
Spark核心資料模型RDD及操作
如今spark特別火,相信作為程式設計師的你也難以抵擋spark的魅力,俗話說萬事開頭難,學習spark需要一些準備工作,首先就是要搭建學習測試環境,spark非常人性化,一個簡單的測試環境,只需要下載安裝包,解壓之後,執行spark_shell指令碼就可以學習測試了,spark測試的經典頁面如下圖:
這樣就以本地模式啟動了spark,可以進行學習了。如果有條件,可以搭建一個叢集,建議用docker來搭建,方便省時間。閒話就不多說了,直接進入主題。
RDD特徵
想要入門spark,最重要的就是理解RDD的概念,RDD叫做彈性分散式資料集,是spark中核心的資料模型,spark的所有操作都是圍繞RDD進行的。RDD有兩個關鍵特點:
1)資料被分割槽
因為在大資料處理場景中,一份資料的一般很大,為了能夠平行計算,需要把資料分割槽儲存,就是把資料分散儲存在多個節點上,RDD會儲存資料分割槽資訊,以便處理資料,每個RDD有個方法partitions,可以獲取分割槽資訊。在shell中,我載入本地一個檔案val RDD = sc.textFile("file:///Users/test/Documents/test"),如下圖所示會看到該檔案載入到spark中有兩個分割槽。意思這份資料被分成兩個分割槽,來做平行計算。

2)RDD依賴性:
spark中主要處理過程是RDD的轉化過程,怎麼理解依賴性,假如RDD1通過某種計算(map,groupByKey)轉換為RDD2,那麼就認為RDD2依賴RDD1,在spark中依賴關係分為兩種,一種是窄依賴,一種是寬依賴也叫shuffle 依賴。債依賴是一個子RDD只能有一個父RDD,寬依賴是一個子RDD有多個父RDD,我用圖說明依賴關係。
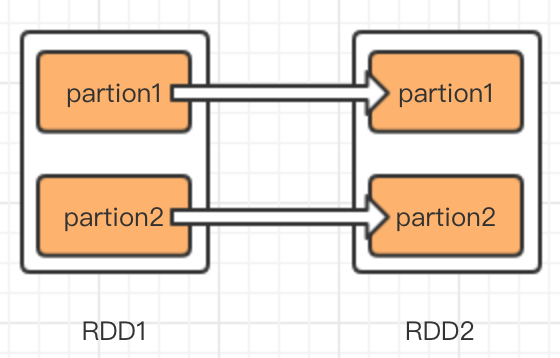
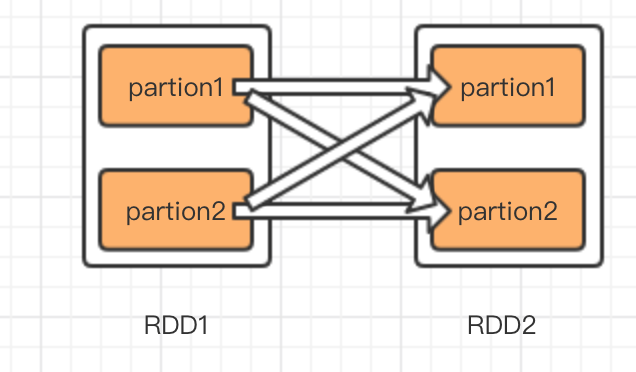
左圖是窄依賴,右圖是寬依賴,比如map就是一種窄依賴,特點是RDD轉換分割槽之間互不影響,即使有一個轉換失敗了,也不影響其他轉換,只需要恢復故障轉換過程即可。而groupByKey就是一種寬依賴,如圖右圖,RDD2的partition1的生成,需要RDD1的partition1和partition2同時貢獻資料,如果其中有哪一步partion轉換失敗了,那麼整個轉換過程需要重新執行。另外一點區別是,窄依賴的轉換可以在叢集的一個節點中完成,免去IO開銷,而寬依賴的資料,來自所有的父partition,這就可能產生大量IO,所以寬依賴比窄依賴更加耗費資源。我在shell中執行val RDD1 = RDD.map(x=>x.split(",")),然後看RDD1的依賴屬性,如下圖依賴型別為OneToOneDependency,字面意思為1對1依賴。

而我在shell中執行,val RDD2 = RDD.flatMap(x=>x.split(",")).map(x=>(x,1)).groupByKey() ,這時再看RDD2的依賴屬性,如下圖:

可以看到,RDD2的依賴屬性是ShuffleDependency,指寬依賴,因為GroupByKey需要依賴於父RDD的所有分割槽。
RDD轉換和動作
在清楚的RDD的特徵之後,RDD的轉換和動作也就相對於好理解了,轉換即RDD到RDD之間的計算過程,比如map,flatMap等等,轉換的特點是執行轉換的程式碼,並不立刻進行轉換,一直到最後一步動作發生的時候,才會真正執行轉換。動作(Aciton),就是獲取最後的結果,就想一條指令一樣,發射出去,引發整個過程的運轉。比如irst(),take(),collect(),這些都是動作。一旦這些動作執行之後,才會引發真個過程的發生。沒什麼好講的,在明白了spark中,最核心的資料模型RDD之後,那麼圍繞RDD可以立刻寫出一個helloworld,單詞計數。
第一步:載入資料,生成第一份RDD。
val wordLine = sc.textFile("file:///Users/test/README.md");
檢視分割槽數:wordLine.partitions.length =2
第二步:生成窄依賴words,進行map轉換
val words = wordLine.flatMap(x => x.split());
檢視分割槽數:words.partitions.length=2 證明是一對一轉換,資料變化為單片語成的資料
第三步:生成窄依賴wordsTuple,增加每個單詞的計數,
val wordTuple = words.map(x => (x,1));
檢視分割槽數:wordTyple.partitions.length=2證明是一對一轉換,資料變化為(單詞,數量)組成的資料,但這個資料還沒有做累加
第四步:生成寬依賴wordCounts,累加每個元組
val wordCounts = wordTuple.reduceByKey((x,y)=>x+y)
第五步:發生動作(action),儲存檔案
wordCount.saveAsTextFile("file:///test/result");
檢視儲存的檔案內容:
part-00000 和 part-00001是兩個分割槽的資料,儲存成的檔案。可以用命令儲存成一個,預設情況是結果有多少分割槽就儲存多少個。
檔案內容如下:
結果,只用空格做了分詞,還可以有許多其他分隔符,具體情況具體看吧,只是做了簡單一個helloworld。
瞭解了RDD之後,很多操作和原理就更好懂一點,由於時間原因就不多說了,大家晚安。