最近看到的spark資料整理
spark的特點:相比於mapreduce,spark是基於記憶體的,在分散式環境下,spark將作為轉化為有向無環圖DAG,並分階段進行DAG的排程和任務的分散式並行處理。所以spark也支援記憶體資料共享,所以spark比hadoop快。spark的執行圖如下:
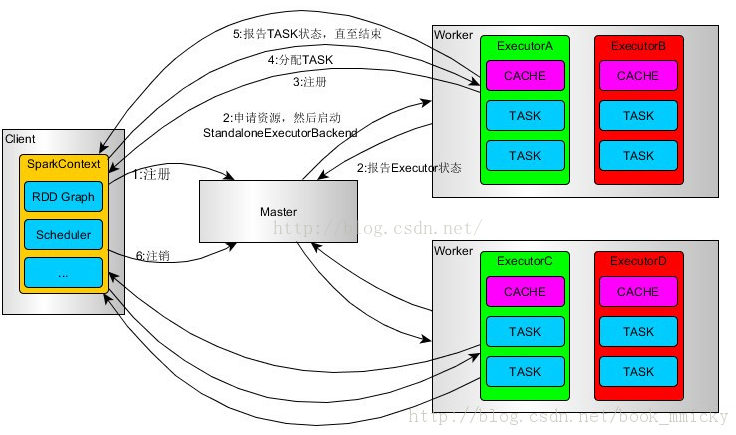
在spark執行過程中,driver和worker是重要角色。Driver是應用邏輯的起點,負責作業的排程,即task任務的分發,多個worker負責管理計算節點和建立executor並行執行任務;在執行階段,driver會將task和task依賴的jar序列化後傳輸給work機器。
下面介紹spark架構的基本元件:
● ClusterManager: 在standalone模式中為master,控制整個叢集,監控worker。在yarn中為ResourceManager。
● worker: 從節點,負責控制計算資源,啟動exector或driver,在yarn中為nodemanager,負責計算節點的控制
● driver:執行application的main() 函式並建立sparkcontext
● executor: 執行器,在workder 執行任務的元件,用於啟動執行緒池執行任務。每個application擁有獨立的一組executor。
● sparkcontext: 整個應用的上下文,控制應用的生命週期。
● RDD: SPARK的基本計算單元,一組RDD可形成執行的有向無環圖RDD Graph。
● DAG Scheduler: 根據作業(job) 構建基於Stage的DAG, 並把Stage提交給TaskScheduler.
● TaskScheduler: 將任務(Task)分發給executor執行.
● MapOutPutTracker: 負責shuffle元資訊的儲存.
● BroadcaseManager: 負責廣播變數的控制與元資訊的儲存.
● BlockManager: 負責儲存管理·建立和查詢塊
● MetricsSystem: 監控執行時效能指標資訊.
● SparkConf: 負責儲存配置資訊.
● spark整體流程: client 提交應用,master找到一個worker啟動driver,driver向master或資源管理器申請資源,之後將application轉換為RDD graph,再由DagSchudeler將RDD graph轉換為stage的有向無環圖提交給taskschedule,由taskscheduler提交任務給executor執行.
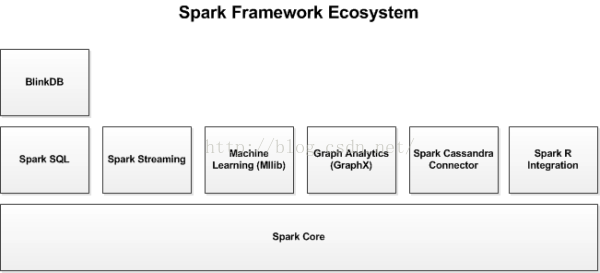
spark還包含許多有用的庫,常見的spark庫有:
Spark Streaming:
Spark Streaming基於微批量方式的計算和處理,可以用於處理實時的流資料。它使用DStream,簡單來說就是一個彈性分散式資料集(RDD)系列,處理實時資料。
Spark SQL:
Spark SQL可以通過JDBC API將Spark資料集暴露出去,而且還可以用傳統的BI和視覺化工具在Spark資料上執行類似SQL的查詢。使用者還可以用Spark SQL對不同格式的資料(如JSON,Parquet以及資料庫等)執行ETL,將其轉化,然後暴露給特定的查詢。
Spark MLlib:
MLlib是一個可擴充套件的Spark機器學習庫,由通用的學習演算法和工具組成,包括二元分類、線性迴歸、聚類、協同過濾、梯度下降以及底層優化原語。
Spark GraphX:
GraphX是用於圖計算和並行圖計算的新的(alpha)Spark API。通過引入彈性分散式屬性圖(Resilient Distributed Property Graph),一種頂點和邊都帶有屬性的有向多重圖,擴充套件了Spark RDD。為了支援圖計算,GraphX暴露了一個基礎操作符集合(如subgraph,joinVertices和aggregateMessages)和一個經過優化的Pregel API變體。此外,GraphX還包括一個持續增長的用於簡化圖分析任務的圖演算法和構建器集合。
除了這些庫以外,還有一些其他的庫,如BlinkDB和Tachyon。
BlinkDB是一個近似查詢引擎,用於在海量資料上執行互動式SQL查詢。BlinkDB可以通過犧牲資料精度來提升查詢響應時間。通過在資料樣本上執行查詢並展示包含有意義的錯誤線註解的結果,操作大資料集合。
Tachyon
此外,還有一些用於與其他產品整合的介面卡,如Cassandra(Spark Cassandra 聯結器)和R(SparkR)。Cassandra Connector可用於訪問儲存在Cassandra資料庫中的資料並在這些資料上執行資料分析。
spark的生態系統如下圖: