
分散式深度學習的兩種叢集管理與排程的實現方式簡介
為什麼需要叢集管理與排程
上文我們簡單介紹了深度學習、分散式CPU+GPU叢集的實現原理,以及分散式深度學習的原理,我們簡單回顧一下:
分散式CPU+GPU叢集的實現:
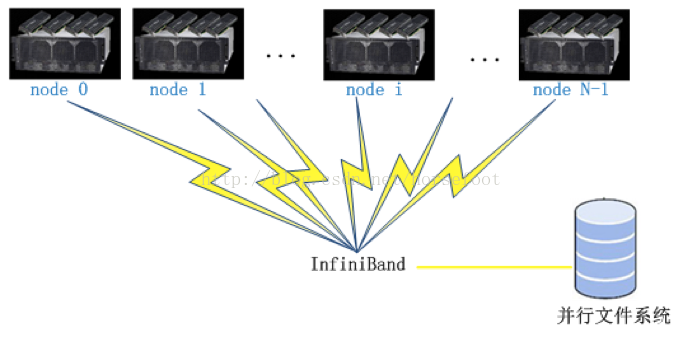
GPU叢集並行模式即為多GPU並行中各種並行模式的擴充套件,如上圖所示。節點間採用InfiniBand通訊,節點間的GPU通過RMDA通訊,節點內多GPU之間採用基於infiniband的通訊。
分佈深度學習框架的實現:
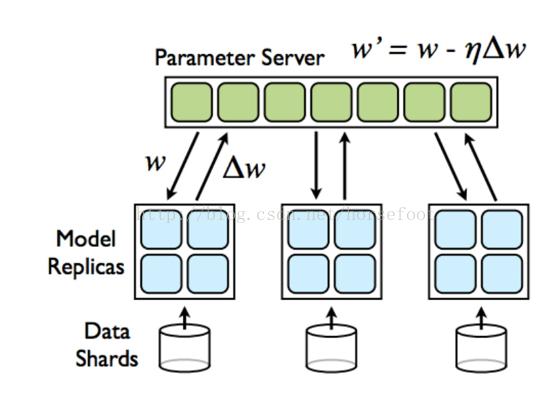
如下圖所示,在tensorflow中,計算節點稱做worker節點,Worker節點主要完成模型的訓練與計算。引數伺服器可以是多臺機器組成的叢集,類似分散式的儲存架構,涉及到資料的同步,一致性等等, 一般是key-value的形式,可以理解為一個分散式的key-value記憶體資料庫,然後再加上一些引數更新的操作,採取這種方式可以幾百億的引數分散到不同的機器上去儲存和更新,解決引數儲存和更新的效能問題。
在分散式深度學習框架執行時,可以將深度學習框架部署到具體的物理叢集,PS伺服器可以挑選如下圖中的node0、node1…,worker節點可以挑選如下圖中的node i,node N-1

叢集的具體配置,引數伺服器可以不用GPU,worker節點因為需要進行模型計算,所在的伺服器需要配置GPU卡。
至此,我們基本搭建了一個深度學習的硬體叢集,同時也將深度學習框架部署到了深度學習的伺服器叢集,但是,整個深度學習叢集(包括軟硬體),可能是公司內部的共享資產,每個專案組都需要使用,那麼,採取上述方式部署便會帶來如下問題:
1. 要求專案組必須使用統一的深度學習框架,統一的深度學習框架的版本,否則不同專案組完成的訓練程式碼有可能不工作,如果每次為了適應某個專案組的要求去重新部署框架,工作量巨大,而且耗時耗力;
2. 其中一個專案組在使用叢集時,其他專案組往往需要等待,導致叢集的資源使用率較低;
3. 伺服器叢集中任何一臺硬體出現問題,都會影響整個叢集的使用。
叢集管理與排程實現的兩種思路
基於Kubernetes平臺
Kubernetes是Google開源的容器叢集管理系統,其提供應用部署、維護、 擴充套件機制等功能,利用Kubernetes能方便地管理跨機器執行容器化的應用,其主要功能如下:
1) 使用Docker對應用程式包裝(package)、例項化(instantiate)、執行(run)。
2) 以叢集的方式執行、管理跨機器的容器。
3) 解決Docker跨機器容器之間的通訊問題。
4) Kubernetes的自我修復機制使得容器叢集總是執行在使用者期望的狀態。
Kubernetes自1.3開始支援GPU,但當時只能最多支援單GPU的排程,自1.6開始,已經支援多GPU的排程,更多關於Kubernetes的與GPU介紹可以參考本系列未來的第3篇:分散式機器學習的兩種叢集方案介紹之基於Kubernetes的實現,這裡不太多贅述。
