
HipHop演算法:利用微博互動關係挖掘社交圈
/*.*/
CopyMiddle: 張俊林
TimeStamp:2012年3 月
在微博環境下,如何自動挖掘某個微博使用者的社交圈子或者興趣圈子是個很基礎且重要的問題。如果能夠對於某個使用者在微博上體現的社交關係進行準確的挖掘,對於很多具體應用來說都有很好的作用,比如可以更好的對使用者的興趣進行挖掘或者能夠推薦使用者還未關注的社交圈子成員等,或者根據其社交圈子更準確的對使用者進行個性化建模,為其它基於使用者個性化模型的推薦或者廣告推送等提供基礎服務。
我們在微博相關研發任務中提出了HipHop演算法,旨在通過利用微博使用者的互動行為,來自動挖掘出使用者的不同社交圈子。在設計演算法之初,我們希望圈子挖掘演算法能同時滿足以下幾個條件:
1. 對於某個微博使用者A來說,可以挖掘出其所屬的多種社交圈子,比如使用者既有同事關係圈,也有所屬的專業興趣圈。
2. 同時對於另外一個使用者B來說,可能同時屬於使用者A的不同社交圈子,比如B既是A的大學同學,也是A的某公司同事,那麼B應該同時出現在使用者A的兩個不同興趣圈裡。
3. 不使用使用者隱私資料,出於保護使用者隱私的目的,我們希望演算法只使用使用者公開行為和資訊,所以HipHop演算法只使用了互動關係這種公眾完全可見的公開資訊。
4. 社交圈可解釋,即可以通過簡潔的方式描述社交圈子的性質或者特點,目前是通過給每個圈子打上不同的標籤來進行區分。
HipHop社交圈挖掘演算法就是在以上幾個指導原則下設計開發出的,它能夠同時滿足以上幾條約束條件,目前公開的參考文獻中很少見到能夠同時滿足這些條件的相關社交圈挖掘演算法。
常見的社交圈挖掘演算法
社交圈挖掘是目前社交網路研究中非常典型和熱門的研究任務,通常被稱為“社群發現“。學術界也陸續提出了很多演算法來解決這個問題,大體而言,可以將其分為兩大類:”單社群“方法和”多社群“方法。所謂”單社群“方法,就是說網路結構中的某個節點只能隸屬於某個社群,不允許出現隸屬多個社群的現象。而”多社群“方法則允許使用者同時隸屬於多個社群。下面分別以GN演算法和”最大團結構“作為這兩類演算法的代表對其思路進行簡要介紹。
GN演算法
GN演算法是一種非常常用的圖結構中社群自動發現演算法,最初由Girvan和Newman在2002年提出,因其有效性得到了廣泛的使用。
GN演算法的基本思想是:在圖結構中,首先計算每條邊的“介數”,然後從圖中刪除“介數”最大的邊,如此不斷迴圈,一直迭代刪除當前“介數”最大的邊,最終就形成了發現出的社群。所謂邊的“介數”,是指的圖中任意兩個節點的最短路徑中經過這條邊的次數。邊的“介數”越大,則這條邊是連線了兩個或者多個社群或者圈子的多餘的邊的概率越大,所以通過不斷刪除高“介數”邊可以達到分離社群的目的。
GN演算法是有效的演算法,但是這是一種“單社群”發現方法,就是說,對於圖中某個節點,只能屬於固定的一個社群,不可能同時屬於多個社群,這個與實際應用場景需求是有較大差異的,形成了該演算法的侷限。
“最大團結構“演算法
“最大團結構”(max clique)是一種比較流行的能夠進行“多社群”發現演算法,即圖中的節點可以同時隸屬於多個不同的社群。
“最大團結構”通過對圖的拓撲結構進行分析,找到滿足“最大團”性質的子圖結構,也就是最大的全聯通子圖,每個“最大團”就是一個發現的社群。
