
深度神經網路結構以及Pre-Training的理解
Logistic迴歸、傳統多層神經網路
1.1 線性迴歸、線性神經網路、Logistic/Softmax迴歸
線性迴歸是用於資料擬合的常規手段,其任務是優化目標函式:h(θ)=θ+θ1x1+θ2x2+....θnxn
線性迴歸的求解法通常為兩種:
①解優化多元一次方程(矩陣)的傳統方法,在數值分析裡通常被稱作”最小二乘法",公式θ=(XTX)−1XTY
②迭代法:有一階導數(梯度下降)優化法、二階導數(牛頓法)。
方程解法侷限性較大,通常只用來線性資料擬合。而迭代法直接催生了用於模式識別的神經網路誕生。
最先提出Rosenblatt的感知器,借用了生物神經元的輸入-啟用-傳遞輸出-接受反饋-矯正神經元的模式,將數學迭代法抽象化。
並且線上性迴歸輸出的基礎上,添加了輸出校正,通常為階躍函式,將回歸的數值按正負劃分。
為了計算簡單,此時梯度下降優化法被廣泛採用,梯度優化具有計算廉價,但是收斂慢的特點(一次收斂,而牛頓法是二次收斂)。
為了應對精確的分類問題,基於判別概率模型P(Y|X)被提出,階躍輸出被替換成了廣義的概率生成函式Logistic/Softmax函式,從而能平滑生成判別概率。
這三個模型,源於一家,本質都是對輸入資料進行線性擬合/判別,當然最重要的是,它們的目標函式是多元一次函式,是凸函式。
1.2 雙層經典BP神經網路
由Hinton提出多層感知器結構、以及Back-Propagation訓練演算法,在80年代~90年代鼎盛一時。
經過近20年,即便是今天,也被我國各領域的CS本科生、研究生,其他領域(如機械自動化)學者拿來嚇唬人。
至於為什麼是2層,因為3層效果提升不大,4層還不如2層,5層就太差了。[Erhan09]
這是讓人大跌眼鏡的結果,神經網路,多麼高大上的詞,居然就兩層,這和生物神經網路不是差遠了?
所以在90年代後,基於BP演算法的MLP結構被機器學習界遺棄。一些新寵,如決策樹/Boosing系、SVM、RNN、LSTM成為研究重點。
1.3 多層神經網路致命問題:非凸優化
這個問題得從線性迴歸一族的初始化Weight說起。線性家族中,W的初始化通常被置為0。
如果你曾經寫過MLP的話,應該犯過這麼一個錯誤,將隱層的初始化設為0。
然後,這個網路連基本的異或門函式[參考]都難以模擬。先來看看,線性迴歸和多層神經網路的目標函式曲面差別。
線性迴歸,本質是一個多元一次函式的優化問題,設f(x,y)=x+y
多層神經網路(層數K=2),本質是一個多元K次函式優化問題,設f(x,y)=xy


線上性迴歸當中,從任意一個點出發搜尋,最終必然是下降到全域性最小值附近的。所以置0也無妨。
而在多層神經網路中,從不同點出發,可能最終困在(stuck)這個點所在的最近的吸引盆(basin of attraction)。[Erhan09, Sec 4.2]
吸引盆一詞非常蹩腳,根據百度的解釋:它像一個匯水盆地一樣,把處於山坡上的雨水都集中起來,使之流向盆底。
其實就是右圖凹陷的地方,使用梯度下降法,會不自覺的被周圍最近的吸引盆拉近去,達到區域性最小值。此時一階導數為0。從此訓練停滯。
區域性最小值是神經網路結構帶來的揮之不去的陰影,隨著隱層層數的增加,非凸的目標函式越來越複雜,區域性最小值點成倍增長。[Erhan09, Sec 4.1]
因而,如何避免一開始就吸到一個倒黴的超淺的盆中呢,答案是權值初始化。為了統一初始化方案,通常將輸入縮放到[−1,1]
經驗規則給出,W∼Uniform(−1LayerOut√,1LayerOut√),Uniform為均勻分佈。
Bengio的學生Xavier在2010年推出了一個更合適的範圍,能夠使得隱層Sigmoid系函式獲得最好的啟用範圍。[Glorot10]
對於Log-Sigmoid: [−4∗6√LayerInput+LayerOut√,4∗6√LayerInput+LayerOut√]
對於Tanh-Sigmoid: [6√LayerInput+LayerOut√,6√LayerInput+LayerOut√]
這也是為什麼多層神經網路的初始化隱層不能簡單置0的原因,因為0很容易陷進一個非常淺的吸引盆,意味著區域性最小值非常大。
糟糕的是,隨機均勻分佈儘管獲得了一個稍微好的搜尋起點,但是卻又更高概率陷入到一個稍小的區域性最小值中。[Erhan10, Sec 3]
所以,從本質上來看,深度結構帶來的非凸優化仍然不能解決,這限制著深度結構的發展。
1.4 多層神經網路致命問題:Gradient Vanish
這個問題實際上是由啟用函式不當引起的,多層使用Sigmoid系函式,會使得誤差從輸出層開始呈指數衰減。見[ReLu啟用函式]
因而,最滑稽的一個問題就是,靠近輸出層的隱層訓練的比較好,而靠近輸入層的隱層幾乎不能訓練。
以5層結構為例,大概僅有第5層輸出層,第4層,第3層被訓練的比較好。誤差傳到第1、2層的時候,幾乎為0。
這時候5層相當於3層,前兩層完全在打醬油。當然,如果是這樣,還是比較樂觀的。
但是,神經網路的正向傳播是從1、2層開始的,這意味著,必須得經過還是一片混亂的1、2層。(隨機初始化,亂七八糟)
這樣,無論你後面3層怎麼訓練,都會被前面兩層給搞亂,導致整個網路完全退化,真是連雞肋都不如。
幸運的是,這個問題已經被Hinton在2006年提出的逐層貪心預訓練權值矩陣變向減輕,最近提出的ReLu則從根本上提出瞭解決方案。
2012年,Hinton的學生Alex Krizhevsky率先將受到Gradient Vanish影響較小的CNN中大規模使用新提出的ReLu函式。
2014年,Google研究員賈揚清則利用ReLu這個神器,成功將CNN擴充套件到了22層巨型深度網路,見知乎。
對於深受Gradient Vanish困擾的RNN,其變種LSTM也克服了這個問題。
1.5 多層神經網路致命問題:過擬合
他說:最近有人表示,他們用傳統的深度神經網路把訓練error降到了0,也沒有用你的那個什麼破Pre-Training嘛!
然後Bengio自己試了一下,發現確實可以,但是是建立在把接近輸出層的頂隱層神經元個數設的很大的情況下。
於是他把頂隱層神經元個數限到了20,然後這個模型立馬露出馬腳了。
無論是訓練誤差、還是測試誤差,都比相同配置下的Pre-Training方法差許多。
也就是說,頂層神經元在對輸入資料直接點對點記憶,而不是提取出有效特徵後再記憶。
這就是神經網路的最後一個致命問題:過擬合,龐大的結構和引數使得,儘管訓練error降的很低,但是test error卻高的離譜。
過擬合還可以和Gradient Vanish、區域性最小值混合三打,具體玩法是這樣的:
由於Gradient Vanish,導致深度結構的較低層幾乎無法訓練,而較高層卻非常容易訓練。
較低層由於無法訓練,很容易把原始輸入資訊,沒有經過任何非線性變換,或者錯誤變換推到高層去,使得高層解離特徵壓力太大。
如果特徵無法解離,強制性的誤差監督訓練就會使得模型對輸入資料直接做擬合。
其結果就是,A Good Optimation But a Poor Generalization,這也是SVM、決策樹等淺層結構的毛病。
Bengio指出,這些利用區域性資料做優化的淺層結構基於先驗知識(Prior): Smoothness
即,給定樣本(xi,yi),儘可能從數值上做優化,使得訓練出來的模型,對於近似的x,輸出近似的y。
然而一旦輸入值做了泛型遷移,比如兩種不同的鳥,鳥的顏色有別,且在影象中的比例不一,那麼SVM、決策樹幾乎毫無用處。
因為,對輸入資料簡單地做數值化學習,而不是解離出特徵,對於高維資料(如影象、聲音、文字),是毫無意義的。
然後就是最後的事了,由於低層學不動,高層在亂學,所以很快就掉進了吸引盆中,完成神經網路三殺。
特徵學習與Pre-Training
2.1 Local Represention VS Distrubuted Represention
經典的使用Local Represention演算法有:
