
Etcd 架構與實現解析
前一段時間的專案裡用到了 Etcd, 所以研究了一下它的原始碼以及實現。網上關於 Etcd 的使用介紹的文章不少,但分析具體架構實現的文章不多,同時 Etcd v3的文件也非常稀缺。本文通過分析 Etcd 的架構與實現,瞭解其優缺點以及瓶頸點,一方面可以學習分散式系統的架構,另外一方面也可以保證在業務中正確使用 Etcd,知其然同時知其所以然,避免誤用。最後介紹 Etcd 周邊的工具和一些使用注意事項。
閱讀物件:分散式系統愛好者,正在或者打算在專案中使用Etcd的開發人員。
Etcd 按照官方介紹
Etcd is a distributed, consistent key-value
store for shared configuration and service discovery
是一個分散式的,一致的 key-value 儲存,主要用途是共享配置和服務發現。Etcd 已經在很多分散式系統中得到廣泛的使用,本文的架構與實現部分主要解答以下問題:
- Etcd是如何實現一致性的?
- Etcd的儲存是如何實現的?
- Etcd的watch機制是如何實現的?
- Etcd的key過期機制是如何實現的?
為什麼需要 Etcd ?
所有的分散式系統,都面臨的一個問題是多個節點之間的資料共享問題,這個和團隊協作的道理是一樣的,成員可以分頭幹活,但總是需要共享一些必須的資訊,比如誰是 leader, 都有哪些成員,依賴任務之間的順序協調等。所以分散式系統要麼自己實現一個可靠的共享儲存來同步資訊(比如 Elasticsearch ),要麼依賴一個可靠的共享儲存服務,而 Etcd 就是這樣一個服務。
Etcd 提供什麼能力?
Etcd 主要提供以下能力,已經熟悉 Etcd 的讀者可以略過本段。
- 提供儲存以及獲取資料的介面,它通過協議保證 Etcd 叢集中的多個節點資料的強一致性。用於儲存元資訊以及共享配置。
- 提供監聽機制,客戶端可以監聽某個key或者某些key的變更(v2和v3的機制不同,參看後面文章)。用於監聽和推送變更。
- 提供key的過期以及續約機制,客戶端通過定時重新整理來實現續約(v2和v3的實現機制也不一樣)。用於叢集監控以及服務註冊發現。
- 提供原子的CAS(Compare-and-Swap)和 CAD(Compare-and-Delete)支援(v2通過介面引數實現,v3通過批量事務實現)。用於分散式鎖以及leader選舉。
更詳細的使用場景不在這裡描述,有興趣的可以參看文末infoq的一篇文章。
Etcd 如何實現一致性的?
說到這個就不得不說起raft協議。但這篇文章不是專門分析raft的,篇幅所限,不能詳細分析,有興趣的建議看文末原始論文地址以及raft協議的一個動畫。便於看後面的文章,我這裡簡單做個總結:
- raft通過對不同的場景(選主,日誌複製)設計不同的機制,雖然降低了通用性(相對paxos),但同時也降低了複雜度,便於理解和實現。
- raft內建的選主協議是給自己用的,用於選出主節點,理解raft的選主機制的關鍵在於理解raft的時鐘週期以及超時機制。
- 理解 Etcd 的資料同步的關鍵在於理解raft的日誌同步機制。
Etcd 實現raft的時候,充分利用了go語言CSP併發模型和chan的魔法,想更進行一步瞭解的可以去看原始碼,這裡只簡單分析下它的wal日誌。

wal日誌是二進位制的,解析出來後是以上資料結構LogEntry。其中第一個欄位type,只有兩種,一種是0表示Normal,1表示ConfChange(ConfChange表示 Etcd 本身的配置變更同步,比如有新的節點加入等)。第二個欄位是term,每個term代表一個主節點的任期,每次主節點變更term就會變化。第三個欄位是index,這個序號是嚴格有序遞增的,代表變更序號。第四個欄位是二進位制的data,將raft request物件的pb結構整個儲存下。Etcd 原始碼下有個tools/etcd-dump-logs,可以將wal日誌dump成文字檢視,可以協助分析raft協議。
raft協議本身不關心應用資料,也就是data中的部分,一致性都通過同步wal日誌來實現,每個節點將從主節點收到的data apply到本地的儲存,raft只關心日誌的同步狀態,如果本地儲存實現的有bug,比如沒有正確的將data apply到本地,也可能會導致資料不一致。
Etcd v2 與 v3
Etcd v2 和 v3 本質上是共享同一套 raft 協議程式碼的兩個獨立的應用,介面不一樣,儲存不一樣,資料互相隔離。也就是說如果從 Etcd v2 升級到 Etcd v3,原來v2 的資料還是隻能用 v2 的介面訪問,v3 的介面建立的資料也只能訪問通過 v3 的介面訪問。所以我們按照 v2 和 v3 分別分析。
Etcd v2 儲存,Watch以及過期機制
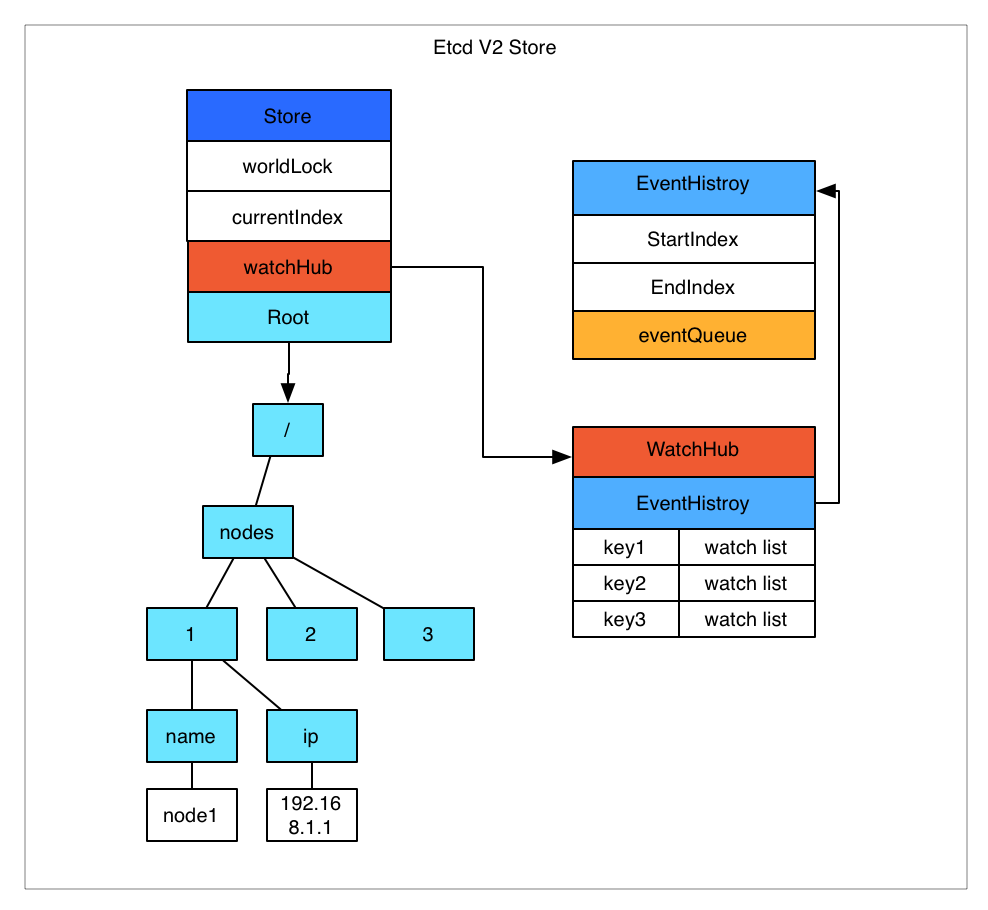
Etcd v2 是個純記憶體的實現,並未實時將資料寫入到磁碟,持久化機制很簡單,就是將store整合序列化成json寫入檔案。資料在記憶體中是一個簡單的樹結構。比如以下資料儲存到 Etcd 中的結構就如圖所示。
/nodes/1/name node1
/nodes/1/ip 192.168.1.1
store中有一個全域性的currentIndex,每次變更,index會加1.然後每個event都會關聯到currentIndex.
