
《TensorFlow學習筆記》對圖片資料的預處理一、-編碼解碼調整大小色彩亮度
IDE:pycharm
Python: Python3.6
OS: win10
tf: 1.5.0
圖片資料的預處理
所謂,預處理就是對訓練圖片提前進行一些處理,為什麼要這麼幹呢??
答案是 為了降低其他無關因素對最後的識別結果的影響,比如說一幅圖片在不同亮度或是對比度等指標下呈現的效果可能差別特別大,但是這些對於我們來說,不要影響到最後的識別結果,所以這就是預處理最想解決的東西,其次通過預處理方式也可以讓資料集更加多樣化,隨機化,可以讓model更加健壯。
影象編碼處理
彩色圖片為RGB三個通道,所以可以看成一個三維矩陣,矩陣中的每一個數表示了影象上不同位置,不同顏色的亮度。然而對於圖片的儲存,並非直接儲存這個矩陣,而是對圖片進行編碼之後儲存的
編碼解碼處理程式碼
1.首先展示一下我大歐文
Kyrie_Irving.jpg

有詳細的講解註釋
import matplotlib.pyplot as plt #匯入這個包用來顯示圖片
import tensorflow as tf
#讀取影象的原始影象 這裡可能會出現decode‘utf-8’的error讀用rb就搞定
#讀入的為二進位制流, ./yangmi.jpg 為當前程式資料夾的圖片途徑
#tf.gfile.FastGFile為tf自帶的讀取資料的操作函式
image_raw_data = tf.gfile.FastGFile('./Kyrie_Irving.jpg' 對沒有錯你會發現執行之後出error
這個錯誤的出現在jpeg編碼位置,意思是進行jpeg編碼需要的型別矩陣是uint8型別,而這裡我把這個型別轉換為了float32,所以先不管這個先去掉歸一化操作之後的話我再用這個來操作。
import matplotlib.pyplot as plt
import tensorflow as tf
#讀取影象的原始影象 這裡可能會出現decode‘utf-8’的error 讀用rb就搞定
image_raw_data = tf.gfile.FastGFile('./Kyrie_Irving.jpg', 'rb',).read()
with tf.Session() as sess:
#對圖片進行解碼 二進位制檔案解碼為uint8
img_data = tf.image.decode_jpeg(image_raw_data)
#輸出圖片資料(三維矩陣)
print(img_data.eval())
#利用matplotlib顯示圖片
plt.imshow(img_data.eval())
plt.show()
#圖片按jpeg格式編碼
encode_image = tf.image.encode_jpeg(img_data)
#建立檔案並寫入
with tf.gfile.GFile('./ouwen', 'wb') as f:
f.write(encode_image.eval())
輸出:
三維矩陣
plt顯示的圖片

寫入編碼之後的檔案

開啟的時候選擇image
顯示
小總結
1.這裡是對jpg圖片格式的操作,tf中還有png的操作,這個在編寫程式導包的時候很容易找到
2.儲存jpg圖片的時候需要把圖片轉換成uint8型別
對圖片預處理操作
圖片大小調整
一般資料集都是不整齊的,如果自己準備資料集可能還是通過爬蟲搞定的
所以一般來講圖片的尺寸是大小不一的,但是神經網路的輸入節點的個數是固定的,所以在圖片預處理階段應該需要對圖片統一大小的操作
import matplotlib.pyplot as plt
import tensorflow as tf
#讀取影象的原始影象 這裡可能會出現decode‘utf-8’的error 讀用rb就搞定
image_raw_data = tf.gfile.FastGFile('./Kyrie_Irving.jpg', 'rb',).read()
with tf.Session() as sess:
#對圖片進行解碼 二進位制檔案解碼為uint8
img_data = tf.image.decode_jpeg(image_raw_data)
#利用matplotlib顯示圖片
plt.imshow(img_data.eval())
plt.show()
################ 主要程式
#將圖片轉換為 float32型別 相當於歸一化
#這樣方便對影象資料進行處理
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
#重新大小 第二個引數和第二個引數都為調整後的影象的大小 method 是調整影象大小的方法
resizd = tf.image.resize_images(img_data, [200, 200], method=0)
plt.imshow(resizd.eval())
plt.show()
img_data = tf.image.convert_image_dtype(resizd, dtype=tf.uint8)
###########################
#圖片按jpeg格式編碼
encode_image = tf.image.encode_jpeg(img_data)
#建立檔案並寫入
with tf.gfile.GFile('./ouwen', 'wb') as f:
f.write(encode_image.eval())
結果

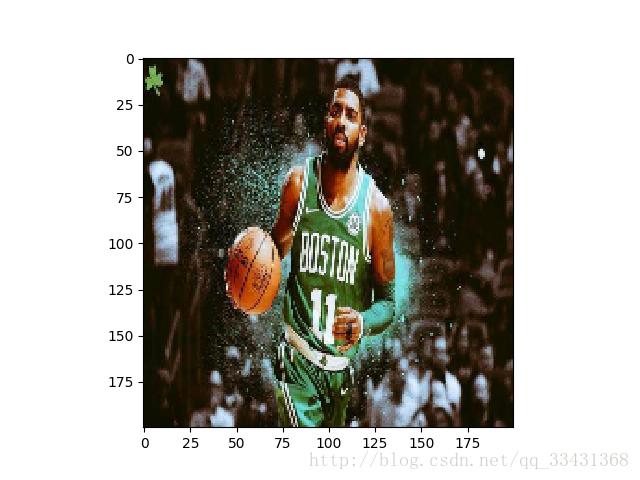
大致程式在***********兩行這個之間
但是其實最主要的就是兩句話
#這樣方便對影象資料進行處理
img_data = tf.image.convert_image_dtype(img_data, dtype=tf.float32)
#重新大小 第二個引數和第二個引數都為調整後的影象的大小 method 是調整影象大小的方法
resizd = tf.image.resize_images(img_data, [200, 200], method=0)如果這裡不對圖片進行重新編碼並且儲存的話也不需要再把三維矩陣的值轉換為uint8了
在以下的程式中我就省略這麼完整的程式了,直接講圖片處理的函式
比如這裡的
resizd = tf.image.resize_images(img_data, [200, 200], method=0)
method如上圖所示,如果你學過數字影象處理,你應該不陌生,但這裡不多講了
影象剪裁或是填充
這裡多說一句:其實這些函式都是英語單詞的_的連線形式還是很好記的
#引數: 輸入圖片資料, 改變尺寸
crop = tf.image.resize_image_with_crop_or_pad(img_data, 100, 100)
pad = tf.image.resize_image_with_crop_or_pad(img_data, 800, 800)crop:

pad:
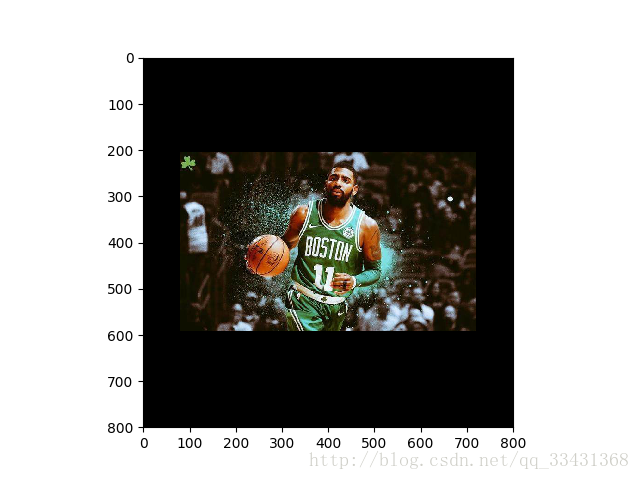
可以看出來如果尺寸大於原圖的話周圍都自動被填充成黑色
還可以通過比例進行調整影象的大小
第二個引數為比例大小0-1之間的數字
central = tf.image.central_crop(img_data, 0.5)結果為

影象翻轉
updown = tf.image.flip_up_down(img_data) #上下映象
leftright = tf.image.flip_left_right(img_data)#左右映象
transpose = tf.image.transpose_image(img_data)#對角映象從程式碼函式的意思也很容易就理解
updown:

leftright :

transpose :
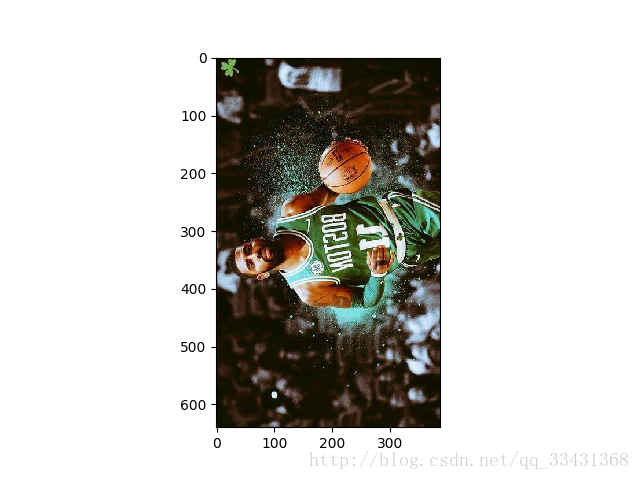
小總結
在很多影象識別問題中,影象的翻轉一般不會影響識別的結果。於是在訓練模型時採用隨機翻轉訓練影象,這樣訓練出的模型可以更好的識別不同角度的實體。
舉一個很極端的例子,如果訓練樣本的目標都在左側,最後訓練出來的model可能就無法很好的識別目標在右側的圖片,所以隨機的翻轉照片可以價效比很高的在很大程度上緩解這個問題,這一方式也是很常見的。
updown = tf.image.random_flip_up_down(img_data) #隨機上下映象
leftright = tf.image.random_flip_left_right(img_data)#隨機左右映象圖片色彩調整
亮度調整
birght1 = tf.image.adjust_brightness(img_data, 0.5)
birght2 = tf.image.adjust_brightness(img_data, -0.5)對比度
contrast1 = tf.image.adjust_contrast(img_data, -5)
contrast2 = tf.image.adjust_contrast(img_data, 5)色相
hue = tf.image.adjust_hue(img_data, 0.1)飽和度
saturation1 = tf.image.adjust_saturation(img_data, 1)
saturation2 = tf.image.adjust_saturation(img_data, -1)小總結
和影象翻轉一樣,影象的亮度、對比度、飽和度和色相在很多影象識別應用中都不會影響識別結果。所以和上述的思想一樣也是隨機的來調整影象的這些屬性,從而可以使得訓練得到的模型儘可能小的受這些無關因素的影響,這也是預處理的目標之一
#[-max, max]隨機
brightness= tf.image.random_brightness(img_data, max)
#[lower, upper]隨機
contrast= tf.image.random_contrast(img_data, lower, upper)
#[-max, max]隨機 max最大為0.5
hue = tf.image.random_hue(img_data, max)
##[lower, upper]隨機
saturation = tf.image.random_saturation(img_data, lower, upper)