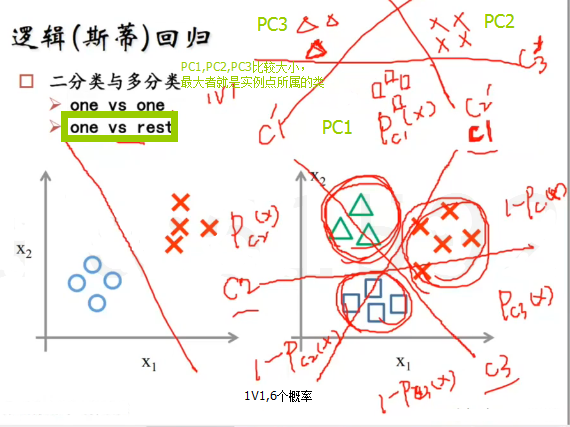
Python機器學習庫sklearn裡利用LR模型進行三分類(多分類)的原理
阿新 • • 發佈:2019-02-05
首先,LR將線性模型利用sigmoid函式進一步做了非線性對映。
將分類超平面兩側的正負樣本點,通過壓縮函式轉化成了以0.5為分解的兩類:類別0和類別1。
這個轉化過程見下圖:
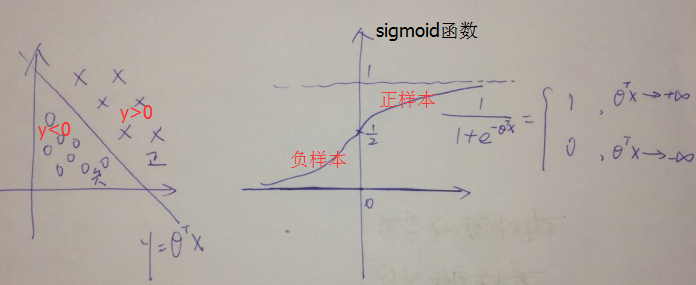
上圖給出的是線性邊界與LR分佈函式(即sigmoid函式)的對映對應關係;同樣,對於非線性判定邊界sigmoid函式也使用,如下圖:

然後,再考慮如何去獲得模型引數,就是判定邊界的引數怎麼獲得,這裡是利用MLE進行求解的,具體求解過程參考本文最初給的理論連結地址。
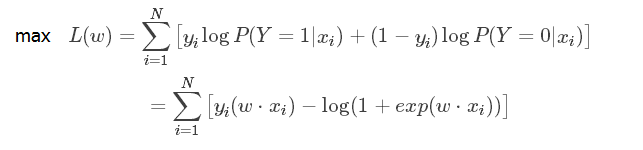
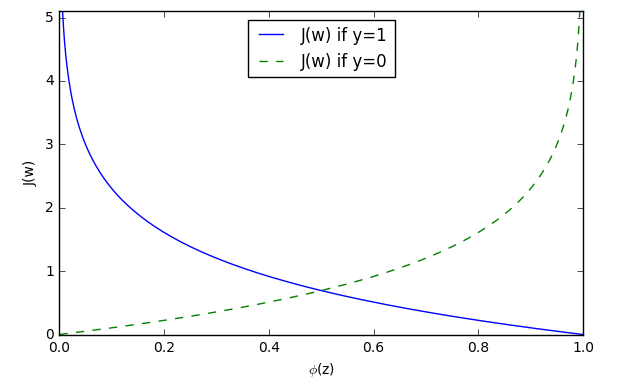
import numpy as np import matplotlib.pyplot as plt def sigmoid(z): return 1.0 / (1.0 + np.exp(-z)) z = np.arange(-7, 7, 0.1) phi_z = sigmoid(z) def cost_1(z): return - np.log(sigmoid(z)) def cost_0(z): return - np.log(1 - sigmoid(z)) #這裡cost_1(z)和cost_0(z)對應上述公式 z = np.arange(-10, 10, 0.1) phi_z = sigmoid(z) c1 = [cost_1(x) for x in z] plt.plot(phi_z, c1, label='J(w) if y=1') c0 = [cost_0(x) for x in z] plt.plot(phi_z, c0, linestyle='--', label='J(w) if y=0') plt.ylim(0.0, 5.1) plt.xlim([0, 1]) plt.xlabel('$\phi$(z)') plt.ylabel('J(w)') plt.legend(loc='best') plt.tight_layout() # plt.savefig('./figures/log_cost.png', dpi=300) plt.show()
最後,考慮LR進行三分類(多分類)時,是特徵的線性組合和sigmoid函式複合的函式進行概率計算和分類的。
from IPython.display import Image %matplotlib inline # Added version check for recent scikit-learn 0.18 checks from distutils.version import LooseVersion as Version from sklearn import __version__ as sklearn_version from sklearn import datasets import numpy as np iris = datasets.load_iris() #http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html X = iris.data[:, [2, 3]] y = iris.target #取species列,類別 if Version(sklearn_version) < '0.18': from sklearn.cross_validation import train_test_split else: from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.3, random_state=0) #train_test_split方法分割資料集 from sklearn.preprocessing import StandardScaler sc = StandardScaler() #初始化一個物件sc去對資料集作變換 sc.fit(X_train) #用物件去擬合數據集X_train,並且存下來擬合引數 X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) from sklearn.linear_model import LogisticRegression def sigmoid(z): return 1.0 / (1.0 + np.exp(-z)) lr = LogisticRegression(C=1000.0, random_state=0) #http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression lr.fit(X_train_std, y_train) lr.predict_proba(X_test_std[0, :].reshape(1, -1)) #計算該預測例項點屬於各類的概率 #Output:array([[ 2.05743774e-11, 6.31620264e-02, 9.36837974e-01]]) #驗證predict_proba的作用 c=lr.predict_proba(X_test_std[0, :].reshape(1, -1)) c[0,0]+c[0,1]+c[0,2] #Output:0.99999999999999989 #檢視lr模型的特徵係數 lr = LogisticRegression(C=1000.0, random_state=0) #http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn.linear_model.LogisticRegression lr.fit(X_train_std, y_train) print(lr.coef_) #Output:[[-7.34015187 -6.64685581] # [ 2.54373335 -2.3421979 ] # [ 9.46617627 6.44380858]] #驗證predict_proba工作原理 Zz=np.dot(lr.coef_,X_test_std[0, :].T)+lr.intercept_ np.array(sigmoid(Zz))/sum(np.array(sigmoid(Zz))) #Output:array([ 2.05743774e-11, 6.31620264e-02, 9.36837974e-01]) #此結果就是預測例項點各類的概率