當客戶端呼叫watch介面(引數中增加 wait引數)時,如果請求引數中有waitIndex,並且waitIndex 小於 currentIndex,則從 EventHistroy 表中查詢index小於等於waitIndex,並且和watch key 匹配的 event,如果有資料,則直接返回。如果歷史表中沒有或者請求沒有帶 waitIndex,則放入WatchHub中,每個key會關聯一個watcher列表。 當有變更操作時,變更生成的event會放入EventHistroy表中,同時通知和該key相關的watcher。
這裡有幾個影響使用的細節問題:
- EventHistroy 是有長度限制的,最長1000。也就是說,如果你的客戶端停了許久,然後重新watch的時候,可能和該waitIndex相關的event已經被淘汰了,這種情況下會丟失變更。
- 如果通知watch的時候,出現了阻塞(每個watch的channel有100個緩衝空間),Etcd 會直接把watcher刪除,也就是會導致wait請求的連線中斷,客戶端需要重新連線。
- Etcd store的每個node中都儲存了過期時間,通過定時機制進行清理。
從而可以看出,Etcd v2 的一些限制:
- 過期時間只能設定到每個key上,如果多個key要保證生命週期一致則比較困難。
- watch只能watch某一個key以及其子節點(通過引數 recursive),不能進行多個watch。
- 很難通過watch機制來實現完整的資料同步(有丟失變更的風險),所以當前的大多數使用方式是通過watch得知變更,然後通過get重新獲取資料,並不完全依賴於watch的變更event。
Etcd v3 儲存,Watch以及過期機制
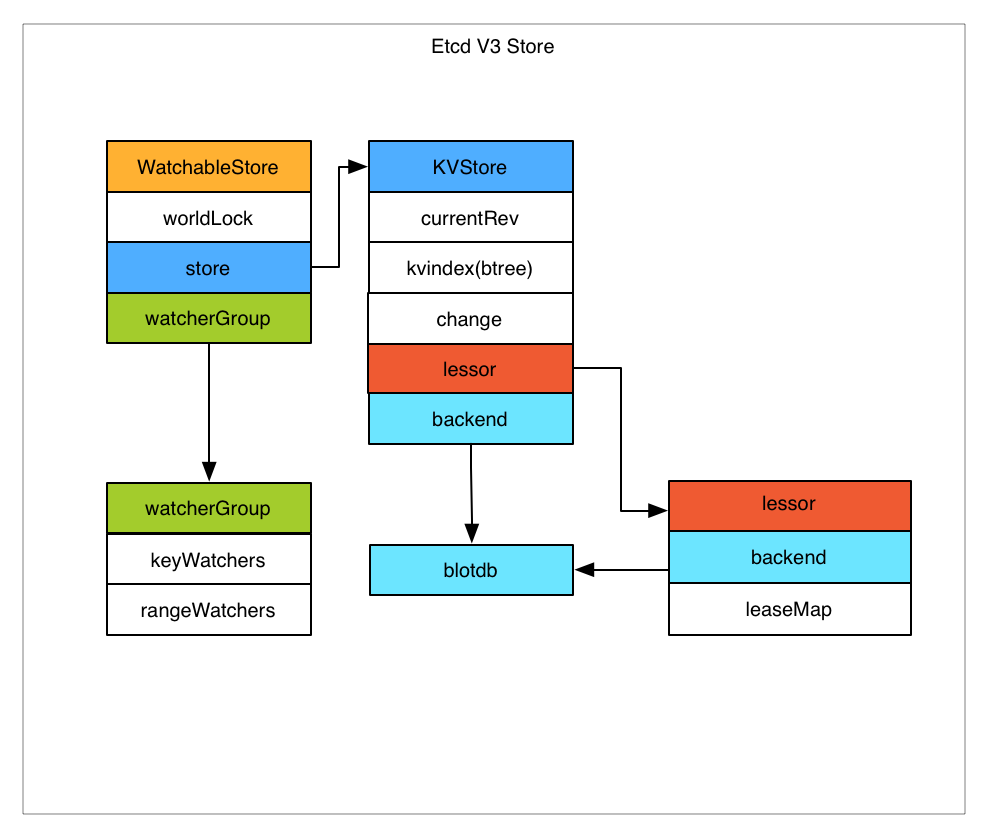
Etcd v3 將watch和store拆開實現,我們先分析下store的實現。
Etcd v3 store 分為兩部分,一部分是記憶體中的索引,kvindex,是基於google開源的一個golang的btree實現的,另外一部分是後端儲存。按照它的設計,backend可以對接多種儲存,當前使用的boltdb。boltdb是一個單機的支援事務的kv儲存,Etcd 的事務是基於boltdb的事務實現的。Etcd 在boltdb中儲存的key是reversion,value是 Etcd 自己的key-value組合,也就是說 Etcd 會在boltdb中把每個版本都儲存下,從而實現了多版本機制。
舉個例子: 用etcdctl通過批量介面寫入兩條記錄:
etcdctl txn <<<'
put key1 "v1"
put key2 "v2"
'
再通過批量介面更新這兩條記錄:
etcdctl txn <<<'
put key1 "v12"
put key2 "v22"
'
boltdb中其實有了4條資料:
rev={3 0}, key=key1, value="v1"
rev={3 1}, key=key2, value="v2"
rev={4 0}, key=key1, value="v12"
rev={4 1}, key=key2, value="v22"