儘管“最大團結構”演算法可以發現某個節點屬於多個社群,比“單社群”發現方法有更多的實用性和應用場景,但是這個演算法有其侷限:因為“最大團結構”要求是全聯通子圖,即子圖中任意兩個節點都有邊連線,這是一種非常強的約束。真實應用的圖中往往滿足如此強約束的這種圖結構很小或者很少,這導致這個演算法很多圖中的節點無法歸入某個社群。
HipHop演算法在某個步驟也採取了“最大團結構”的思想,但是通過技術手段放鬆了這種約束,有效地改進了其效果。
利用HipHop演算法發現微博裡的社交圈
Hiphop演算法利用微博使用者的互動關係來自動挖掘某個使用者的不同社交圈子。這裡的“互動”是一種總稱,具體互動內容包括:轉發微博、評論微博和@其它使用者等行為,如果使用者A和使用者B有任意上述提到的行為則可以認為兩者有互動關係存在,且根據其頻率可以賦予邊不同的強度,代表了兩個使用者的社交親密程度。
我們之所以使用社交關係來挖掘社交圈,是基於以下的一個基本假設:和某個微博使用者進行過互動行為的人群存在不同的小團體,而小團體成員之內有較為密切的互動行為,不同小團體之間成員之間互動行為較少。比如你的大學同學之間在微博上有較多互動行為,但是他們和你的同事之間就很少有互動行為(參考圖1)。儘管這只是一種假設,但是實際挖掘效果表明大多數情況下這個假設是成立的。
HipHop演算法的技術流程可以劃分為順序進行的三個步驟:
步驟一:從與使用者有直接互動的其它使用者中尋找“最大團結構”
首先,對於某個微博使用者A,所有和使用者A在微博上有過直接互動行為的使用者形成直接互動集合S。本步驟試圖在集合S中找到多個“最大團結構”,也即挖掘多個小團體的核心成員。
對於集合S中的節點來說,可以根據他們相互之間的互動關係構造一個圖G,在此基礎上去挖掘圖G中的“最大團結構”。所謂“團結構”,就是圖G中包含的任意全連通子圖,比如圖G中的三個節點{a,b,c},如果他們之間任意兩人都有互動關係存在,則形成了一個三節點的“團結構”。而所謂“最大團結構”,是指對於某個“團結構”T來說,無法在圖G中找到任意其它節點n,如果把n納入T,就形成更大的一個“團結構”。比如上述的三節點團結構,如果存在節點d,這個節點和a、b以及c都有互動關係,那麼{a,b,c,d}就形成了一個四節點的“團結構”,而如果找不到節點能夠和{a,b,c}都有互動關係,那麼{a,b,c}就是一個三節點的“最大團結構”。
圖的“團結構”是一個非常強的約束,因為它要求圖中任意兩個節點都存在互動關係。步驟一找出的某個使用者A的“最大團結構”的物理含義是:和使用者A有密切關係的那些使用者中,有哪些是有密切聯絡的小團體。
步驟二:“最大團結構”在直接互動使用者集合的擴充
步驟一找出了與使用者A有過直接互動行為的集合S中形成的“最大團結構”,步驟二在此基礎上,在集合S範圍內對每個發現的“最大團結構”進行擴充,來發現更多屬於某個“最大團結構”的其它使用者。具體的擴充方式如下:
對於某個具體的“最大團結構”T,其包含若干使用者,首先找到和T中使用者有過互動行為,同時又在集合S中的其它使用者,我們簡稱這個集合為U。對於U中的某個使用者w,我們需要判斷是否應該將其擴充進入“最大團結構”T,目前的判斷標準採取如下公式:
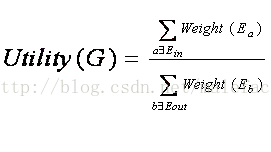
假設G是最大團T將使用者w融合後形成的新圖,公式的分子部分代表新圖G中所有節點內部邊的權重之和,而分母部分代表圖G中所有節點和圖G之外的任意節點形成的所有邊權重之和。如果Utility(G)函式比未擴充節點w的原圖結構T的效用函式Utility(T)值大,那麼我們認為將節點w擴充進入T是合理的,否則不應該將節點w擴充進入圖T中。有了這個函式作為標準,我們就知道集合U中的使用者哪些應該擴充進入團結構T中,而哪些應該被捨棄。
之所以採取上述公式作為判斷標準,是基於之前提到的如下假設:一個社交圈子成員之間互動關係密切,而圈子成員與圈子外成員之間的互動關係不是很密切。上述公式就是這個基本假設的具體體現,分子部分是衡量圈子成員內部的關係緊密程度,而分母衡量的是圈子成員和圈子外成員的關係緊密程度。從公式可以看出,如果圈子成員之間互動越多,而與圈子外成員互動越少,則效用函式越大,也就是說這個圈子越緊密。
如果對於集合U中所有後續擴充使用者都採用上述公式進行判斷取捨,來做出是否將這個使用者擴充進入“最大團結構”T的決策,則就完成了T的一輪擴充,形成了擴充後的新集合T’。對於T’來說,仍然可以採取上述擴充方法不斷外擴。“最大團結構”T外擴的終止條件是:如果對於集合U中所有使用者,做出的決策都是不進行擴充,那麼此時已經達到了擴充的邊界,可以停止外擴,形成最終擴充結果。
如果對步驟一中發現的所有“最大團結構”都採取上述方式外擴,即完成了步驟二的任務。從上述過程可以看出,步驟二是對步驟一的擴充階段。
步驟三:與使用者有“二級互動“關係的其它使用者集合中的擴充
所謂使用者A的“二級互動”使用者集合,是指與使用者A有直接互動的使用者形成集合S,而與集合S中任意一個使用者有互動行為的所有其他使用者形成了二級互動集合。
對於步驟二的結果來說,完成了對“最大團結構”的擴充,在直接互動使用者集合中找到了不同的社交圈子。步驟三首先將直接互動使用者集合S擴充為二級互動使用者集合,然後採取和步驟二類似的方法繼續向外擴充,這樣就形成了HipHop演算法的最終結果,形成了使用者A的多個不同社交圈子,而任意一個其他使用者B可能同時屬於使用者A的多個社交圈。
通過上述三個步驟,就可以通過微博互動關係自動挖掘出某個使用者的社交關係圈子。對於微博的海量使用者而言,只要對每個使用者都依次採取上述步驟,即可獲得最終結果,這可以採取大規模平行計算來快速實現。
下面我們用一個具體例子來說明HipHop演算法。以“李開復”作為示例,說明上述步驟及其中間輸出結果。
對於步驟一,首先找到與“李開復”有過互動的微博成員形成集合S,之後在集合S裡採用發現“最大團結構”的方法,可以得到最初的5個“最大團結構”:
最大團1(創新工場有關):王肇輝/蔡學鏞/周源/張亮/徐磊Ryan
最大團2(網際網路媒體相關):keso已被XX/牛立雄/金磊
最大團3(財經投資相關):徐小平/愛國者馮軍/潘石屹/楊瀾
最大團4(創新工場有關):郎春輝/羅川/袁聰iw/應用匯
最大團5(企業家相關):曹國偉/江南春/吳徵bruno/蔣錫培
經過步驟二,對原始的5個最大團在集合S中進行擴充,每個原始的最大團都有不同程度的擴大,其新擴充進的成員範圍在3-10個不等。
步驟三首先將直接互動成員集合S擴充為二級互動成員集合,即將與集合S中成員有過互動行為的微博使用者形成新的更大範圍的集合。通過上文講述的擴充方式後,5個最初的“最大團結構”獲得了進一步的擴充,最後形成了包含48個到150個成員的不同社交圈子。
經過人工評估,HipHop演算法挖掘出的社交圈有較強的社交內聚度,同時也滿足演算法設計之初設定的幾個約束條件,所以具有很強的實用性。同時,經過大量例項的分析,我們發現在微博中形成的社交關係和IM形成的社交關係有較大的差異,大部分使用者的微博中的社交關係以同事關係和興趣關係為主,而IM中形成的社交關係則以親友、同事、同學等線下關係為主,這可能反映了社會化媒體和傳統社交網路的區別所在。