①在文字中常用的:One-Hot Represention,這種特徵表達方式只是記錄的特徵存在過,
而不能體現特徵之間的關聯( 比如從語義、語法、關聯性上)。且特徵表示過於稀疏,帶來維數災難。
②高斯核函式:看起來要高明一些,它將輸入懸浮在核中心,按照距離遠近來決定哪些是重要的,哪些是不重要的。
將特徵轉化成了連續的數值,避免了表達特徵需要的維數過高。但是正如KNN一樣,片面只考慮重要的,忽視不重要的,
會導致較差的歸納能力,而對於高度特徵稠密的資料(如影象、聲音、文字),則可能都無法學習。
③簇聚類演算法:將輸入樣本劃分空間,片面提取了區域性空間特徵,導致較差的歸納能力。
④決策樹系:同樣的將輸入樣本劃分空間問題。
以上,基本概括了資料探勘十大演算法中核心角色,這說明,資料探勘演算法基本不具備挖掘深度資訊的能力。
相比之下,處理經過人腦加工過的統計資料,則更加得心應手。
因而,模式識別與資料探勘的偏重各有不同,儘管都屬於機器學習的子類。
為了提取出輸入樣本模式中的泛型關聯特徵,一些非監督學習演算法在模式識別中被廣泛使用,如PCA、ICA。
PCA的本質是:[Input]=>(Decompose)[Output]∗[LinearBase]。
即線性分解出特徵向量,使得輸入->輸出之間做了一層線性變換,有用的關聯特徵資訊被保留,相當於做了一個特徵提取器。
分解出來的特徵稱之為Distrubuted Represention,NLP中詞向量模型同樣屬於這類特徵。
而RBM、AutoEncoder的本質是:[Input]=>(Decompose)[Output]∗[Non−LinearBase]。
顯而易見,非線性變換要比線性變換要強大。
2.2 判別模型與生成模型
這是個經典問題,非監督學習的生成模型P(X)和監督學習的判別模型P(Y|X)之間的關係,到底是親兄弟,還是世仇呢?
這個問題目前沒有人能給出數學上解釋,但是從生物學上來講,肯定是關係很大的。
儘管CNN目前取得了很大的成功,但是也帶來的很大憂慮,[知乎專欄]的評論區,看到有人這麼評論:
Ng說,你教一個小孩子認一個蘋果,是不會拿幾百萬張蘋果的圖給他學的。
如果兩者之間沒有關係,那麼P(X)初始化得出的引數,會被之後P(Y|X)改的一團糟,反之,則只是被P(Y|X)進行小修小改。
Hinton在DBN(深信度網路)中,則是利用此假設,提出了逐層貪心初始化的方法,進行實驗:
①Stage 1:先逐層用RBM使得引數學習到有效從輸入中提取資訊。進行生成模型P(X)。(Pre-Training)。
②Stage 2: 利用生成模型得到的引數作為搜尋起點,進行判別模型P(Y|X)。(Fine-Tuning)。
[Erhan10 Sec6.4]將Stage1、Stage2、純監督學習三種模型訓練到完美之後的引數視覺化之後,是這個樣子:

可以看到,由於Gradient Vanish影響,較高層比較低層有更大的變動。
但是從整體上,Fine-Tuning沒有太大改變Pre-Training的基礎,也就是說P(Y|X)的搜尋空間是可以在P(X)上繼承的。
2.3 殊途同歸的搜尋空間
神經網路的目標函式到底有多複雜,很難去描述,大家只知道它是超級非凸的,超級難優化。
但是,帶來的一個好處就是,搜尋到終點時,可能有幾百萬個出發起點,幾百萬條搜尋路徑,路徑上的權值有幾百萬種組合。
[Erhan09 Sec4.6]給出了基於Pre-Training和非Pre-Training的各400組隨機初始化W,搜尋輸出降維後的圖示,他指出:
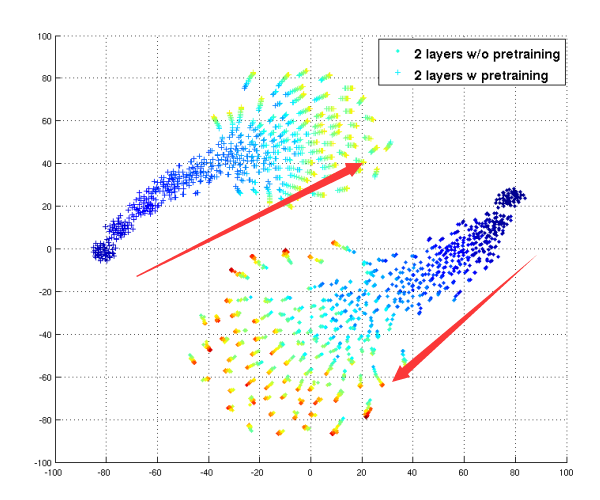
①Pre-Training和非Pre-Training的模型引數,在搜尋空間中,從不同點出發,最後停在了不同的搜尋空間位置。
②散開的原因,是由於陷入的吸引盆的區域性最小值中,明顯不做Pre-Training,散開的範圍更廣,說明非常危險。
可以看到,儘管兩種模型取得了近似的train error和test error,但是搜尋空間是完全不同的,引數形成也不同的。