reversion主要由兩部分組成,第一部分main rev,每次事務進行加一,第二部分sub rev,同一個事務中的每次操作加一。如上示例,第一次操作的main rev是3,第二次是4。當然這種機制大家想到的第一個問題就是空間問題,所以 Etcd 提供了命令和設定選項來控制compact,同時支援put操作的引數來精確控制某個key的歷史版本數。
瞭解了 Etcd 的磁碟儲存,可以看出如果要從boltdb中查詢資料,必須通過reversion,但客戶端都是通過key來查詢value,所以 Etcd 的記憶體kvindex儲存的就是key和reversion之前的對映關係,用來加速查詢。
然後我們再分析下watch機制的實現。Etcd v3 的watch機制支援watch某個固定的key,也支援watch一個範圍(可以用於模擬目錄的結構的watch),所以 watchGroup 包含兩種watcher,一種是 key watchers,資料結構是每個key對應一組watcher,另外一種是 range watchers, 資料結構是一個 IntervalTree(不熟悉的參看文文末連結),方便通過區間查詢到對應的watcher。
同時,每個 WatchableStore 包含兩種 watcherGroup,一種是synced,一種是unsynced,前者表示該group的watcher資料都已經同步完畢,在等待新的變更,後者表示該group的watcher資料同步落後於當前最新變更,還在追趕。
當 Etcd 收到客戶端的watch請求,如果請求攜帶了revision引數,則比較請求的revision和store當前的revision,如果大於當前revision,則放入synced組中,否則放入unsynced組。同時 Etcd 會啟動一個後臺的goroutine持續同步unsynced的watcher,然後將其遷移到synced組。也就是這種機制下,Etcd v3 支援從任意版本開始watch,沒有v2的1000條歷史event表限制的問題(當然這是指沒有compact的情況下)。
另外我們前面提到的,Etcd v2在通知客戶端時,如果網路不好或者客戶端讀取比較慢,發生了阻塞,則會直接關閉當前連線,客戶端需要重新發起請求。Etcd v3為了解決這個問題,專門維護了一個推送時阻塞的watcher佇列,在另外的goroutine裡進行重試。
Etcd v3 對過期機制也做了改進,過期時間設定在lease上,然後key和lease關聯。這樣可以實現多個key關聯同一個lease id,方便設定統一的過期時間,以及實現批量續約。
相比Etcd v2, Etcd v3的一些主要變化:
- 介面通過grpc提供rpc介面,放棄了v2的http介面。優勢是長連線效率提升明顯,缺點是使用不如以前方便,尤其對不方便維護長連線的場景。
- 廢棄了原來的目錄結構,變成了純粹的kv,使用者可以通過字首匹配模式模擬目錄。
- 記憶體中不再儲存value,同樣的記憶體可以支援儲存更多的key。
- watch機制更穩定,基本上可以通過watch機制實現資料的完全同步。
- 提供了批量操作以及事務機制,使用者可以通過批量事務請求來實現Etcd v2的CAS機制(批量事務支援if條件判斷)。
Etcd,Zookeeper,Consul 比較
這三個產品是經常被人拿來做選型比較的。 Etcd 和 Zookeeper 提供的能力非常相似,都是通用的一致性元資訊儲存,都提供watch機制用於變更通知和分發,也都被分散式系統用來作為共享資訊儲存,在軟體生態中所處的位置也幾乎是一樣的,可以互相替代的。二者除了實現細節,語言,一致性協議上的區別,最大的區別在周邊生態圈。Zookeeper 是apache下的,用java寫的,提供rpc介面,最早從hadoop專案中孵化出來,在分散式系統中得到廣泛使用(hadoop, solr, kafka, mesos 等)。Etcd 是coreos公司旗下的開源產品,比較新,以其簡單好用的rest介面以及活躍的社群俘獲了一批使用者,在新的一些叢集中得到使用(比如kubernetes)。雖然v3為了效能也改成二進位制rpc介面了,但其易用性上比 Zookeeper 還是好一些。 而 Consul 的目標則更為具體一些,Etcd 和 Zookeeper 提供的是分散式一致性儲存能力,具體的業務場景需要使用者自己實現,比如服務發現,比如配置變更。而Consul 則以服務發現和配置變更為主要目標,同時附帶了kv儲存。 在軟體生態中,越抽象的元件適用範圍越廣,但同時對具體業務場景需求的滿足上肯定有不足之處。
Etcd 的周邊工具
- Confd
在分散式系統中,理想情況下是應用程式直接和 Etcd 這樣的服務發現/配置中心互動,通過監聽 Etcd 進行服務發現以及配置變更。但我們還有許多歷史遺留的程式,服務發現以及配置大多都是通過變更配置檔案進行的。Etcd 自己的定位是通用的kv儲存,所以並沒有像 Consul 那樣提供實現配置變更的機制和工具,而 Confd 就是用來實現這個目標的工具。
Confd 通過watch機制監聽 Etcd 的變更,然後將資料同步到自己的一個本地儲存。使用者可以通過配置定義自己關注那些key的變更,同時提供一個配置檔案模板。Confd 一旦發現數據變更就使用最新資料渲染模板生成配置檔案,如果新舊配置檔案有變化,則進行替換,同時觸發使用者提供的reload指令碼,讓應用程式重新載入配置。
Confd 相當於實現了部分 Consul 的agent以及consul-template的功能,作者是kubernetes的Kelsey Hightower,但大神貌似很忙,沒太多時間關注這個專案了,很久沒有釋出版本,我們著急用,所以fork了一份自己更新維護,主要增加了一些新的模板函式以及對metad後端的支援。confd - Metad
服務註冊的實現模式一般分為兩種,一種是排程系統代為註冊,一種是應用程式自己註冊。排程系統代為註冊的情況下,應用程式啟動後需要有一種機制讓應用程式知道『我是誰』,然後發現自己所在的叢集以及自己的配置。Metad 提供這樣一種機制,客戶端請求 Metad 的一個固定的介面 /self,由 Metad 告知應用程式其所屬的元資訊,簡化了客戶端的服務發現和配置變更邏輯。
Metad 通過儲存一個ip到元資訊路徑的對映關係來做到這一點,當前後端支援Etcd v3,提供簡單好用的 http rest 介面。 它會把 Etcd 的資料通過watch機制同步到本地記憶體中,相當於 Etcd 的一個代理。所以也可以把它當做Etcd 的代理來使用,適用於不方便使用 Etcd v3的rpc介面或者想降低 Etcd 壓力的場景。 metad - Etcd 叢集一鍵搭建指令碼
Etcd 官方那個一鍵搭建指令碼有bug,我自己整理了一個指令碼,通過docker的network功能,一鍵搭建一個本地的 Etcd 叢集便於測試和試驗。一鍵搭建指令碼
Etcd 使用注意事項
- Etcd cluster 初始化的問題
如果叢集第一次初始化啟動的時候,有一臺節點未啟動,通過v3的介面訪問的時候,會報告Error: Etcdserver: not capable 錯誤。這是為相容性考慮,叢集啟動時預設的API版本是2.3,只有當叢集中的所有節點都加入了,確認所有節點都支援v3介面時,才提升叢集版本到v3。這個只有第一次初始化叢集的時候會遇到,如果叢集已經初始化完畢,再掛掉節點,或者叢集關閉重啟(關閉重啟的時候會從持久化資料中載入叢集API版本),都不會有影響。 - Etcd 讀請求的機制
v2 quorum=true 的時候,讀取是通過raft進行的,通過cli請求,該引數預設為true。
v3 –consistency=“l” 的時候(預設)通過raft讀取,否則讀取本地資料。sdk 程式碼裡則是通過是否開啟:WithSerializable option 來控制。
一致性讀取的情況下,每次讀取也需要走一次raft協議,能保證一致性,但效能有損失,如果出現網路分割槽,叢集的少數節點是不能提供一致性讀取的。但如果不設定該引數,則是直接從本地的store裡讀取,這樣就損失了一致性。使用的時候需要注意根據應用場景設定這個引數,在一致性和可用性之間進行取捨。 - Etcd 的 compact 機制
Etcd 預設不會自動 compact,需要設定啟動引數,或者通過命令進行compact,如果變更頻繁建議設定,否則會導致空間和記憶體的浪費以及錯誤。Etcd v3 的預設的 backend quota 2GB,如果不 compact,boltdb 檔案大小超過這個限制後,就會報錯:”Error: etcdserver: mvcc: database space exceeded”,導致資料無法寫入。
腦洞時間
自動上次 Elasticsearch 的文章之後,給自己安排了一個作業,每次分析原始碼後需要提出幾個發散思維的想法,開個腦洞。
- 併發程式碼呼叫分析追蹤工具
當前IDE的程式碼呼叫分析追蹤都是通過靜態的程式碼分析來追蹤方法呼叫鏈實現的,對閱讀分析程式碼非常有用。但程式如果充分使用CSP或者Actor模型後,都通過訊息進行呼叫,沒有了明確的方法呼叫鏈,給閱讀和理解程式碼帶來了困難。如果語言或者IDE能支援這樣的訊息投遞追蹤分析,那應該非常有用。當然我這個只是腦洞,不考慮實現的可能性和複雜度。 - 實現一個通用的 multiple group raft庫
當前 Etcd 的raft實現保證了多個節點資料之間的同步,但明顯的一個問題就是擴充節點不能解決容量問題。要想解決容量問題,只能進行分片,但分片後如何使用raft同步資料?只能實現一個 multiple group raft,每個分片的多個副本組成一個虛擬的raft group,通過raft實現資料同步。當前實現了multiple group raft的有 TiKV 和 Cockroachdb,但尚未一個獨立通用的。理論上來說,如果有了這套 multiple group raft,後面掛個持久化的kv就是一個分散式kv儲存,掛個記憶體kv就是分散式快取,掛個lucene就是分散式搜尋引擎。當然這只是理論上,要真實現複雜度還是不小。