如果要完成基於Kubernetes的叢集排程管理深度學習框架,需要將深度學習框架執行到容器之中。系統整體架構圖將變為:
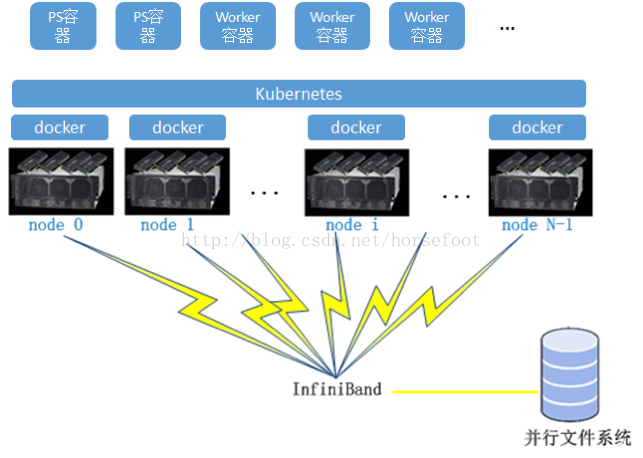
這裡面涉及到一個Kubernetes叢集排程的問題,即Kubernetes如何將ps、worker所在容器所需要的CPU、GPU、記憶體、儲存進行排程,以滿足需求。
叢集經過Kubernetes進行管理以後,分散式深度學習框架執行在容器中,容器通過Kubernetes進行排程以滿足所需的模型訓練資源,因此能夠很好的滿足叢集資源多部門共享的要求。我們看對以下問題的解決。
1. 要求專案組必須使用統一的深度學習框架,並要求統一版本,否則不同專案組完成的訓練程式碼有可能不工作,如果每次為了適應某個專案組的要求去重新部署框架,工作量巨大,而且耗時耗力;
解決:基於容器+ Kubernetes平臺,每個專案組可以很容易的申請自己所需要的深度學習框架,tensorflow、caffe等,同時同一種深度學習框架的多種版本支援也不在話下。
2. 其中一個專案組在使用叢集時,其他專案組往往需要等待,即使叢集的資源使用率較低;
解決:只要叢集有利用率沒達到100%,便可以方便地為其他專案組部署深度學習環境。
3. 伺服器叢集中任何一臺硬體出現問題,都會影響整個叢集的使用;
解決:通過Kubernetes的排程,完成底層硬體的容錯。
天雲軟體基於Kubernetes平臺研發的SkyForm ECP平臺,已經完整的支援了GPU排程,同時也集成了tensorflow,caffe等深度學習框架。
基於MPI並行排程
我們此處引入HPC領域中的MPI叢集作業排程管理解決方案,因為在神經元網路(也包括含更多隱層的深度學習場景下),上一層神經元計算完成以後才能進行下一層神經元網路的計算,這與MPI的計算思路不謀而合。MPI是高效能運算(HPC)應用中廣泛使用的程式設計介面,用於並行化大規模問題的執行,在大多數情況下,需要通過叢集作業排程管理軟體來啟動和監視在叢集主機上執行的MPI任務。此方法的主要目標是使叢集作業排程管理軟體能夠跟蹤和控制組成MPI作業的程序。
一些叢集作業排程管理軟體,如IBM Platform LSF、天雲軟體SkyForm OpenLava等,可以跟蹤MPI任務的CPU、記憶體、GPU的使用。我們把每個深度學習的計算作為MPI作業,通過天雲軟體OpenLava作業排程管理軟體進行叢集統一的資源管理與分配,具體的實現思路如下:
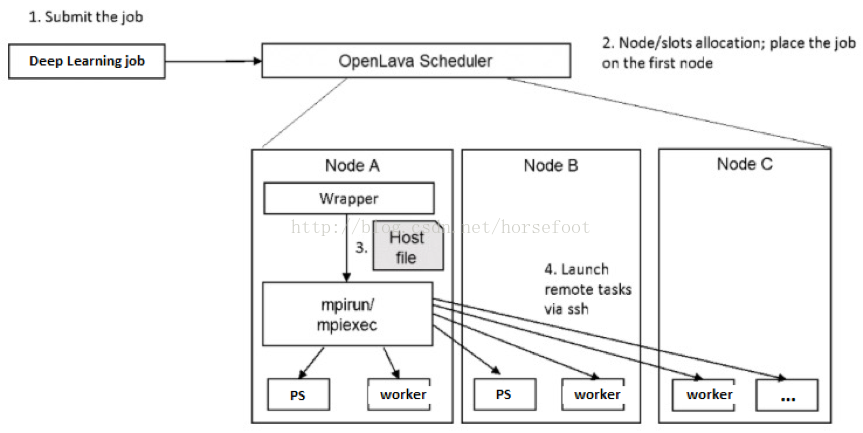
基於叢集作業排程管理的解決方案,也能很好的滿足深度學習叢集多部門共享,多作業併發執行的特性,且能兼顧效率。
其中天雲軟體SkyForm Openlava是一個增強的、基於開源OpenLava併兼容IBM® Spectrum LSFTM的企業級工作負載排程器,並針對半導體研發、深度學習等的工作負載做了設計與優化。不論是現場物理叢集部署,虛擬基礎設施部署,還是雲中部署,客戶都不用支付高昂的許可證費用。具體的openlava介紹,可參考網站openlava.net。
另外,在深度學習框架需要基於MPI方式執行時,往往需要進行重新編譯,並不是所有的版本都支援。