從圖論的網路流角度,多層神經網路,構成了一個複雜的有向無環流模型:

原本最大流模型下,每個結點的流量就有不同解。但是神經網路的要求的流是近似流,也就是說,近似+不同衍生出更多不同的解。
2.4 特殊的特徵學習模型——卷積神經網路
CNN經過20年發展,已經是家喻戶曉了,即便你不懂它的原理,你一樣可以用強大的Caffe框架做一些奇怪的事情。
Bengio指出,CNN是一種特殊的神經網路,引數少,容易層疊出深度結構。
最重要的是,它根據label,就能有效提取出稀疏特徵,將其卷積核可視化之後,居然達到了近似生成模型的效果,確實可怕。


(CNN第一層卷積核視覺化 by AlexNet) (DBN第二層視覺化)
上面是對自然圖片的學習結果,Hinton指出,自然圖片的引數視覺化後,應該近似Gabor特徵。
CNN的強大,歸結起來有四大創新點:
①塊狀神經元區域性連線:CNN的神經元比較特殊,它是一個2D的特徵圖,這意味著每個畫素點之間是沒有連線的。
全連線的只是特徵圖,特徵圖是很少的。由於這種特殊的連線方式,使得每個神經元連線著少量上一層經過啟用函式的神經元。
減輕了Gradient Vanish問題。使得早期CNN在非ReLU啟用情況下,就能構建不退化的深度結構。

其中,降取樣層、區域性響應歸一化層則為非全連線的"虛層",也就是說,真正構成壓力的只有卷積層。
②引數權值共享: 直觀上理解是一個小型卷積核(如5x5)在30x30的圖上掃描,30x30畫素用的都是5x5引數。
實際原因是1D連線變成了2D連線,原來的點對點引數現在變成了塊對塊引數,且卷積核塊較小。更加容易提取出魯棒性特徵。
當然,區域性最小值問題也被減輕,因為引數量的減少,使得目標函式較為簡單。
③卷積計算:對比原來的直接點對點乘,卷積方法能快速響應輸入中的關鍵部分。
④降取樣計算:添加了部分平移縮放不變性。
Alex Krizhevsky在[Krizhevsky12]對傳統CNN提出的幾點改進,使得CNN結構變得更加強大:
①將Sigmoid系啟用函式全部換成ReLu,這意味著多了稀疏性,以及超深度結構成為可能(如GoogleNet)
②新增區域性響應歸一化層,在計算神經學上被稱作神經元的側抑制,根據賈揚清說法,暫時似乎沒發現有什麼大作用。[知乎]
Caffe中之所以保留著,是為了尊敬長輩遺留的寶貴成果。
③弱化FC層神經元數:ReLu使得特徵更加稀疏,稀疏特徵具有更好的線性可分性,這意味著FC層的多餘。[Xavier11]
實際上,GoogleNet中就已經移除了FC層,根據賈揚清大牛的說法:[知乎]
因為全連線層(Fully Connected)幾乎佔據了CNN大概90%的引數,但是同時又可能帶來過擬合(overfitting)的效果。
這意味著,CNN配SVM完全成為雞肋的存在,因為FC層+Softmax≈SVM
④為卷積層新增Padding,使得做了完全卷積,又保證維度不會變大。
⑤使用重疊降取樣層,並且在重疊降取樣層,用Avg Pooling替換Max Pooling(第一仍然是Max Pooling)獲得了5%+的精度支援。
⑥使用了Hinton提出的DropOut方法訓練,減輕了深度結構帶來的過擬合問題。
2.5 Pre-Training
Pre-Training的理論基石是生成模型P(X)。
Hinton提出了對比重構的方法,使得引數W可以通過重構,實現argmaxW∏v?VP(v)
生成模型的好處在於,可以自適應從輸入中獲取資訊,儘管可能大部分都是我們不想要的。
這項專長,可以用來彌補某些模型很難提取特徵的不足,比如滿城盡是FC的傳統全連線神經網路。
FC神經網路最大的缺陷在於很難提取到有用的特徵,這點上最直觀的反應就是 A Good Optimation But a Poor Generalization。
最近刷微博看到有人貼1993年的老古董[論文],大概內容就是:
證明神經網路只需1個隱藏層和n個隱藏節點,即能把任意光滑函式擬合到1/n的精度。
然而並沒有什麼卵用,這是人工智慧,不是數學函式模擬。你把訓練函式擬合的再好,歸納能力如此之差,仍然會被小朋友鄙視的。
為了證明FC網路和CNN的歸納能力之差,我用了Cifar10資料集做了測試,兩個模型都沒有加L1/L2。
FC網路:來自[Xavier11]提出了ReLU改進FC網路,預訓練:正向ReLU,反向Softplus,資料縮放至[0,1]
網路[1000,1000,1000],lr三層都是0.01,pre-lr:0.005,0.005,0.0005。
CNN:來自Caffe提供的Cifar10快速訓練
Logistic迴歸、傳統多層神經網路
1.1 線性迴歸、線性神經網路、Logistic/Softmax迴歸
線性迴歸是用於資料擬合的常規手段,其任務是優化目標函式:h(θ)=θ+θ1x1+θ2x2+....θnxn
線性迴歸的求解法通常為兩種:
①解優化多元一次方程(矩陣)的傳統方法,在數值分析裡通常被稱
數據輸入→卷積層→修正線性單元→池化層→全連接層data_batch→tf.nn.conv2d→tf.nn.relu→tf.nn.max.pool→tf.matmul(x,W)+b
資料輸入 \to 卷 在這篇文章中,我們將回顧監督機器學習的基礎知識,以及訓練和驗證階段包括哪些內容。
在這裡,我們將為不瞭解AI的讀者介紹機器學習(ML)的基礎知識,並且我們將描述在監督機器學習模型中的訓練和驗證步驟。
ML是AI的一個分支,它試圖通過歸納一組示例而不是接收顯式指令來讓機器找出如何執行任務。ML有三種正規化:監督
https://blog.csdn.net/tiandijun/article/details/25192155
近這兩年裡deep learning技術在影象識別和跟蹤等方面有很大的突破,是一大研究熱點,裡面涉及的數學理論和應用技術很值得深入研究,這系列部落格總結了
前言
\quad
\qu sklearn實戰-乳腺癌細胞資料探勘(部落格主親自錄製視訊教程,QQ:231469242)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm
論文:何愷明《Rethinking ImageNet Pre-training》
在許多計算機視覺任務中,包括目標檢測、影象分割、行為檢測等,一般使用在ImageNet上預訓練再進行微調。而在這篇論文中,作者任務在ImageNet上預訓練是並不必要的,隨機初始化也可以達到同樣的效果,只需要:
技術交流qq群: 659201069
本系列埔文由淺入深介紹神經網路相關知識,然後深入神經網路核心原理與技術,最後淺出python神經網路程式設計實戰。通過本系列博文,您將徹底理解神經網路的原理以及如何通過python開發可用於生產環境的程式。本博
為了儘量能形成系統的體系,作為最基本的入門的知識,請參考一下之前的兩篇部落格:
神經網路(一):概念
神經網路(二):感知機
上面的兩篇部落格讓你形成對於神經網路最感性的理解。有些看不懂的直接忽略就行,最基本的符號的記法應該要會。後面會用到一這兩篇部落格中
總結一下昨天的學習過程
(注:這幾天老不在狀態,貌似進入了學習激情的瓶頸期,動力以及平靜心嚴重失控,Python3.X與Python2.X之間的程式碼除錯,尤其是環境配置搞得頭昏腦脹)
昨天瞭解接觸的內容
CNN卷積神經網路的基本原理以及在CPU中測試以及程式碼除錯(又是失
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。
技術交流QQ群:433250724,歡迎對演算法、機器學習技術感興趣的同學加入。
今天具體介紹一個Google DeepMind在15年提出的Spatial T
神經網路技術起源於上世紀五、六十年代,當時叫感知機(perceptron),擁有輸入層、輸出層和一個隱含層。輸入的特徵向量通過隱含層變換達到輸出層,在輸出層得到分類結果。早期感知機的推動者是Rosenblatt。(扯一個不相關的:由於計算技術的落後,當時感知
