
Coursera_機器學習_week6_機器學習應用建議
52nlp的筆記
如何調演算法,可能的措施包括
- 獲取更多的訓練樣本
- 增加/減少特徵 or 引入多項式特徵
增加 /減小 λ
對於原始的資料集,一種比較典型的劃分方式是60%的訓練集(training set),20%的交叉驗證集(cross validation set/cv set),以及20%的測試集(test set):
Diagnosing bias vs. variance(診斷偏差和方差)
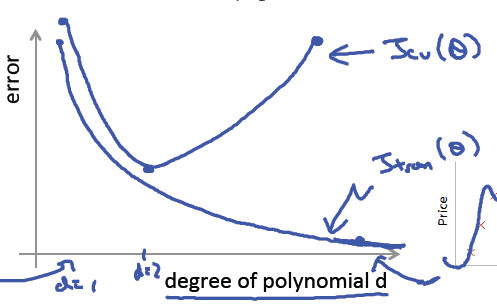
其中d為迭代次數
1)欠擬合underfitting = 高偏差 high bias
這時候可以 減小λ,增加特徵數,引入多項式特徵,但是擴充資料集不管用
2)過擬合 overfitting = 高方差 high variance
這時候可以增加λ、減小特徵數、擴充資料集
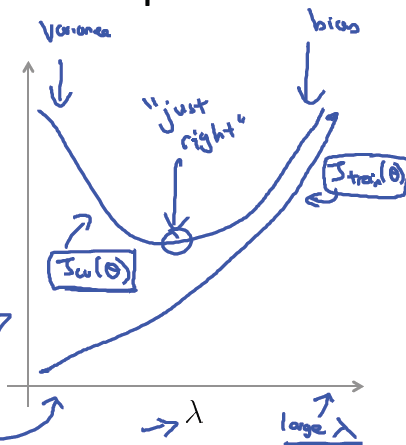
Regularization and bias/variance(正則化和偏差/方差)
那麼,如何選擇正則化引數 λ ?
對於資料集,我們仍將它劃為3份:訓練集,驗證集,測試集。對於給定的正則化模型,例如上面的例子,我們按 λ 從小到大的順序依次取數,然後在訓練集上學習模型引數,在交叉驗證集上計算驗證集誤差,並選擇誤差最小的模型, 也就是選擇 λ,最後再在測試集上評估假設。
Learning curves(學習曲線)
考察trainning set 大小 和error 大小的關係
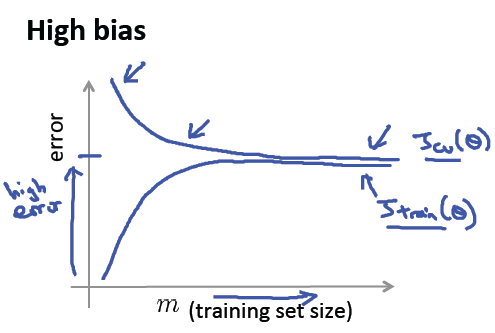
1)欠擬合的情況下 兩個曲線很快變平 然後 非常靠近,而且最後收斂的位置error的值仍然很高
這種情況下,擴充訓練集合 沒用
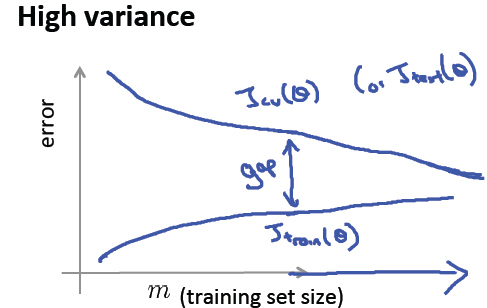
2)過擬合的情況下 兩個曲線之間會有很大的gap 不會互相靠近;但是訓練集變大 gap會變小
這種情況下 ,擴充訓練集合 有用
Note:
1)不是任何時候,獲取更多資料都是有用的
2) 嘗試人工分析那些在cv set裡面出錯的樣本,分析錯誤原因
skewed data 偏斜資料集
正負樣本的比例 差太多 這種情況就叫做 skewed data
比如檢測癌症的演算法的資料集中,得癌症的(正樣本)只有0.5%
這時候accuracy並不能很好的檢測演算法的優劣(全部判定負都能獲得99.5%的準確率)
precision /recall
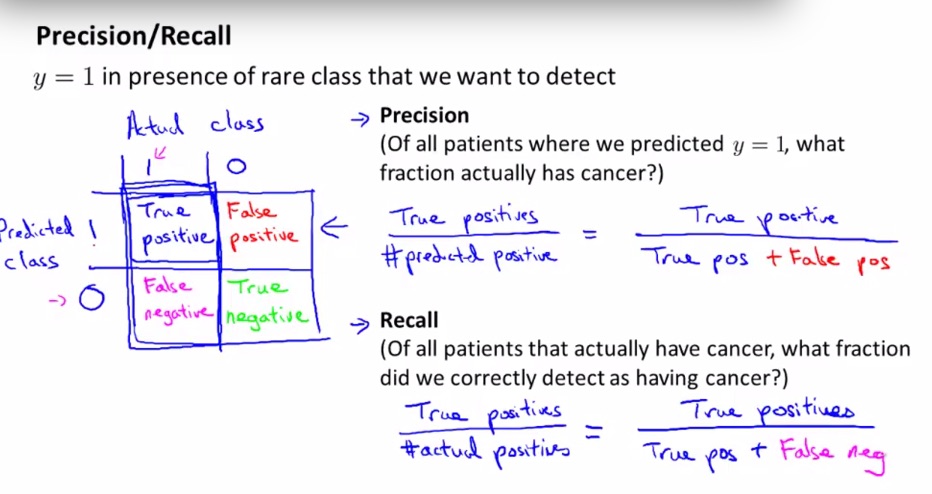
準確率precision=
召回率recall =
在邏輯迴歸問題中,如何根據precision和recall選擇我們的threshold

如果我們希望在非常確定的情況才認定樣本為正(非常確定才告訴你有癌症)
那麼選擇高precision,低recall
如果我們希望不要丟失太多癌症的案例(醫療科研人員)
那麼選擇高recall,低precision
F1 Score
不知道在precision和recall之間如何取捨,可以使用F1 Score 綜合precision和recall來選擇threshold
使用大資料集
通常我們會同時測試多種演算法,選擇效能最好的
很多演算法的效能類似,通常只要給更多的資料,各種演算法的效果都會變好
所以俗語有云,得資料者得天下