
HDU2222 多串匹配 (AC自動機)
AC自動機簡介:
首先簡要介紹一下AC自動機:Aho-Corasick automation,該演算法在1975年產生於貝爾實驗室,是著名的多模匹配演算法之一。一個常見的例子就是給出n個單詞,再給出一段包含m個字元的文章,讓你找出有多少個單詞在文章裡出現過。要搞懂AC自動機,先得有字典樹Trie和KMP模式匹配演算法的基礎知識。KMP演算法是單模式串的字元匹配演算法,AC自動機是多模式串的字元匹配演算法。
AC自動機的構造:
1.構造一棵Trie,作為AC自動機的搜尋資料結構。
2.構造fail指標,使當前字元失配時跳轉到具有最長公共前後綴的字元繼續匹配。如同 KMP演算法一樣, AC自動機在匹配時如果當前字元匹配失敗,那麼利用fail指標進行跳轉。由此可知如果跳轉,跳轉後的串的字首,必為跳轉前的模式串的字尾並且跳轉的新位置的深度(匹配字元個數)一定小於跳之前的節點。所以我們可以利用 bfs在 Trie上面進行 fail指標的求解。
3.掃描主串進行匹配。
AC自動機詳講:
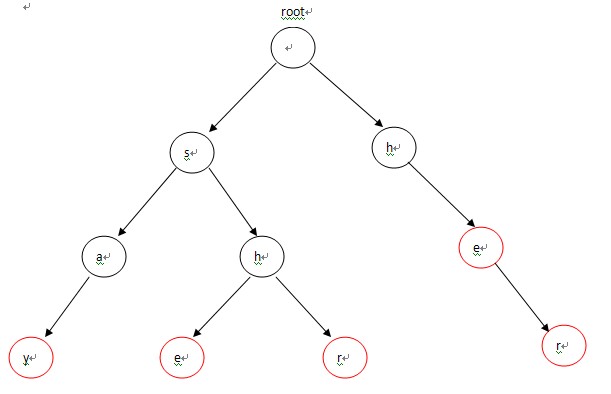
我們給出5個單詞,say,she,shr,he,her。給定字串為yasherhs。問多少個單詞在字串中出現過。
一、Trie
首先我們需要建立一棵Trie。但是這棵Trie不是普通的Trie,而是帶有一些特殊的性質。
首先會有3個重要的指標,分別為p, p->fail, temp。
1.指標p,指向當前匹配的字元。若p指向root,表示當前匹配的字元序列為空。(root是Trie入口,沒有實際含義)。
2.指標p->fail,p的失敗指標,指向與字元p相同的結點,若沒有,則指向root。
3.指標temp,測試指標(自己命名的,容易理解!~),在建立fail指標時有尋找與p字元匹配的結點的作用,在掃描時作用最大,也最不好理解。
對於Trie樹中的一個節點,對應一個序列s[1...m]。此時,p指向字元s[m]。若在下一個字元處失配,即p->next[s[m+1]] == NULL,則由失配指標跳到另一個節點(p->fail)處,該節點對應的序列為s[i...m]。若繼續失配,則序列依次跳轉直到序列為空或出現匹配。在此過程中,p的值一直在變化,但是p對應節點的字元沒有發生變化。在此過程中,我們觀察可知,最終求得得序列s則為最長公共字尾。另外,由於這個序列是從root開始到某一節點,則說明這個序列有可能是某些序列的字首。
再次討論p指標轉移的意義。如果p指標在某一字元s[m+1]處失配(即p->next[s[m+1]] == NULL),則說明沒有單詞s[1...m+1]存在。此時,如果p的失配指標指向root,則說明當前序列的任意字尾不會是某個單詞的字首。如果p的失配指標不指向root,則說明序列s[i...m]是某一單詞的字首,於是跳轉到p的失配指標,以s[i...m]為字首繼續匹配s[m+1]。
對於已經得到的序列s[1...m],由於s[i...m]可能是某單詞的字尾,s[1...j]可能是某單詞的字首,所以s[1...m]中可能會出現單詞。此時,p指向已匹配的字元,不能動。於是,令temp = p,然後依次測試s[1...m], s[i...m]是否是單詞。
構造的Trie為:
二、構造失敗指標
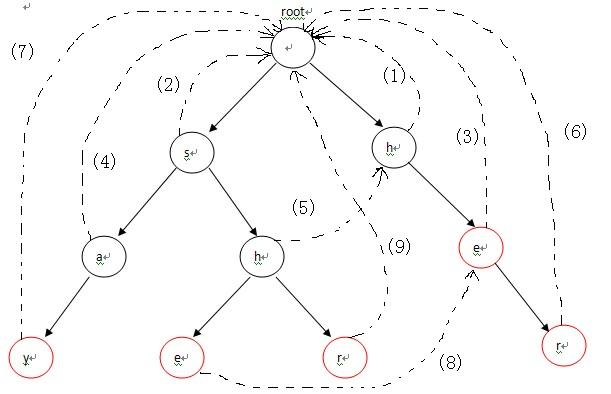
用BFS來構造失敗指標,與KMP演算法相似的思想。
首先,root入隊,第1次迴圈時處理與root相連的字元,也就是各個單詞的第一個字元h和s,因為第一個字元不匹配需要重新匹配,所以第一個字元都指向root(root是Trie入口,沒有實際含義)失敗指標的指向對應下圖中的(1),(2)兩條虛線;第2次進入迴圈後,從佇列中先彈出h,接下來p指向h節點的fail指標指向的節點,也就是root;p=p->fail也就是p=NULL說明匹配序列為空,則把節點e的fail指標指向root表示沒有匹配序列,對應圖-2中的(3),然後節點e進入佇列;第3次迴圈時,彈出的第一個節點a的操作與上一步操作的節點e相同,把a的fail指標指向root,對應圖-2中的(4),併入隊;第4次進入迴圈時,彈出節點h(圖中左邊那個),這時操作略有不同。由於p->next[i]!=NULL(root有h這個兒子節點,圖中右邊那個),這樣便把左邊那個h節點的失敗指標指向右邊那個root的兒子節點h,對應圖-2中的(5),然後h入隊。以此類推:在迴圈結束後,所有的失敗指標就是圖-2中的這種形式。
三、掃描
構造好Trie和失敗指標後,我們就可以對主串進行掃描了。這個過程和KMP演算法很類似,但是也有一定的區別,主要是因為AC自動機處理的是多串模式,需要防止遺漏某個單詞,所以引入temp指標。
