
機器學習機的一般應用流程
1. 問題抽象化
問題抽象化是指,將問題對映為機器學習能夠解決的類別。
2. 資料採集
3. 資料預處理及特徵提取
4. 模型構建
5. 模型驗證
6. 效果評估
將機器學習應用到網路安全已成為近年來安全領域的研究熱點。針對安全領域的5個研究方向(指網路空間安全基礎、密碼學及其應用、系統安全、網路安全、應用安全),機器學習在系統安全、網路安全、應用安全三個方向有大量的研究成果,而在網路安全基礎和密碼學及其應用方面的研究較少涉及。其中,系統安全以晶片、系統硬體物理環境及系統軟體為研究方向;網路安全主要以網路基礎設施、網路安全監測為研究重點;應用層面則關注應用軟體安全、社會網路安全。
從機器學習應用於網路安全的角度出發,下圖右側所示是機器學習在網路安全中的一般應用流程,左側則是上述3個主要研究方向的典型應用。
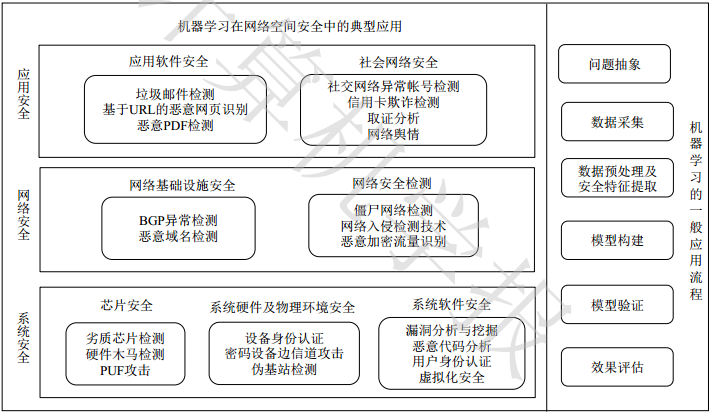
機器學習被認為是一組能夠利用經驗資料來改善系統自身效能的演算法集合,它包括分類、聚類、降維等問題,它在安全研究中的一般應用流程包括這六個階段:安全問題抽象--》資料採集--》資料預處理--》安全特徵提取--》模型構建--》模型驗證--》模型效果評估。
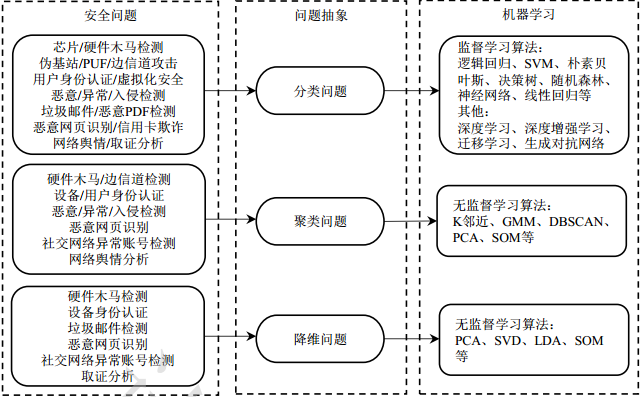
安全問題抽象化
安全問題抽象是指將網路空間安全問題對映為機器學習能夠解決的類別,問題對映的恰當與否直接關係到機器學習技術解決網路空間安全問題成功與否。比如,對劣質晶片或硬體木馬的檢測、偽基站檢測、虛擬化安全、信用卡欺詐等都可以抽象為分類問題;裝置身份認證、社交網路異常賬號檢測、網路入侵檢測等可以抽象為聚類問題;使用者身份認證、惡意/異常/入侵檢測、取證分析、網路輿情等問題既可以抽象為分類問題也可以抽象為聚類問題。
資料採集
資料採集是機器學習應用於網路空間安全的前提條件,它主要利用各種軟體(比如wireshark、Netflow、日誌收集工具等),主要從系統層、網路層及應用層採集資料,系統層資料用於系統安全問題的與研究,這類資料主要有晶片資訊、裝置資訊、系統日誌資訊等。網路層資料指與具體網路活動密切相關的資料,目前常用的是網路包資料或者網路流資料。應用層資料指網路空間中的各類應用軟體產生及儲存的資料,如web日誌資訊、使用者個人資訊。
資料預處理及特徵提取
在真實網路環境中,採集的資料可能有大量的缺失值、噪音也可能由於人工錄入失誤而產生異常點,因此需要對資料進行清洗以及歸一化處理。(比如,從企業內部採集的TCP流資料,首先需要剔除重複資料、去除噪音等規範化操作,然後對清洗的資料進行聚合、歸一化處理等操作)
如果採集的資料集中某個特徵缺失值較多,通常會將該特徵捨棄,否則可能會產生較大的噪聲,影響機器學習模型的效果。如果缺失值較少,可以採用固定值填充、均值填充、中位數填充、插值法或者隨機數填充等方法。如果存在異常值則直接將該條資料刪除。在一些安全問題中國,有時候異常資料樣本或惡意資料樣本遠遠少於正常樣本,對於這種非平衡資料集,通常採用過取樣或欠取樣方法構造平衡資料集。(對資料量大的正例採用欠取樣,對資料量小的負例採用過取樣)。
之後,將資料集進行分割,分成三個集合:訓練集、驗證集、測試集。(ps;訓練集和測試集大家應該都瞭解),驗證集主要用於驗證模型及引數調優。常用的資料集分割方法有隨機取樣和交叉驗證。
特徵提取指從資料中提取最具有安全問題本質特性的屬性,比如從惡意網頁的識別中,提取主機資訊特徵、網頁內容特徵、靜態連線及動態網頁行為關係等,不過,這方面,提取特徵雖然比較困難,機器學習中比較火的深度學習可以實現自動提取特徵
模型構建
在機器學習領域,按照資料集是否有標記,將其分為監督學習和無監督學習,對於監督學習,比如說:垃圾郵件檢測中的每條資料標記為“垃圾郵件”或"非垃圾郵件"。在非監督學習中,資料不包含標籤資訊,但可以通過非監督學習演算法推斷出資料的內在關聯,例如社交網路賬號的檢測中對好友關係、點贊行為的聚類,從而發現賬號內在的關聯。近幾年來,深度學習憑藉強大的自動提取特徵的能力,被用於解決異常協議檢測、惡意軟體檢測、網路入侵檢測等方面。另外,深度學習與增強學習相結合的深度增強學習演算法還可以應用於移動終端惡意檢測。
將選定的演算法和訓練資料集用於模型訓練時,往往需要面臨調參的挑戰,這需要依據個人的經驗進行。
模型驗證
模型驗證主要採用K倍交叉驗證法,它將資料預處理後的訓練資料集劃分成k個大小相似且互斥的子集,每個子集儘可能保持資料分佈的一致性,然後用k-1子集的並集作為訓練集,剩餘子集作為驗證集,從而獲得k組訓練資料集和驗證集,可以進行k此訓練和驗證測試,最終返回的結果是這k次驗證測試結果的均值。
模型效果評估
安全領域一般常用的有正確率、查準率、查全率,正確率是分類正確的正常樣本數與惡意樣本數佔樣本總數的比例。查準率(精度)是指被正確識別的正常樣本數佔被識別為正常樣本的比例,查全率(召回率)則是指被正確識別的正常樣本與正確識別的正常樣本和被錯誤識別的惡意樣本之和的比例(簡單說即是被正確識別的正常樣本佔)。公式一般如下:
