
深度學習基礎--正則化與norm--Ln正則化綜述
L1正則化
L1範數是指向量中各個元素的絕對值之和。

對於人臉任務
原版的人臉畫素是 64*64,顯然偏低,但要提高人臉清晰度,並不能僅靠提高圖片的解析度,還應該在訓練方法和損失函式上下功夫。眾所周知,簡單的 L1Loss 是有數學上的均值性的,會導致模糊。
L2正則化
L2正則化就是權重衰減,是一個手段,是指:
L2正則項(regularization term) * 正則化係數(positive coefficient)
其中,正則項是整個網路的所有權重w的平方的和。正則化係數一般是一個接近0的值(caffe中一般設為0.0005),它一定在(0,1]區間中。
懲罰項,權重衰減
在機器學習或者模式識別中,會出現overfitting,而當網路逐漸overfitting時網路權值逐漸變大,因此,為了避免出現overfitting,會給誤差函式新增一個懲罰項,常用的懲罰項是所有權重的平方乘以一個衰減常量之和。其用來懲罰大的權值。
之所以稱之為權重衰減,是因為它使得權重變⼩。粗看,這樣會導致權重會不斷下降到0。但是實際不是這樣的,因為如果在原始代價函式中造成下降的話其他的項可能會讓權重增加。
L2正則化項有讓w“變小”的效果,但是還沒解釋為什麼w“變小”可以防止overfitting?人們普遍認為:更小的權值w,從某種意義上說,表示網路的複雜度更低,對資料的擬合剛剛好(這個法則也叫做奧卡姆剃刀)。
公式
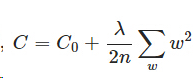


L1與L2正則化的辨析
作用上的差異
L1正則化可以產生稀疏權值矩陣,即產生一個稀疏模型,因此可以用於特徵選擇,懲罰⼤的權重,傾向於讓⽹絡優先選擇⼩的權重。
L2正則化可以防止模型過擬合(overfitting)。
L1正則化的稀疏化的好處
1)特徵選擇實現特徵的自動選擇,去除無用特徵。稀疏化可以去掉這些無用特徵,將特徵對應的權重置為零。
2)可解釋性(interpretability)如判斷某種病的患病率時,最初有1000個特徵,建模後引數經過稀疏化,最終只有5個特徵的引數是非零的,那麼就可以說影響患病率的主要就是這5個特徵。
公式上的差異
L1正規化說白了就是平均值的和;L2正規化就是平方和。
L1正則化是指權值向量w中各個元素的絕對值之和,通常表示為||w||1 。一般還要乘以λ/n(n是訓練集的樣本大小;λ是正則項係數)。
L2正則化是指權值向量w中各個元素的平方和然後再求平方根,用在迴歸模型中也稱為嶺迴歸(Ridge regression),有人也叫它“權值衰減weight decay”。一般還要乘以λ/n(n是訓練集的樣本大小;λ是正則項係數)。
L0與L1正則化的辨析
L0範數是指向量中非零元素的個數。如果用L0規則化一個引數矩陣W,就是希望W中大部分元素是零,實現稀疏。
L1範數是指向量中各個元素的絕對值之和,也叫”係數規則運算元(Lasso regularization)"。L1範數也可以實現稀疏,通過將無用特徵對應的引數W置為零實現。
L0和L1都可以實現稀疏化,不過一般選用L1而不用L0,原因包括:
1)L0範數很難優化求解(NP難);
2)L1是L0的最優凸近似,比L0更容易優化求解(這一段解釋過於數學化,姑且當做結論記住)。