匹配過程分兩種情況:(1)當前字元匹配,表示從當前節點沿著樹邊有一條路徑可以到達目標字元,此時只需沿該路徑走向下一個節點繼續匹配即可,目標字串指標移向下個字元繼續匹配;(2)當前字元不匹配,則去當前節點失敗指標所指向的字元繼續匹配,匹配過程隨著指標指向root結束。重複這2個過程中的任意一個,直到模式串走到結尾為止。
對照上圖,看一下模式匹配這個詳細的流程,其中模式串為yasherhs。對於i=0,1。Trie中沒有對應的路徑,故不做任何操作;i=2,3,4時,指標p走到左下節點e。因為節點e的count資訊為1,所以cnt+1,並且講節點e的count值設定為-1,表示改單詞已經出現過了,防止重複計數,最後temp指向e節點的失敗指標所指向的節點繼續查詢,以此類推,最後temp指向root,退出while迴圈,這個過程中count增加了2。表示找到了2個單詞she和he。當i=5時,程式進入第5行,p指向其失敗指標的節點,也就是右邊那個e節點,隨後在第6行指向r節點,r節點的count值為1,從而count+1,迴圈直到temp指向root為止。最後i=6,7時,找不到任何匹配,匹配過程結束。
到此,AC自動機入門知識就講完了。HDU 2222入門題必須果斷A掉,反正我是參考別人程式碼敲的。。。
AC自動機貌似還有很多需要優化的地方,等把基礎搞定之後再學習一下怎麼優化吧。。
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <cmath>
#include <map>
#include <queue>
using namespace std;
#define MAXN 275005
#define MOD 1000000
#define LL long long int
struct node
{
int v;
node *next[26];
node *fail;
}*root;
char S[1000005];
queue<node*> Q;
int main()
{
int T, n;
char s[55];
node *p, *temp;
scanf("%d", &T);
while (T--)
{
//////////////////////建字典樹
root = new node();
scanf("%d", &n);
for (int i = 0; i < n; ++i)
{
scanf("%s", s);
int len = strlen(s);
p = root;
for (int i = 0; i < len; ++i)
{
int t = s[i] - 'a';
if (p->next[t] == NULL)
p->next[t] = new node();
p = p->next[t];
}
p->v += 1;
}
/////////////////////完成fail指標
Q.push(root);
while (!Q.empty())
{
p = Q.front();
Q.pop();
for (int i = 0; i < 26; ++i)
{
if (p->next[i] != NULL)
{
Q.push(p->next[i]);
if (p == root)
p->next[i]->fail = root;
else
{
temp = p->fail;
while (temp != NULL)
{
if (temp->next[i] != NULL)
{
p->next[i]->fail = temp->next[i];
break;
}
temp = temp->fail;
}
if (temp == NULL)
p->next[i]->fail = root;
}
}
}
}
//////////////////////搜尋
scanf("%s", S);
int len = strlen(S);
int ans = 0;
p = root;
for (int i = 0; i < len; ++i)
{
int t = S[i] - 'a';
temp = NULL;
while (p->next[t] == NULL && p != root)
{
p = p->fail;
}
if (p == root)
{
if (p->next[t] != NULL)
{
temp = p = p->next[t];
}
}
else
{
temp = p = p->next[t];
}
while (temp != NULL)
{
if (temp->v >= 0)
{
ans += temp->v;
temp->v = -1;
temp = temp->fail;
}
else
temp = NULL;
}
}
printf("%d\n", ans);
}
}