
使用tesseract進行中文文字識別
阿新 • • 發佈:2019-02-05
簡介
本文主要介紹如何通過tesseract進行文字識別,及其識別效果。效果圖
| 圖片 | |
|---|---|
| 測試圖 |  |
| 測試結果 | 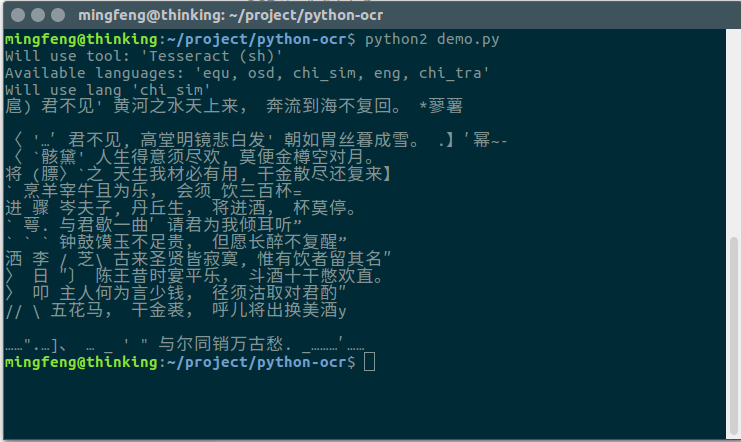 |
環境
- ubuntu
- python2.7
安裝
- tesseract
sudo apt-get install tesseract-ocr
- 安裝tesseract tessdata
https://github.com/tesseract-ocr/tessdata 下載對應語言文字學習資料,並儲存到
/usr/share/tesseract-ocr/tessdata或/usr/share/tessdata位置 pyocr
sudo pip install pyocr
測試程式碼
- demo.py
from PIL import Image import sys import pyocr import pyocr.builders import sys tools = pyocr.get_available_tools() if len(tools) == 0: print("Not found OCR tool") sys.exit(1) tool = tools[0] print("Will use tool: '%s'" % (tool.get_name())) langs = tool.get_available_languages() print("Available languages: '%s'" % ", ".join(langs)) print("Will use lang '%s'" % ("chi_sim")) txt = tool.image_to_string( Image.open('images/jjj.jpg'), lang='chi_sim', builder=pyocr.builders.TextBuilder(tesseract_layout=6) ) print(txt)
執行
python2 demo.py
評價
文字識別的精度有待提升。一些畫素低的,如標點符號都不能很好的解析出來。有興趣的同學可以深入研究一下。
本文涉及程式碼
https://github.com/cangyan/python-ocr參考連結
https://qiita.com/it__ssei/items/fd804dcb10997566593b檢視原文:https://www.huuinn.com/archives/410
更多技術乾貨:風勻坊
關注公眾號:風勻坊