本系列由斯坦福大學CS231n課後作業提供
CS231N - Assignment2 - Q4 - ConvNet on CIFAR-10
問題描述:使用IPython Notebook(現版本為jupyter notebook,如果安裝anaconda完整版
人工神經網路是早期機器學習中的一種重要演算法,經歷了數十年的起伏。神經網路的原理受到我們大腦生理結構神經元——的啟發。但與大腦中可以在一定距離內連線的任何神經元不同,人工神經網路具有、連線和資料傳播方向的離散層。
例如,我們可以將影象分割成影象塊並將它們輸入到神經網路的
授人以魚不如授人以漁,紅鯉魚家有頭小綠驢叫驢屢屢。至於修改網路結構多虧了課題組大師姐老龐,在小米實習回校修整,我問她怎麼修改網路,她說改網路就是改協議,哎呀,一語驚醒夢中人啊!老龐師姐,你真美!雖然博主之前也想過修改網路協議試一試,鑑於一直不懂網路結構中的各個引 版本 打印 就會 需要 引擎 腳本 html標簽 同時 命名 web標準簡單來說可以分為結構、表現和行為。其中結構主要是有HTML標簽組成。表現即指css樣式表,通過css可以是頁面的結構標簽更具美感。行為是指頁面和用戶具有一定的交互,同時頁面結構或者表現發生變化,主要 ron 提高 搜索引擎 class 編程 簡單 命名 組織 事情 網頁主要由三個部分組成,表現、結構和行為。
我理解的就是:
html是名詞--表現
css是形容詞--結構
javascript是動詞--行為
以上這三個東西就形成了一個完整的網頁,但是js改變時,可以會 出了 htm 表現 一定的 css 編程 用戶體驗 組成 命名 web標準簡單來說可以分為結構、表現和行為。其中結構主要是有HTML標簽組成。或許通俗點說,在頁面body裏面我們寫入的標簽都是為了頁面的結構。表現即指css樣式表,通過css可以是頁面的結構標簽更具美感。行為 實現簡單 att 信息點 option sel done edi image ogg 前兩天做了一個有關表單增刪改查的例子,現在貼出來。主要是想好好說一下this。
下面貼一張我要做的表格效果。
就是實現簡單的一個增刪改查。
1、點擊增加後自動增加一行;
2、點擊保存 無法 頁面 自己 relative n) 布局 posit 如果 絕對定位 高度塌陷的含義:
父元素的高度,默認被子元素撐開,目前來講box2多高,box1就多高。此時如果子元素設置浮動,則會導致其完全脫離文檔流,子元素脫離文檔流將無法撐開父元素, 導致父元素的高度丟失, 相關推薦
深度神經網路結構以及Pre-Training的理解
tensorflow隨筆-簡單CNN(卷積深度神經網路結構)
C#中的深度學習(三):理解神經網路結構
深度學習資料整理(深度神經網路理解)
【深度學習】python實現簡單神經網路以及手寫數字識別案例
神經網路6_CNN(卷積神經網路)、RNN(迴圈神經網路)、DNN(深度神經網路)概念區分理解
《Rethinking ImageNet Pre-training》理解
神經網路一之神經網路結構與原理以及python實戰
深度學習筆記二:多層感知機(MLP)與神經網路結構
深度學習進階(五)--卷積神經網路與深度置信網路以及自動編碼初識(補昨天部落格更新)
深度學習方法(十二):卷積神經網路結構變化——Spatial Transformer Networks
CNN(卷積神經網路)、RNN(迴圈神經網路)、DNN(深度神經網路)的內部網路結構的區別
【深度學習】卷積神經網路的實現與理解
記錄一下最近學的神經網路以及深度學習
深度學習Caffe實戰筆記(7)Caffe平臺下,如何調整卷積神經網路結構
WEB標準以及W3C的理解和認識
對WEB標準以及W3C的理解與認識
對WEB標準以及W3C的理解與認識?
javascript相關的增刪改查以及this的理解
html高度塌陷以及定位的理解