1) 對噪聲資料敏感,Adaboost演算法選擇指數損失函式,這個函式過度的聚焦於始終難以被準確分類的樣本,而這些樣本通常是噪聲和奇異值點,這一現象又會使分類器精度下降、出現“退化”問題
2) 與二分類問題相比,Boosting演算法群的多分類理論並不完善,尋找更多適合多分類問題的損失函式,以及多分類下的精確弱分類條件都是值得繼續研究的問題
六、隨機森林演算法簡介
隨機森林(Random Forest,RF)在以決策樹為基學習器的基礎上,進一步在決策樹的訓練過程中引入了隨機屬性選擇。具體來說,傳統決策樹在選擇劃分屬性時是在當前結點的屬性集合(假定有d個屬性)中選擇一個最優屬性;而在RF中,對基決策樹的每個結點,先從該結點的屬性集合中隨機選擇一個包含k個屬性的子集,然後再從這個子集中選擇一個最優屬性用於劃分,這裡的引數k控制了隨機性的引入程度。
隨機森林簡單、容易實現、計算開銷小,令人驚奇的是,它在很多現實任務中展現出強大的效能,被譽為“代表整合學習技術水平的方法”。