Etcd 的開源產品啟示
Etcd在Zookeeper已經奠定江湖地位的情況下,硬是重新造了一個輪子,並且在生態圈中取得了一席之地。一方面可以看出是社群的形態在變化,溝通機制和對使用者反饋的響應越來越重要,另外一方面也可以看出一個專案的易用的重要性有時候甚至高於穩定性和功能。新的演算法,新的語言都會給重新制造輪子帶來了機會。
gitchat交流群的問答
問:業務使用的etcd v2 升級到 v3 會有什麼問題呢,如何平滑過渡?
答:v2的大多數功能,用v3都能實現,比如用prefix模擬原來的目錄結構,用txn模擬CAS,一般不會有什麼問題。但因為v2和v3的資料是互相隔離的,所以遷移起來略麻煩。建議先在業務中封裝一層,將etcd v2,v3的差異封裝起來,然後通過開關切換。
問:metad的watch是怎麼實現的?
答:metad的watch實現的比較簡單,因為metad的watch返回的不是變更事件,而是最新的結果。所以metad只維護了一個全域性版本號,只要發現客戶端watch的版本小於等於全域性版本號,就直接返回最新結果。
問:etcd和zk都是作為分散式配置管理的元件。均提供了watch功能,選主。作為初使用者,這兩個之間的選取該如何?
答:etcd和zk二者大多數情況下可以互相替代,都是通用的分散式一致性kv儲存。二者之間選擇建議選擇自己的開發棧比較接近並且團隊成員比較熟悉的,比如一種是按語言選擇,go語言的專案用etcd,java的用zk,出問題要看原始碼也容易些。如果是新專案,糾結於二者,那可以分裝一層lib,類似於docker/libkv,同時支援兩種,有需要可以切換。
問:etcd和eureka、consul 的異同,以及各自的適用場景,以及選型原則。這個問題其實可以把zk也包括進來,這些都有相同之處。
答:etcd和zk的選型前面講到了,二者的定位都是通用的一致性kv儲存,而eureka和consul的定位則是專做服務註冊和發現。前二者的優勢當然是通用性,應用廣泛,部署運維的時候容易和已有的服務一起共用,而同時缺點也是太通用了,每個應用的服務註冊都有自己的一套元資料格式,互相整合起來就比較麻煩了,比如想做個通用的api gateway就會遇到元資料格式相容問題。這也成為後二者的優勢。同時因為後二者的目標比較具體,所以可以做一些更高階的功能,比如consul的DNS支援,consul-template工具,eureka的事件訂閱過濾機制。Eureka本身的實現是一個AP系統,也就是說犧牲了一致性,它認為在服務發現和配置中心這個場景下,可用性和分割槽容錯比一致性更重要。 我個人其實更期待後二者的這種專門的解決方案,要是能形成服務註冊標準,那以後應用之間互相互動就容易了。但也有個可能是這種標準由叢集排程系統來形成事實標準。
後二者我瞭解的也不深入,感覺可以另起一篇文章了。
問:接上面,etcd和zk各自都有哪些坑可能會被踩到,都有多坑。掉進去了如何爬起來?
這個坑的概念比較太廣泛了,更詳細的可以翻bug列表。但使用中的大多數坑一般有幾種:
- 誤用導致的坑。要先認識清楚etcd,zk的定位,它需要儲存的是整個叢集共享的資訊,不能當儲存用。比如有人在某個zk的某個資料節點下建立了大量的子節點,然後獲取,導致zk報錯,zk的buffer有個4mb的限制,超過就會報錯。
- 運維方面的坑。etcd,zk這種服務,一般都比較穩定,搭建好後都不用管,但萬一某些節點出問題了,要增加節點恢復系統的時候,可能沒有預案或者操作經驗,導致弄壞叢集。
- 網路分割槽以及可用性設計的坑。設計系統的時候,要想清楚如果etcd或zk整個掛了,或者出現網路分割槽,應用的一部分節點只能連線到少數派的etcd/zk(少數派不可用)的時候,應用會有什麼表現。這種情況下,應用的正確表現應該是服務正常運作,但不支援變更,等etcd/zk叢集恢復後就自動恢復了。但如果設計不當,有自動化的一些行為,可能帶來的故障就大了。
想要少踩坑,一個辦法就是我文中提到的,研究原理知其然同時知其所以然,另外一個問題就是多試驗,出了問題有預案。
問題1:目前已知Etcd可以為別的服務提供服務發現,在這個場景下假設已經存在5個執行Etcd節點的硬體,當一個新的Etcd硬體節點被安裝時,Etcd能否為自己提供服務發現服務,實現Etcd節點的自動發現與加入?
問題2:隨著硬體安裝規模的增加,Etcd的極限是多少,raft是否會因為節點的變多,心跳包的往返而導致同步一次的等待時間變長?
問題3:當規模足夠大,發生網路分割槽時,是否分割槽較小的一批硬體之間的資料是無法完成同步的?
答:這個案例挺有意思,我一個一個回答。
- etcd本來是做服務發現的,如果etcd叢集也需要服務發現,那就再來一個etcd叢集 :)。你可以自己搭建一個etcd cluster或者用etcd官方提供的 discovery.etcd.io。詳細參看:etcd 官方的 op-guide/clustering
- etcd的機制是多節點一致的,所以它的極限有兩部分,一是單機的容量限制,記憶體和磁碟。二是網路開銷,每次raft操作需要所有節點參與,節點越多效能越低。所以擴充套件很多etcd節點是沒有意義的,一般是 3,5,7,9。再多感覺就沒意義了。如果你們不太在意一致性,建議讀請求可以不通過一致性協議,直接讀取節點本地資料。具體方式文中有說明。
- etcd網路分割槽時,少數派是不可用狀態,不支援raft請求,但支援非一致性讀請求。
問:如果跨機房部署服務,是部署兩套ETCD嗎?如果跨機房部署,如何部署及配置?
答:這個要看跨機房的場景。如果是完全無關聯需要公網連線的兩個機房,服務之間一般也不需要共享資料吧?部署兩套互不相干的etcd,各用各的比較合適。但如果是類似於aws的可用區的概念,兩個機房內網互通,搭建兩套叢集為了避免機房故障,可以隨時切換。這個etcd當前沒有太好的解決辦法,建議的辦法是跨可用區部署一個etcd cluster,調整心跳以及選舉超時時間,這個辦法如果有3個可用區機房,每個機房3個節點,掛任何一個機房都不影響整個叢集,但兩個機房就比較尷尬。還有個辦法是兩個叢集之間同步,這個etcdv3提供了一個mirror的工具,但還是不太完善,不過感覺用etcd的watch機制做一個同步工具也不難。這個機制consul倒是提供了,多資料中心的叢集資料同步,互相不影響可用性。
問:在使用 etcd watch 過程中,有沒有一些措施能幫助降低出現驚群(Herd Effect)?
答:這個問題我也遇到了,但沒發現太好的辦法,除了在客戶端做隨機延遲。(注:這個問題後來和coreos的李響交流,他說etcd3.1會對有解決方案)